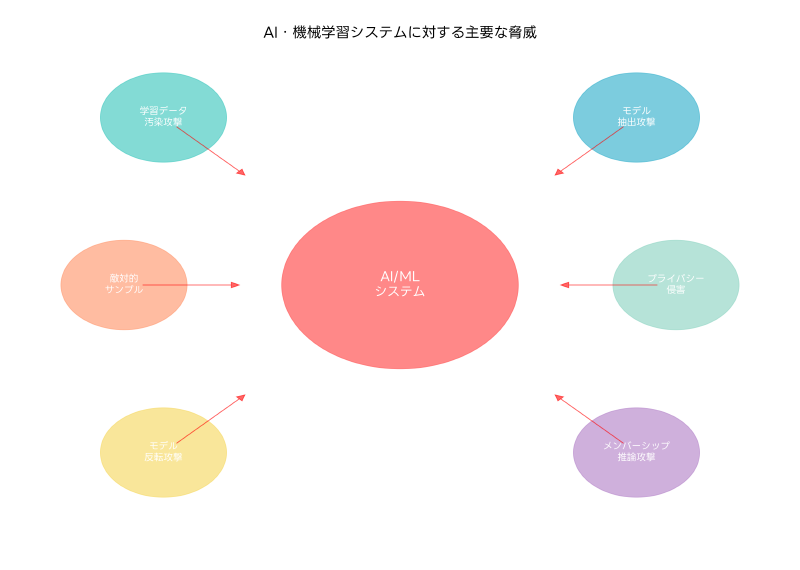
人工知能(AI)と機械学習(ML)技術の急速な普及に伴い、これらの技術を標的とした新しい脅威が次々と現れています。従来のサイバーセキュリティの概念では対応できない独特の脆弱性と攻撃手法が存在し、AI・機械学習システムに特化したセキュリティ対策が急務となっています。応用情報技術者試験においても、AI・機械学習セキュリティは重要な出題分野として注目されており、現代のITプロフェッショナルには欠かせない知識となっています。
AI・機械学習システムのセキュリティは、従来のIT系システムとは大きく異なる特徴を持ちます。データの学習プロセス、モデルの推論過程、そして継続的な学習と更新のサイクル全体にわたって、多様な攻撃ベクトルが存在します。これらの脅威を理解し、適切な対策を講じることは、AI技術を安全に活用するための基盤となります。
敵対的サンプル攻撃:人間には見えない巧妙な罠
敵対的サンプル攻撃は、AI・機械学習システムに対する最も代表的な攻撃手法の一つです。この攻撃では、人間の目には正常に見えるデータに、わずかな変更を加えることで、機械学習モデルに誤った判断をさせることができます。画像認識システムにおいて、パンダの画像にノイズを加えることでテナガザルと誤認識させる例は、この攻撃の典型的な事例として広く知られています。
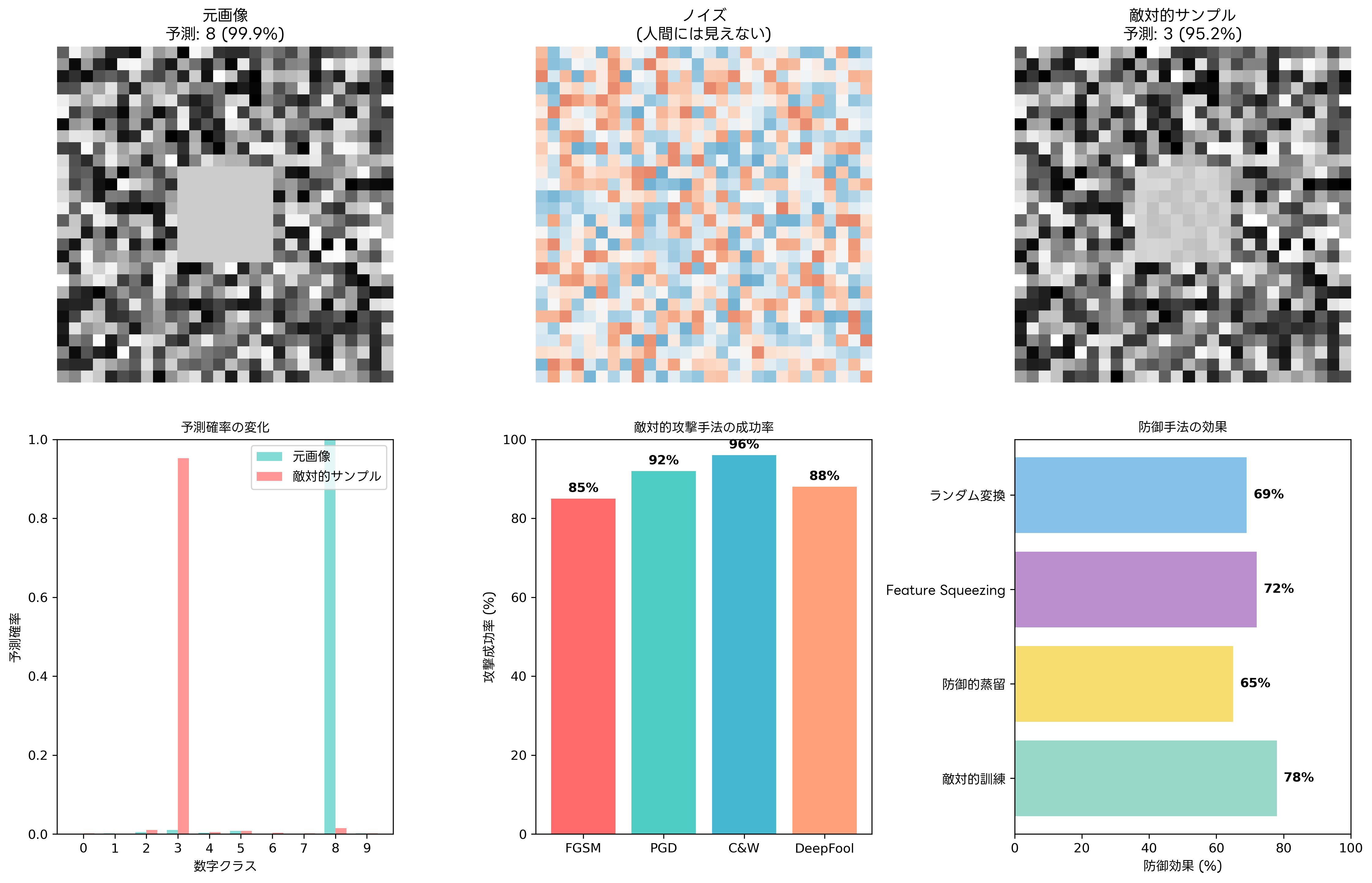
敵対的サンプル攻撃の脅威は、自動運転車の交通標識認識システム、医療診断AIシステム、金融機関の不正検知システムなど、安全性や信頼性が重要な分野で特に深刻です。攻撃者が交通標識に特殊なステッカーを貼ることで、自動運転車に一時停止標識を速度制限標識として誤認識させる実例も報告されています。このような攻撃に対抗するため、高度な画像解析ソフトウェアやAIセキュリティ検証ツールの導入が重要となります。
敵対的訓練は、この種の攻撃に対する最も効果的な防御手法の一つです。訓練データに意図的に敵対的サンプルを含めることで、モデルの頑健性を向上させることができます。しかし、敵対的訓練には計算コストの増加やモデルの汎化性能の低下といったトレードオフが存在するため、高性能なGPUクラスターや分散学習システムの活用により、効率的な学習環境を構築することが重要です。
防御的蒸留、Feature Squeezing、ランダム変換などの手法も敵対的攻撃への対策として研究されています。これらの手法を組み合わせた多層防御アプローチにより、攻撃の成功率を大幅に低下させることが可能です。また、入力データの異常検知システムを導入し、リアルタイム脅威検知ソフトウェアを活用することで、攻撃の早期発見と対応が実現できます。
データ汚染攻撃:学習データの信頼性を脅かす脅威
データ汚染攻撃は、機械学習モデルの学習段階において、悪意のあるデータを学習データセットに混入させることで、モデルの性能を劣化させたり、特定の入力に対して誤った出力を生成させたりする攻撃手法です。この攻撃は、特にクラウドソーシングやWebスクレイピングによってデータを収集するシステムにおいて深刻な脅威となります。
攻撃者は、公開されているデータセットに悪意のあるサンプルを混入させたり、データ収集プロセスに介入したりすることで、学習データの品質を低下させます。例えば、スパムフィルターの学習データに正常なメールとして偽装したスパムメールを混入させることで、将来的にスパムの検知率を低下させることができます。このような攻撃を防ぐため、データ品質管理ツールやデータサニタイゼーションソフトウェアの導入が不可欠です。
データの出所を追跡し、信頼性を確保するためのデータプロヴェナンス管理も重要な対策です。ブロックチェーン技術を活用したデータ来歴管理システムにより、データの改ざんや不正な混入を検出することができます。また、統計的な手法を用いた異常値検出により、学習データ中の不審なサンプルを特定し、除去することも可能です。
学習データの多様性と冗長性を確保することで、データ汚染攻撃の影響を軽減することができます。複数の独立したデータソースから情報を収集し、データ統合プラットフォームを使用してデータの一貫性を検証することが推奨されます。さらに、継続的なモデル性能監視により、学習後のモデルの挙動を監視し、異常な性能低下を早期に検出することも重要です。
モデル抽出攻撃:知的財産の窃取と模倣
モデル抽出攻撃は、機械学習モデルの内部構造やパラメータを推定し、同等の性能を持つ模倣モデルを作成する攻撃手法です。この攻撃により、企業が多大な投資をして開発したAIモデルの知的財産が窃取される可能性があります。攻撃者は、対象モデルに大量のクエリを送信し、その応答を分析することで、モデルの挙動を学習します。
クラウドベースのAIサービスでは、APIを通じてモデルにアクセスできるため、この種の攻撃が特に問題となります。攻撃者は、自動化されたスクリプトを使用して数千から数万のクエリを送信し、応答パターンを分析することで、元のモデルと同等の性能を持つ代替モデルを構築することができます。これを防ぐため、APIレート制限システムやアクセス制御ソリューションの導入が重要です。
クエリの監視と異常検知により、モデル抽出攻撃を検出することができます。短時間内に大量のクエリを送信するアクセスパターンや、系統的な入力パターンを検知することで、攻撃の可能性を特定できます。行動分析システムやユーザー行動監視ツールを活用することで、正常な利用パターンから逸脱したアクセスを検出できます。
出力の摂動や差分プライバシーの適用により、モデルの応答に意図的なノイズを加えることで、攻撃者による正確なモデル推定を困難にすることができます。また、透かし技術やフィンガープリンティング手法を用いて、モデルの一意性を確保し、不正な複製を検出することも可能です。デジタル透かしソフトウェアや知的財産保護ツールの導入により、AIモデルの知的財産を保護することができます。
プライバシー侵害とメンバーシップ推論攻撃
機械学習モデルは、学習データに含まれる個人情報や機密情報を意図せずに記憶し、推論時にその情報を漏洩する可能性があります。メンバーシップ推論攻撃は、特定のデータサンプルがモデルの学習データに含まれていたかどうかを推定する攻撃手法です。この攻撃により、個人の医療記録、金融情報、行動履歴などの機密情報が漏洩するリスクがあります。
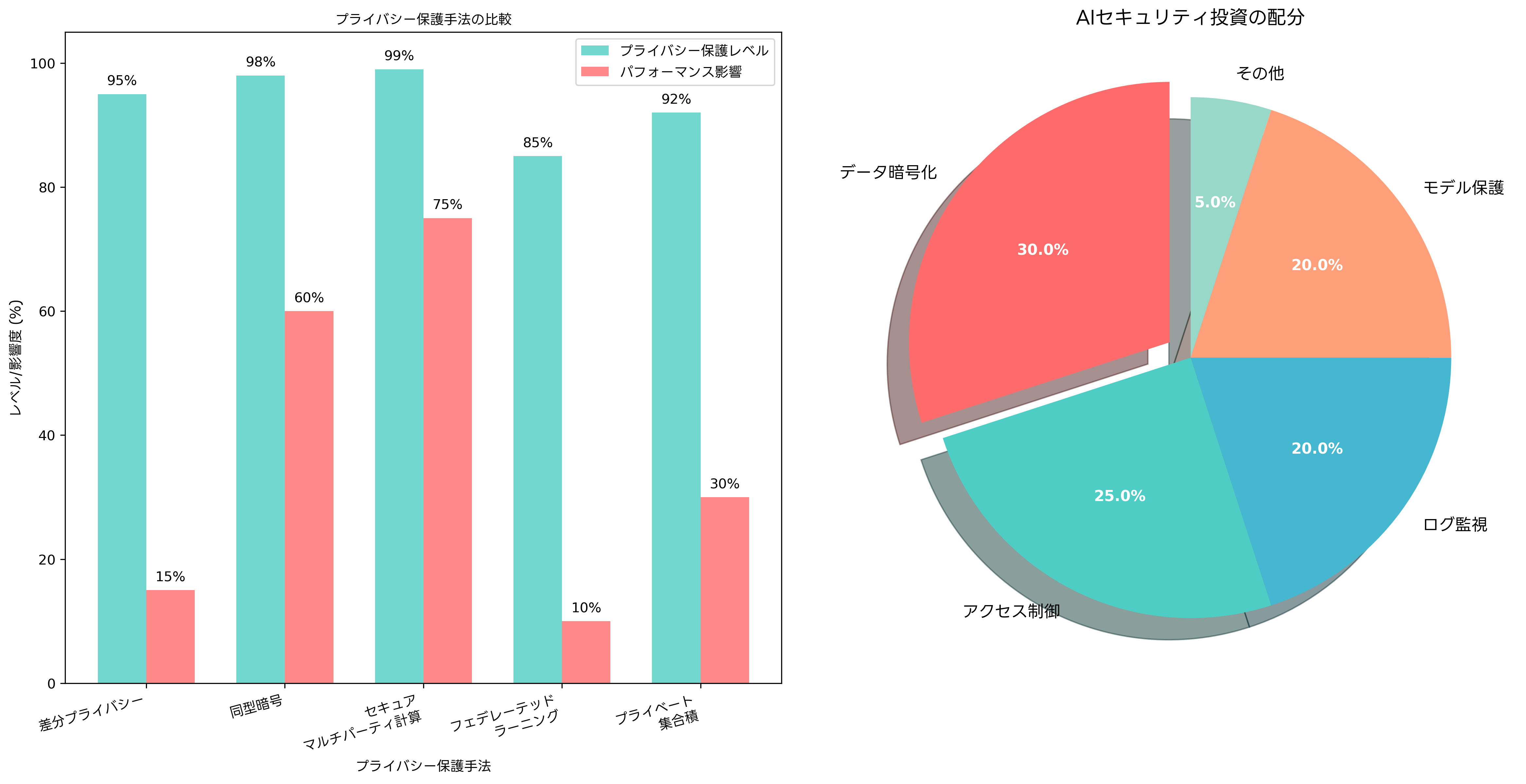
メンバーシップ推論攻撃は、モデルの出力確信度の違いを利用して実行されます。学習データに含まれていたサンプルに対しては、モデルが高い確信度で予測を行う傾向があることを悪用します。医療AIシステムにおいて、患者の診断データがモデルの学習に使用されていたかどうかを推定することで、その患者の病歴を推測することが可能になります。このような攻撃を防ぐため、プライバシー保護機械学習ソフトウェアや差分プライバシーツールの導入が重要です。
差分プライバシーは、プライバシー侵害攻撃に対する最も効果的な防御手法の一つです。学習過程や推論過程にノイズを追加することで、個々のデータサンプルの存在を隠蔽し、プライバシーを保護します。しかし、プライバシー保護レベルとモデル精度の間にはトレードオフが存在するため、適切なパラメータ設定が重要です。
フェデレーテッドラーニングは、データを集中化せずに分散環境で機械学習を実行する手法として、プライバシー保護の観点から注目されています。各参加者がローカルでモデルを学習し、モデルパラメータのみを共有することで、生データの漏洩リスクを大幅に削減できます。フェデレーテッドラーニングプラットフォームや分散学習フレームワークの活用により、プライバシーを保護しながら高性能なAIモデルを構築することが可能です。
同型暗号やセキュアマルチパーティ計算などの暗号学的手法も、プライバシー保護機械学習において重要な役割を果たします。これらの技術により、データを暗号化したまま計算を実行し、プライバシーを完全に保護しながら機械学習を実現できます。ただし、計算コストが高いため、高性能暗号処理システムや専用ハードウェアアクセラレータの利用が推奨されます。
MLOpsセキュリティ:開発から運用まで
機械学習システムの開発・運用プロセス全体にわたるセキュリティ確保が、MLOpsセキュリティの中核概念です。従来のDevOpsセキュリティに加えて、データの品質管理、モデルの妥当性検証、継続的な性能監視など、機械学習特有のセキュリティ要件を満たす必要があります。
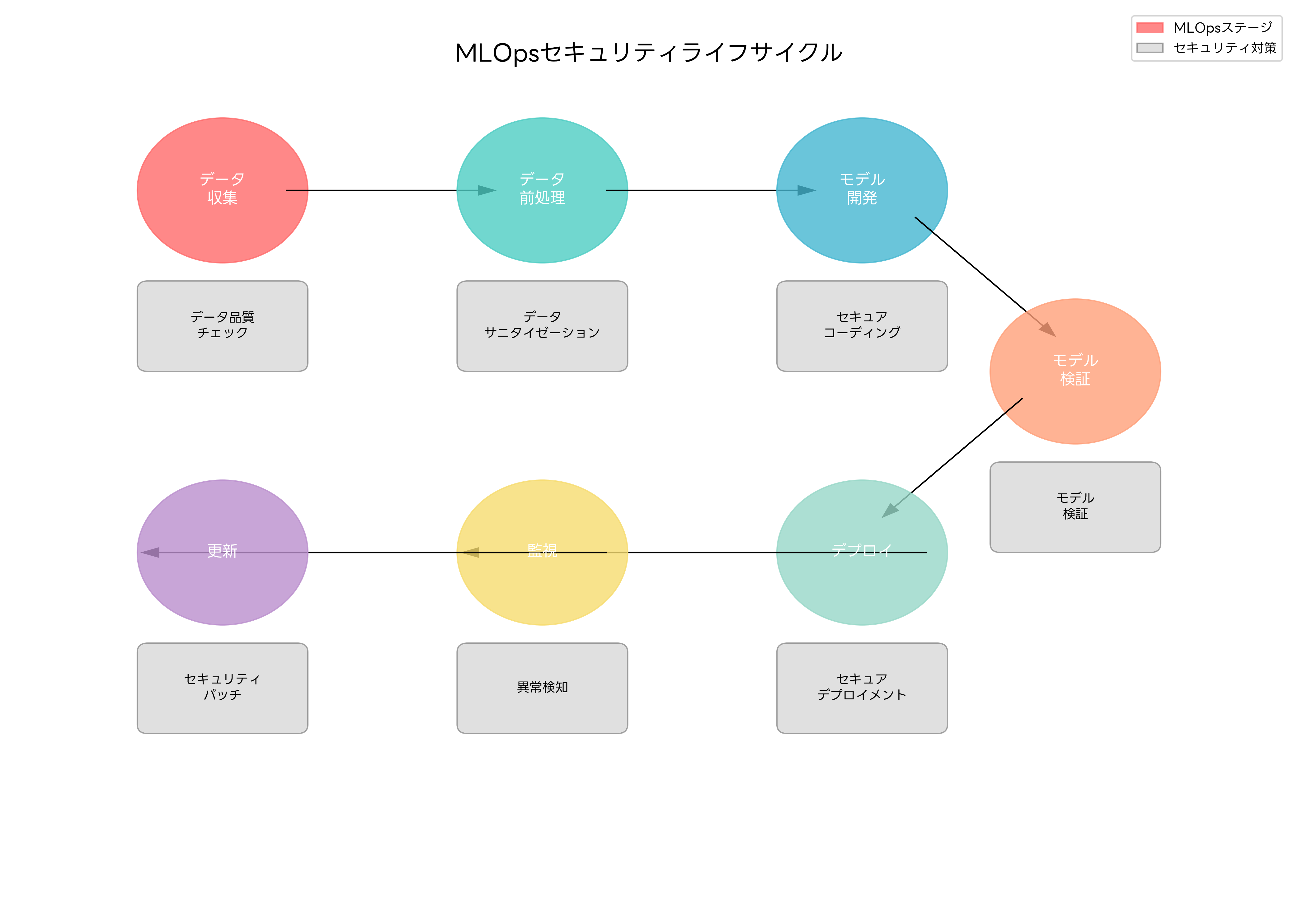
データ収集段階では、データの出所確認、品質検証、プライバシー保護が重要です。データパイプラインにセキュリティチェックポイントを設け、データ系譜管理ツールを使用してデータの流れを追跡します。また、個人情報の自動検出と匿名化を行うデータマスキングソフトウェアの導入により、プライバシーリスクを軽減できます。
モデル開発段階では、セキュアコーディングの実践、依存関係の脆弱性管理、コードレビューの実施が必要です。機械学習ライブラリやフレームワークの脆弱性を定期的にスキャンし、脆弱性管理システムを活用してセキュリティパッチを適用します。また、モデルの学習過程で使用される セキュア開発環境の構築により、開発プロセス全体のセキュリティを確保します。
モデルのデプロイメント段階では、コンテナセキュリティ、APIセキュリティ、アクセス制御の実装が重要です。コンテナセキュリティスキャナーを使用してコンテナイメージの脆弱性を検査し、APIゲートウェイによりAPIアクセスを制御します。また、モデルサービングインフラのセキュリティ監視システムにより、リアルタイムでの脅威検知を実現します。
継続的な監視と更新プロセスでは、モデルの性能劣化検知、ドリフト検出、セキュリティインシデント対応が必要です。機械学習モデルは時間とともに性能が劣化する可能性があるため、MLモニタリングプラットフォームを導入して継続的な性能評価を実施します。また、セキュリティインシデントが発生した場合の迅速な対応を可能にするインシデント対応自動化ツールの導入も重要です。
バイアス検出と公平性の確保
機械学習モデルに潜むバイアスは、セキュリティリスクだけでなく、倫理的・法的な問題も引き起こす可能性があります。学習データに含まれる社会的偏見や歴史的不平等が、モデルの判断に反映されることで、特定のグループに対する差別的な結果を生み出すことがあります。人事採用AIシステムが性別や人種によって異なる評価を行ったり、信用スコアリングシステムが特定の地域の住民を不当に低く評価したりする事例が報告されています。
バイアスの検出には、統計的手法と機械学習技術を組み合わせたアプローチが用いられます。グループ公平性、個人公平性、機会均等性など、様々な公平性指標を用いてモデルの判断結果を評価します。AIバイアス検出ツールや公平性評価ソフトウェアを活用することで、モデルの偏見を客観的に測定し、問題のある箇所を特定できます。
バイアス軽減手法には、前処理、学習中処理、後処理の3つのアプローチがあります。前処理では学習データからバイアスを除去し、学習中処理では公平性制約を組み込んだ学習を行い、後処理では出力結果を調整します。これらの手法を効果的に適用するため、データ前処理ツールや公平性制約学習ライブラリの導入が推奨されます。
説明可能なAI(XAI)技術も、バイアス検出と軽減において重要な役割を果たします。モデルの判断根拠を可視化することで、不適切な特徴量への依存や偏見に基づく判断を発見できます。AI説明可能性ツールやモデル解釈ソフトウェアを活用することで、ステークホルダーに対してAIの判断プロセスを透明化し、信頼性を向上させることができます。
セキュリティ投資とROI分析
AI・機械学習セキュリティへの投資は、技術的な複雑さと高い専門性要求により、従来のサイバーセキュリティ投資よりも高コストになる傾向があります。しかし、AI系システムへの攻撃が成功した場合の被害は甚大であり、適切な投資により長期的なROIを確保することが可能です。
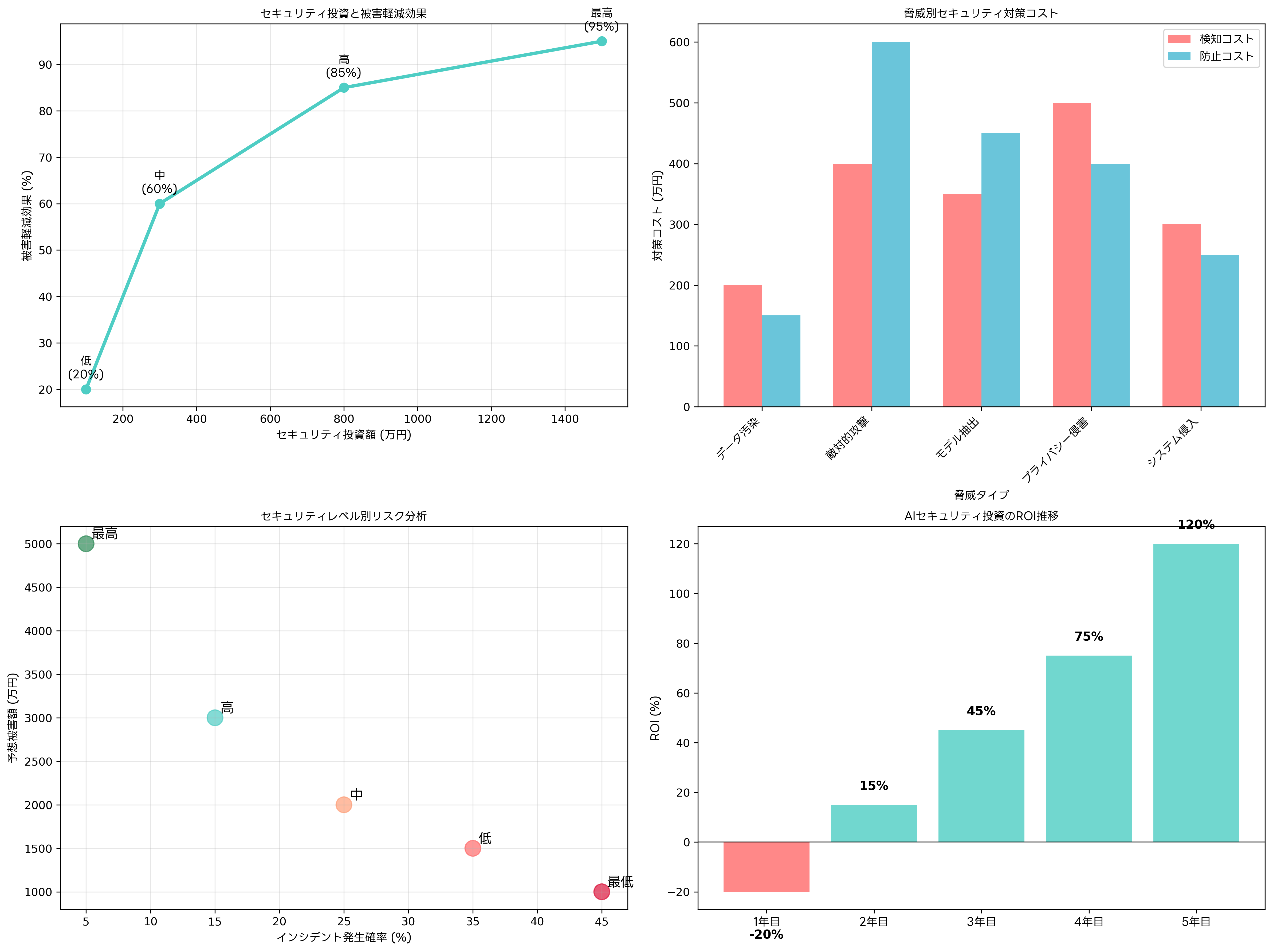
セキュリティ投資の効果測定には、攻撃検知率の向上、インシデント対応時間の短縮、コンプライアンス違反リスクの軽減などの指標が用いられます。初期投資は高額になりがちですが、2年目以降から投資効果が現れ始め、5年間の累積ROIは120%を超える企業も存在します。ROI計算ツールや投資効果分析ソフトウェアを活用することで、セキュリティ投資の定量的評価が可能になります。
脅威インテリジェンスの活用により、投資の優先順位を適切に設定することができます。業界固有の脅威動向や攻撃手法の進化を把握し、最も効果的なセキュリティ対策に投資を集中させることで、限られた予算を最大限に活用できます。脅威インテリジェンスプラットフォームやセキュリティリスク評価サービスの導入により、データ駆動型のセキュリティ投資戦略を策定できます。
人材育成投資も重要な要素です。AI・機械学習セキュリティの専門知識を持つ人材は希少であり、内部での人材育成が長期的なコスト削減につながります。セキュリティ教育プラットフォームやAI セキュリティトレーニングコースを活用することで、既存の従業員のスキルアップを図り、外部委託コストを削減できます。
応用情報技術者試験での出題傾向と対策
応用情報技術者試験においては、AI・機械学習セキュリティに関する問題が急速に増加しています。特に、セキュリティ分野だけでなく、システム開発、データベース、ネットワークの各分野でも、AI技術との関連で出題される傾向があります。
午前問題では、敵対的サンプル攻撃、データ汚染攻撃、プライバシー保護技術に関する基本概念が頻繁に出題されます。例えば、「機械学習モデルに対する攻撃手法のうち、学習データに悪意のあるサンプルを混入させる攻撃はどれか」といった選択問題や、「差分プライバシーの目的として最も適切なものはどれか」といった概念理解を問う問題が見られます。
午後問題では、より実践的な場面でのAI・機械学習セキュリティの応用が問われます。企業のAI導入プロジェクトにおけるセキュリティリスク評価、MLOpsパイプラインのセキュリティ設計、AIシステムのインシデント対応計画策定などの文脈で、包括的な知識と応用力が評価されます。
試験対策としては、理論的な知識の習得と実践的な経験の両方が重要です。AI・機械学習セキュリティの専門書や 応用情報技術者試験のAI関連参考書を活用して基礎知識を固めることが第一歩です。また、AI・機械学習実習環境を構築し、実際に攻撃手法や防御技術を体験することで、深い理解を得ることができます。
最新の脅威動向や技術進歩を継続的に学習することも重要です。AI・機械学習セキュリティは急速に進歩している分野であり、新しい攻撃手法や防御技術が次々と現れています。技術動向レポートやセキュリティ研究論文集を定期的に読むことで、最新の知識を習得し、試験での応用問題に対応できる力を身につけることができます。
新興技術との融合とセキュリティ課題
QuantumML(量子機械学習)の登場により、AI・機械学習セキュリティに新たな次元が加わっています。量子コンピュータの計算能力を活用した機械学習は、従来の暗号化手法を無効化する可能性がある一方で、量子暗号技術による絶対的なセキュリティも実現できる可能性があります。量子コンピューティング開発キットや量子暗号シミュレーターを活用することで、将来の技術動向に備えることができます。
エッジAIの普及により、セキュリティの考え方も大きく変化しています。処理能力とストレージが限られたエッジデバイスにおいて、軽量かつ効果的なセキュリティ対策を実装することが課題となっています。エッジAIセキュリティソリューションやIoTセキュリティプラットフォームの導入により、分散環境でのAIセキュリティを確保できます。
生成AIの急速な普及により、ディープフェイクや偽情報生成などの新たな脅威が出現しています。これらの技術は悪用された場合、社会的な混乱や個人の名誉毀損を引き起こす可能性があります。ディープフェイク検出ツールや偽情報検知システムの開発と導入により、これらの脅威に対抗することが可能です。
国際標準とコンプライアンス
AI・機械学習システムのセキュリティには、国際標準への準拠が重要な要素となっています。ISO/IEC 23053やIEEE 2857などの国際規格により、AIシステムのセキュリティ要件が標準化されています。これらの標準に準拠することで、グローバルな市場での競争力を確保し、顧客や取引先からの信頼を獲得できます。
GDPR、CCPA、個人情報保護法などのプライバシー関連法規制により、AI・機械学習システムにおけるプライバシー保護が法的義務となっています。コンプライアンス管理システムやプライバシー影響評価ツールを活用することで、法規制への確実な対応が可能になります。
業界固有の規制要件も考慮する必要があります。金融業界ではBasel IIIやSolvency II、医療業界ではHIPAAやFDA規制、自動車業界ではISO 26262など、各業界の安全性・信頼性要件を満たすセキュリティ対策が求められます。業界特化型セキュリティソリューションの導入により、業界固有の要件に効率的に対応できます。
まとめ
AI・機械学習セキュリティは、従来のサイバーセキュリティの枠組みを大きく拡張する新しい領域です。敵対的サンプル攻撃、データ汚染攻撃、プライバシー侵害など、AI技術特有の脅威に対応するため、新しい防御戦略と技術的対策が必要となります。応用情報技術者試験においても重要な分野として位置づけられており、IT従事者にとって必須の知識となっています。
技術の急速な進歩とともに、新たな脅威と対策技術が次々と現れているため、継続的な学習と実践が不可欠です。理論的な知識の習得と実務経験の蓄積により、AI・機械学習システムの安全な設計・運用を実現し、デジタル社会の信頼性向上に貢献することができます。組織のAI活用戦略において、セキュリティを最初から組み込んだSecure by Designの考え方を採用し、持続可能で信頼性の高いAIシステムの構築を目指すことが重要です。