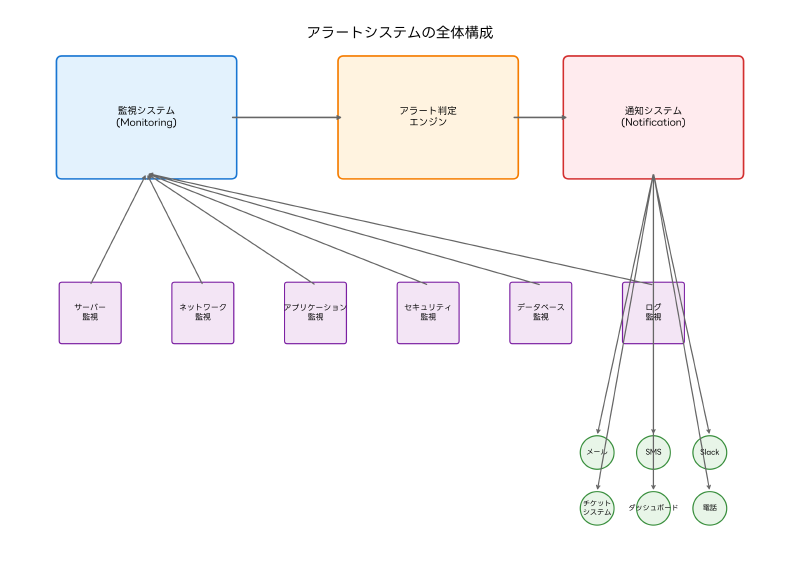
現代のIT環境において、システムの異常や重要なイベントを迅速に検知し、適切な担当者に通知することは、ビジネス継続性を確保するために極めて重要です。アラートシステムは、この役割を果たす中核的なメカニズムであり、応用情報技術者試験においても頻出の重要概念です。効果的なアラート管理は、システムの可用性向上と運用効率の最適化に直結する重要な技術領域です。
アラートとは、システムやアプリケーションが予め設定された条件や閾値を満たした際に、自動的に生成される通知メッセージです。これらの通知は、システム管理者、運用担当者、またはビジネス関係者に対して、迅速な対応が必要な状況を知らせる役割を果たします。適切に設計されたアラートシステムは、問題の早期発見と迅速な対応を可能にし、システムダウンタイムの最小化とサービス品質の維持に貢献します。
アラートシステムの基本アーキテクチャ
アラートシステムは、データ収集、分析処理、判定ロジック、通知配信という一連のプロセスから構成されます。監視対象システムから収集されたメトリクスやログデータは、リアルタイムで分析され、予め設定された条件と照合されます。条件に合致した場合、アラートが生成され、適切な通知チャネルを通じて関係者に配信されます。
データ収集層では、サーバーリソース、ネットワーク通信、アプリケーション性能、セキュリティイベントなど、多様な監視データが継続的に収集されます。この段階では、高性能な監視エージェントやネットワーク監視ツールが重要な役割を果たします。
分析処理層では、収集されたデータが解析され、異常パターンの検出や傾向分析が実行されます。機械学習アルゴリズムを活用したAIベースの異常検知システムにより、従来の固定閾値では検出困難な複雑な異常パターンも識別できるようになりました。
判定ロジック層では、分析結果に基づいてアラートの生成可否が決定されます。ここでは、誤検知の削減とアラート疲労の防止を目的として、相関分析、時間窓統合、重複除去などの高度な処理が実行されます。これらの機能を提供する統合監視プラットフォームの導入により、効率的なアラート管理が実現できます。
通知配信層では、生成されたアラートが適切な担当者や システムに配信されます。電子メール、SMS、チャットツール統合、チケットシステム連携など、多様な通知手段が利用されます。緊急度に応じた段階的エスカレーションや、オンコール体制との連携も重要な機能です。
アラートの分類と優先度管理
効果的なアラート管理には、適切な分類と優先度設定が不可欠です。一般的に、アラートはその重要度に基づいてCritical、Warning、Info、Debugの4段階に分類されます。各レベルは、対応の緊急度、影響範囲、必要なアクションが異なるため、明確な定義と運用ルールの確立が重要です。
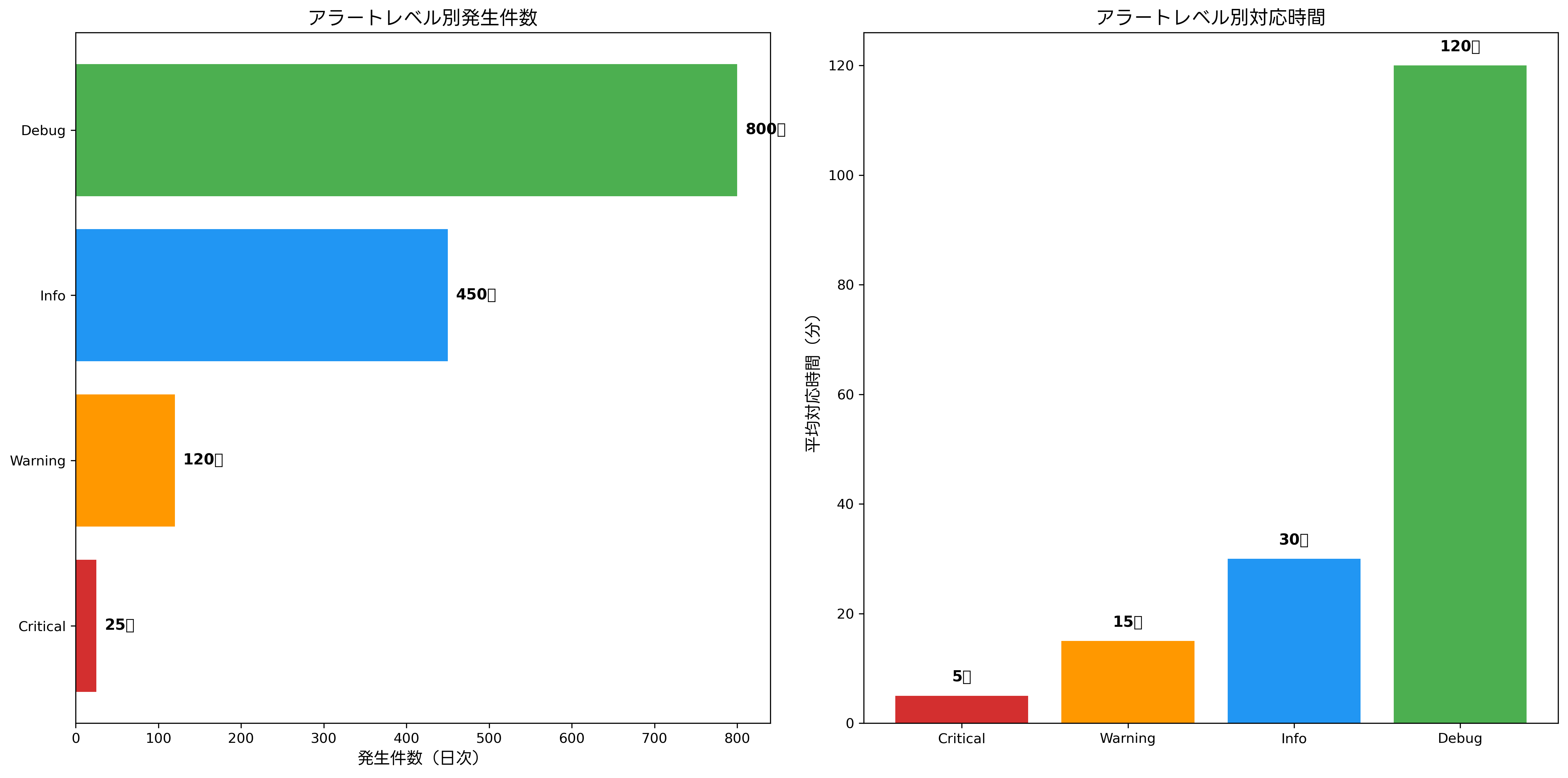
Criticalアラートは、サービス停止や重大なセキュリティ侵害など、即座に対応が必要な状況を示します。これらのアラートは、24時間365日の監視体制下で、数分以内の対応が求められます。対応体制の構築には、オンコール管理システムや緊急時連絡システムの導入が効果的です。
Warningアラートは、潜在的な問題や性能劣化を示し、予防的な対応が必要な状況を表します。CPU使用率の高止まり、ディスク容量の逼迫、応答時間の延長などが該当します。これらのアラートは、営業時間内での対応が一般的ですが、トレンド分析による将来予測も重要です。
Infoアラートは、システムの状態変化や定期的な報告を目的とした情報提供型の通知です。サービスの開始・停止、定期メンテナンスの完了、バックアップ処理の成功などが含まれます。これらは対応は不要ですが、運用状況の把握と記録保持の観点で価値があります。
Debugアラートは、開発・テスト環境での詳細な動作追跡や問題分析に使用されます。本番環境では通常無効化されますが、問題調査時には有効化して詳細な情報収集に活用されます。
優先度管理では、ビジネスへの影響度と技術的な緊急度を総合的に評価する必要があります。リスク評価マトリックスを活用して定量的な優先度算出を行うことで、一貫した判断基準を確立できます。
アラートの発生パターンと時系列分析
アラートの発生パターンを分析することで、システムの特性理解と予防的対策の策定が可能になります。時間帯、曜日、季節性など、様々な時間軸での分析により、リソース配分の最適化と運用効率の向上が図れます。
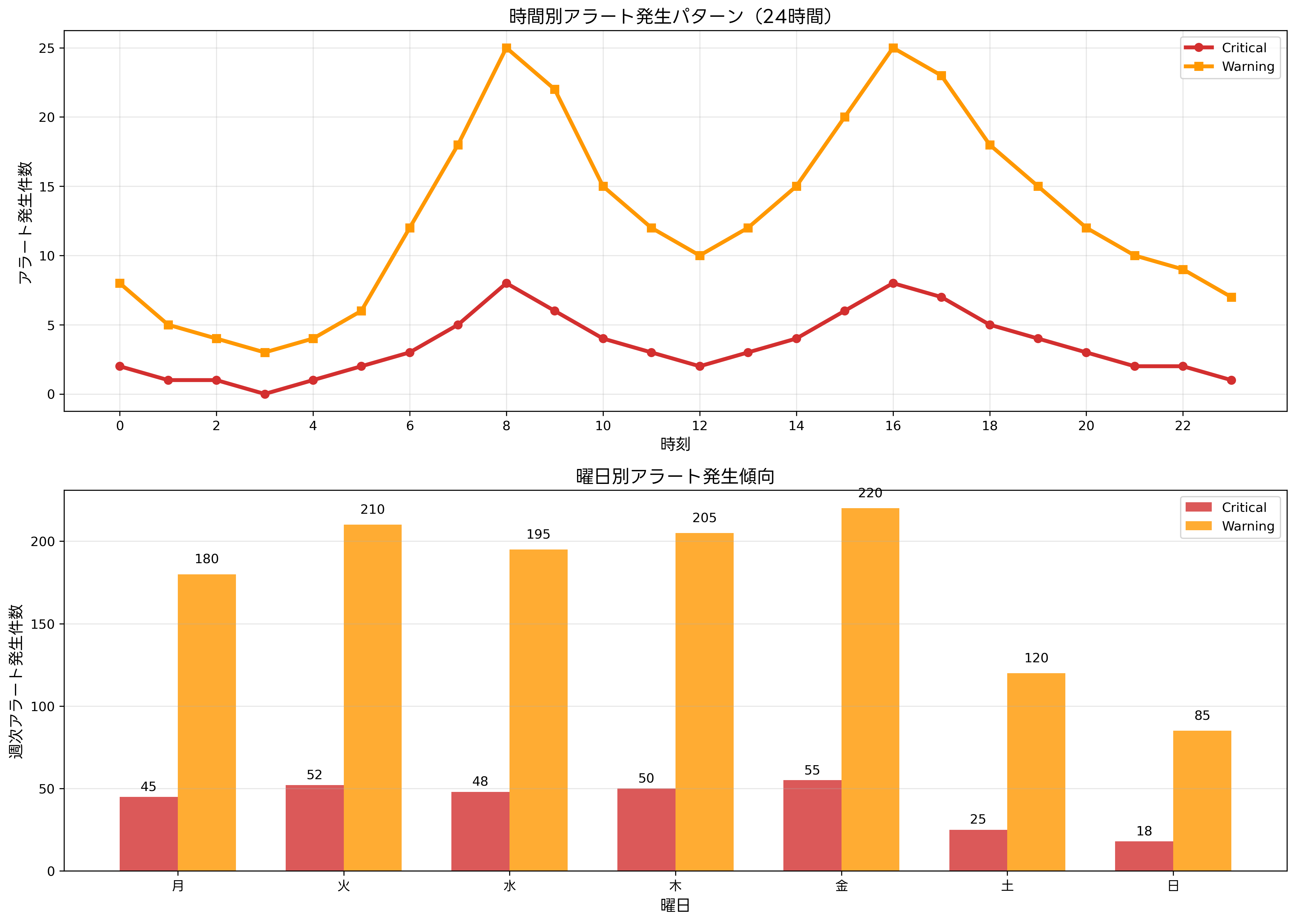
時間帯別の分析では、業務時間中のトラフィック増加、夜間バッチ処理の影響、メンテナンス時間帯の計画停止などが明確に把握できます。これらのパターンを理解することで、予測可能なアラートの抑制や、適切な閾値設定が可能になります。時系列分析ツールを活用することで、統計的に有意なパターンの抽出と将来予測ができます。
曜日別の分析では、平日と休日の利用パターンの違い、週末メンテナンスの影響、月曜日の立ち上がり時の負荷集中などが識別できます。これらの情報は、人員配置計画やシステムリソースの動的調整に活用されます。
季節性分析では、年末年始、決算期、夏季休暇期間など、ビジネスサイクルに連動したシステム負荷変動を把握できます。この分析結果を基に、容量計画管理システムにより、適切なリソース確保と投資計画を策定できます。
相関分析により、複数のアラート間の関連性を特定することも重要です。ネットワーク障害に起因する複数サーバーのアラート、データベース負荷上昇によるアプリケーション応答遅延など、根本原因を特定してアラートストームの防止と効率的な問題解決が可能になります。
アラート処理フローの設計と自動化
効率的なアラート処理には、明確なフローの定義と適切な自動化が不可欠です。アラート受信から問題解決まで一連のプロセスを標準化することで、対応品質の向上と処理時間の短縮が実現できます。
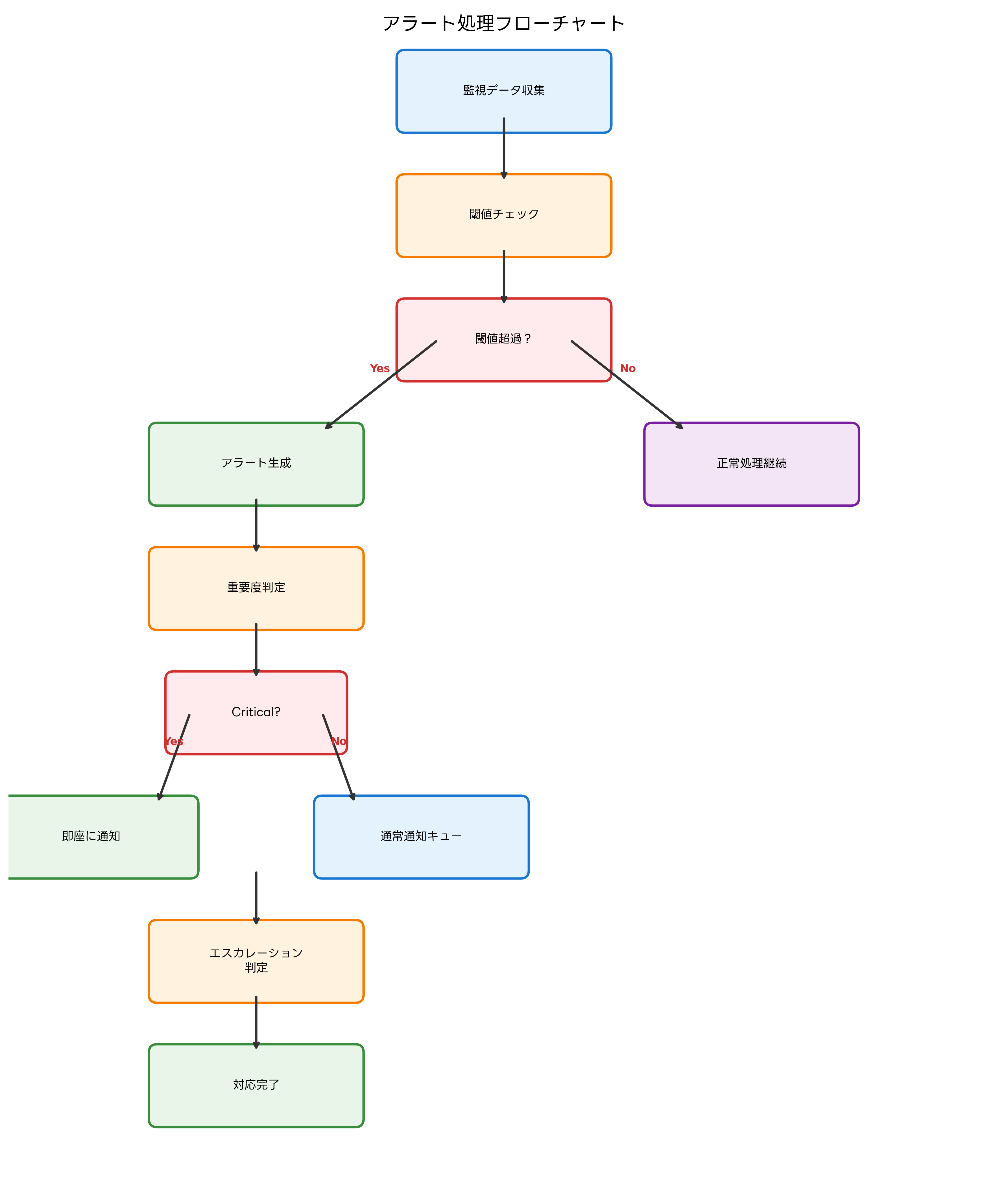
初期対応フェーズでは、アラートの受信確認、影響範囲の評価、初期調査の実施が行われます。このフェーズの自動化により、インシデント管理システムへの自動チケット生成、関連情報の自動収集、担当者への自動通知が実現できます。
調査・診断フェーズでは、問題の根本原因特定と影響範囲の詳細分析が実施されます。ログ分析ツールや性能監視ダッシュボードとの連携により、効率的な問題分析が可能になります。
対応・復旧フェーズでは、問題解決のためのアクション実行と効果確認が行われます。定型的な対応については、自動復旧システムにより無人での問題解決が可能です。サービス再起動、リソース追加、フェイルオーバー実行などが自動化の対象となります。
事後処理フェーズでは、対応記録の作成、根本原因分析、再発防止策の検討が実施されます。ナレッジ管理システムとの連携により、対応ノウハウの蓄積と共有が効率化されます。
エスカレーション管理では、対応期限の監視と段階的な担当者変更が自動実行されます。Criticalアラートの未対応時間監視、管理職への自動報告、外部ベンダーへの連携など、組織構造に応じた柔軟なエスカレーションルールの設定が重要です。
アラート疲労の問題と対策
アラート疲労(Alert Fatigue)は、過剰なアラートにより運用担当者の注意力が低下し、重要なアラートを見落とすリスクが高まる現象です。この問題は、現代のIT運用において深刻な課題となっており、効果的な対策の実施が急務となっています。
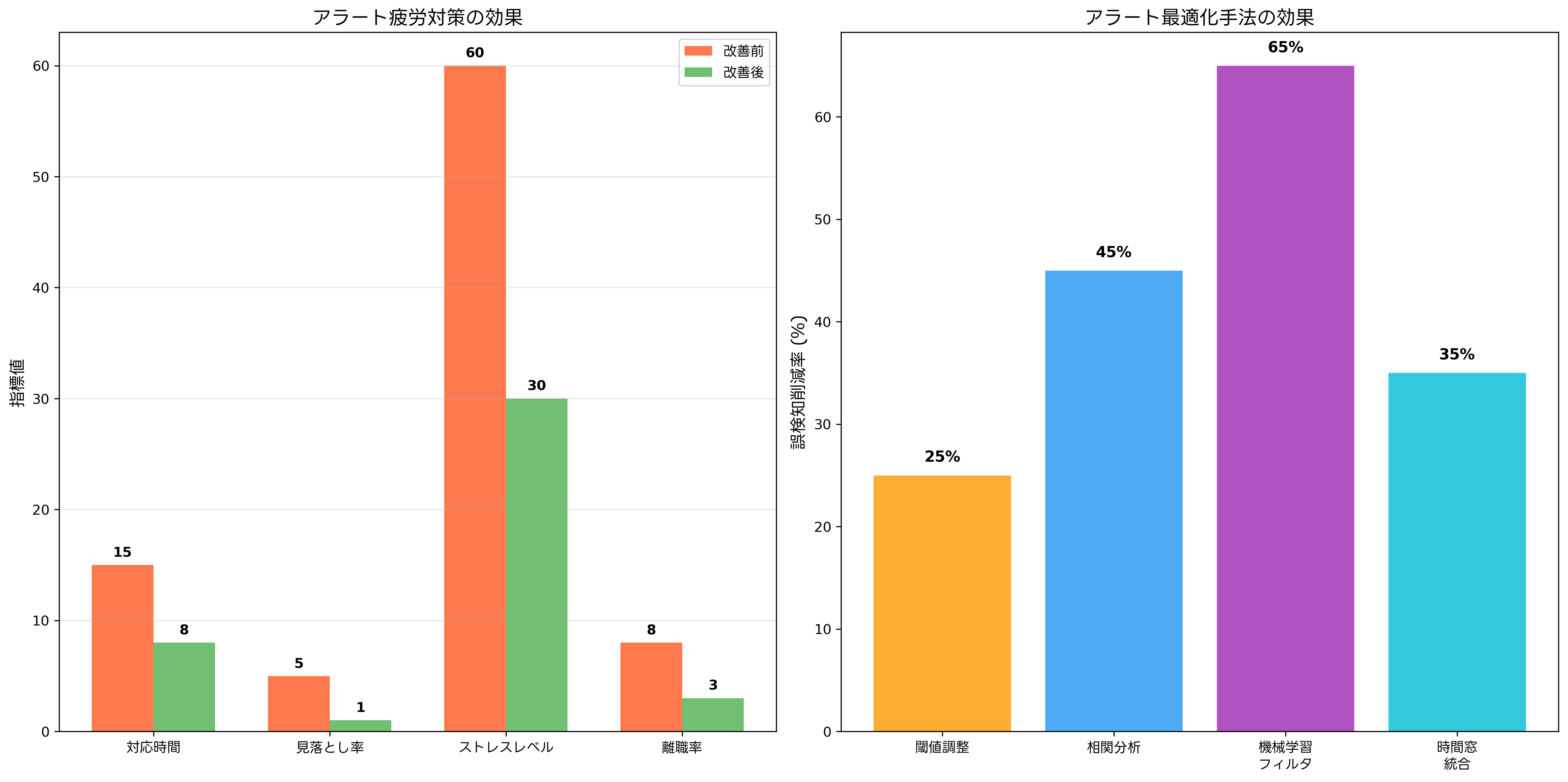
誤検知の削減は、アラート疲労対策の最も重要な要素です。閾値の動的調整、季節性を考慮した基準値設定、機械学習による正常パターン学習など、スマートアラートシステムの導入により大幅な改善が期待できます。
アラート統合(Alert Consolidation)により、関連する複数のアラートを単一の通知にまとめることで、通知量の削減と問題把握の効率化が実現できます。時間窓ベースの統合、相関ルールベースの統合、機械学習による自動クラスタリングなどの手法があります。
重要度の動的調整により、システム状況に応じたアラートレベルの自動変更が可能になります。メンテナンス時間中のアラート抑制、負荷ピーク時の閾値緩和、障害復旧中の関連アラート無効化などが実装できます。
通知チャネルの最適化により、アラートの重要度と受信者の状況に応じた適切な配信方法を選択できます。マルチチャネル通知システムにより、緊急度に応じた段階的エスカレーション、受信者の在席状況に基づく配信先変更、通知の既読確認と再送制御などが実現できます。
心理的負荷の軽減には、適切な作業環境の整備と運用プロセスの改善が必要です。ストレス管理支援システムや疲労度測定ツールを活用して、運用担当者の負荷状況を可視化し、適切な人員配置と休憩スケジュールを確保することが重要です。
機械学習とAIを活用したスマートアラート
近年、機械学習とAI技術の進歩により、従来の固定ルールベースのアラートシステムから、自律学習型のスマートアラートシステムへの移行が進んでいます。これらの技術により、システムの正常動作パターンを自動学習し、異常検知精度の向上と誤検知の大幅削減が実現されています。
異常検知アルゴリズムでは、統計的手法、機械学習手法、深層学習手法が組み合わせて使用されます。時系列データの傾向分析、季節性の自動抽出、多変量相関分析などにより、従来手法では検出困難な微細な異常パターンも識別できます。AI異常検知ソリューションの導入により、検知精度の大幅向上が期待できます。
予測アラート機能では、現在の傾向から将来の問題発生を予測し、事前警告を発出します。CPU使用率の上昇傾向からメモリ不足の予測、ディスク使用量増加からの容量逼迫予測、トランザクション量増加からの性能劣化予測などが可能になります。
自動根本原因分析により、複数のメトリクス間の相関関係から問題の発生源を自動特定できます。ネットワーク遅延の増加とアプリケーション応答時間の相関、データベース負荷とCPU使用率の関係性など、複雑な因果関係を自動解析し、効率的な問題解決を支援します。
コンテキスト認識アラートでは、システムの運用状況、時間帯、イベントスケジュールなどの文脈情報を考慮してアラート判定を実施します。メンテナンス時間中のアラート抑制、営業時間外の閾値調整、特定イベント期間中の負荷上昇許容など、状況に応じた柔軟な判定が可能になります。
クラウド環境でのアラート管理
クラウドコンピューティングの普及により、アラート管理も従来のオンプレミス環境からクラウドネイティブなアプローチへと変化しています。マルチクラウド環境、コンテナオーケストレーション、サーバーレスアーキテクチャなど、新しい技術基盤に対応したアラート戦略が必要です。
クラウドサービスプロバイダが提供するネイティブ監視サービスとの統合により、インフラストラクチャレベルでの包括的な監視が実現できます。クラウド統合監視ソリューションにより、AWS CloudWatch、Azure Monitor、Google Cloud Monitoringなどの各種サービスを統一的に管理できます。
マイクロサービスアーキテクチャでは、サービス間の依存関係と通信パターンを考慮したアラート設計が重要です。分散トレーシング、サービスメッシュ監視、API監視などにより、複雑なサービス構成での問題特定と影響範囲評価が可能になります。
コンテナ環境では、動的なリソース配置とライフサイクル管理に対応したアラート機能が必要です。Kubernetes監視ソリューションにより、Pod、Service、Deployment各レベルでの包括的な監視とアラート管理が実現できます。
サーバーレス環境では、従来のサーバーベース監視とは異なる新しいアプローチが必要です。関数実行時間、エラー率、並行実行数、コールドスタート頻度など、サーバーレス特有のメトリクスに基づくアラート設計が重要です。
セキュリティアラートと脅威検知
サイバーセキュリティの重要性が高まる中、セキュリティ関連のアラートは特に重要な位置を占めています。従来のシステム監視とは異なる観点での脅威検知と迅速な対応が求められます。
SIEM(Security Information and Event Management)システムとの連携により、セキュリティイベントの収集、分析、相関分析が自動化されます。SIEM統合ソリューションにより、ログ分析、脅威インテリジェンス、異常行動検知などの高度なセキュリティ監視が実現できます。
脅威インテリジェンスの活用により、既知の攻撃パターンやIOC(Indicators of Compromise)に基づく自動検知が可能になります。外部脅威情報の自動取り込み、パターンマッチング、リスクスコア算出などにより、プロアクティブな脅威対応が実現されます。
行動分析ベースの異常検知では、ユーザーやシステムの正常な行動パターンを学習し、逸脱行動を自動検知します。権限昇格の試行、異常なファイルアクセス、通常と異なる時間帯でのログイン、大量データのダウンロードなど、内部脅威の検知に特に有効です。
インシデントレスポンスとの連携により、セキュリティアラート発生時の自動対応が実現できます。セキュリティオーケストレーションプラットフォームにより、アカウント無効化、ネットワーク遮断、フォレンジック証拠保全などの自動アクションが実行できます。
アラート管理のベストプラクティス
効果的なアラート管理を実現するためには、技術的な実装だけでなく、組織的なプロセスと継続的な改善活動が重要です。以下に、実証済みのベストプラクティスを紹介します。
アラートポリシーの文書化では、各アラートの定義、発生条件、影響範囲、対応手順を明確に記載します。ITサービス管理システムとの連携により、ポリシーの一元管理と定期的な見直しが効率化されます。
定期的なアラートレビューにより、不要なアラートの削除、閾値の調整、新規監視項目の追加を実施します。月次、四半期のレビューサイクルを設定し、システムの変更やビジネス要件の変化に応じた継続的な最適化を行います。
運用チームの教育とトレーニングでは、アラート対応スキルの向上と標準化を図ります。運用技術者向け教育プラットフォームにより、体系的な知識習得と実践的なスキル向上が可能になります。
メトリクスとKPIの設定により、アラート管理の効果を定量的に評価します。平均検知時間(MTTD)、平均対応時間(MTTR)、誤検知率、アラート対応率などの指標により、継続的な改善活動を推進します。
運用監視ダッシュボードとレポーティング
アラート管理の効果を最大化するためには、適切な可視化とレポーティング機能が不可欠です。リアルタイムでの状況把握と傾向分析により、プロアクティブな運用管理が実現できます。
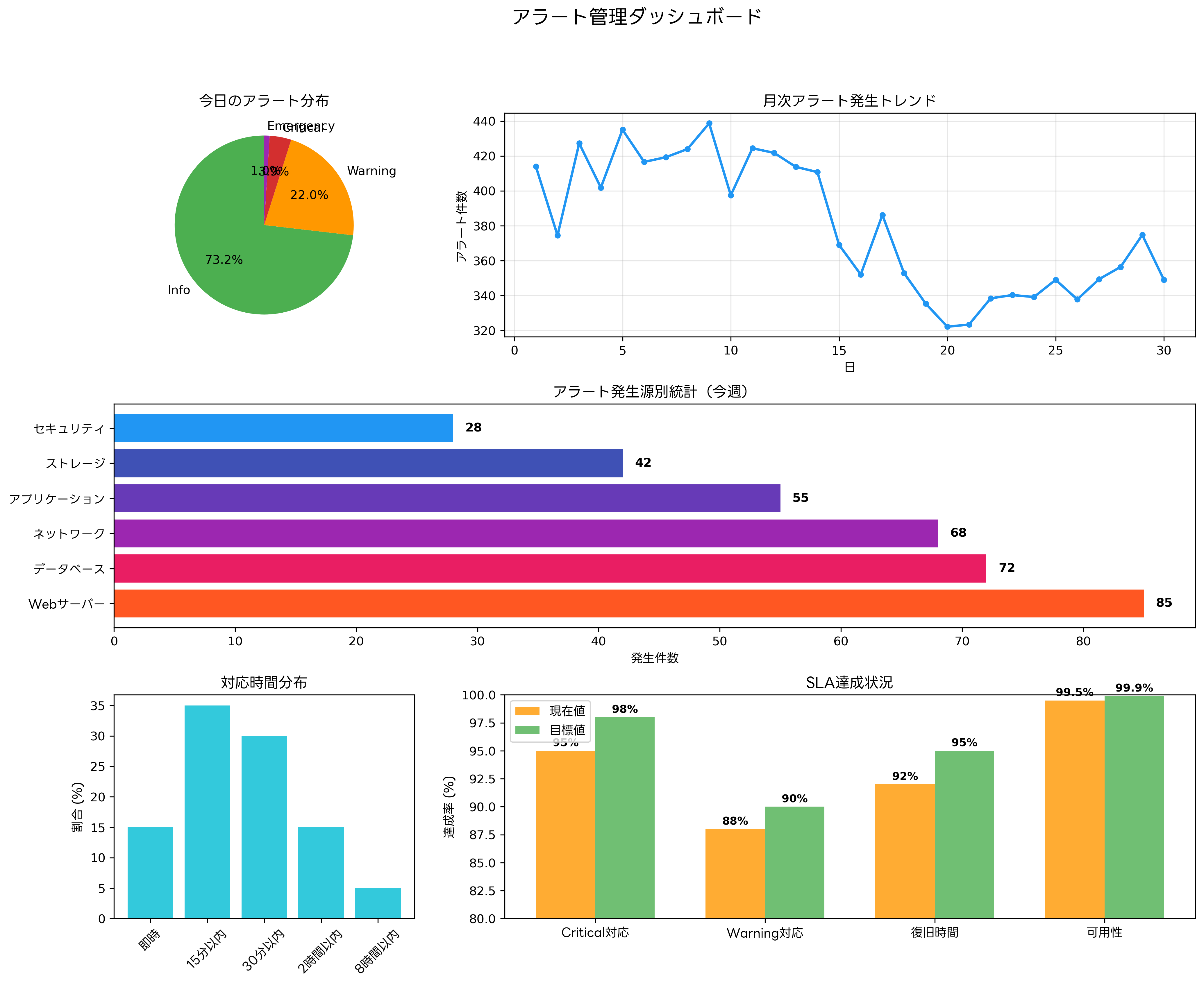
リアルタイムダッシュボードでは、現在のアラート状況、システム健全性、対応状況を一覧表示します。運用監視ダッシュボードツールにより、カスタマイズ可能な表示形式と直感的なユーザーインターフェースが提供されます。
トレンド分析レポートでは、長期的なアラート発生傾向と システム性能の変化を分析します。週次、月次、四半期の定期レポートにより、容量計画、予算策定、人員配置の意思決定を支援します。
SLAダッシュボードでは、サービスレベル目標の達成状況をリアルタイムで監視します。可用性、応答時間、エラー率などの重要指標を可視化し、SLA違反のリスクを事前に検知できます。
管理職向けエグゼクティブダッシュボードでは、ビジネス影響度の高い指標を要約表示します。システム稼働状況、重大インシデント件数、顧客影響時間、運用コストなどの経営指標により、ITサービスの価値とリスクを経営層に報告できます。
応用情報技術者試験での出題傾向と対策
応用情報技術者試験においては、アラート管理に関する問題が システム監視、運用管理、セキュリティ管理の各分野で出題されています。理論的な知識だけでなく、実践的な運用シナリオでの判断力も評価対象となります。
午前問題では、アラートの基本概念、監視項目の選定基準、閾値設定の考え方、通知方法の特徴などが出題されます。特に、SNMP、syslog、ITIL、COBIT等の標準規格や フレームワークとの関連で問われることが多いです。
午後問題では、実際の運用シナリオでのアラート設計、問題分析、改善提案などが出題されます。システム構成図やモニタリング結果を基に、適切なアラート戦略を策定する能力が評価されます。
試験対策としては、応用情報技術者試験対策書籍による基礎知識の習得に加えて、システム運用管理の実践書による実務的な理解を深めることが重要です。
また、監視ツールの操作演習や仮想環境での実習教材を活用して、実践的なスキルを身につけることで、午後問題での応用力向上が期待できます。
今後の技術動向と発展方向
アラート技術は、AI/ML、IoT、エッジコンピューティングなどの新技術と融合しながら進化し続けています。今後の発展方向を理解することで、将来を見据えた技術戦略の策定が可能になります。
自律的運用(AIOps)の発展により、アラート生成から問題解決まで自動実行するシステムが実現されつつあります。AIOpsプラットフォームにより、人的介入を最小限に抑えた運用自動化が可能になります。
エッジコンピューティング環境では、分散型アラート処理とリアルタイム意思決定が重要になります。エッジ監視ソリューションにより、ネットワーク遅延に影響されない高速なアラート処理が実現されます。
IoTデバイスの大規模展開に伴い、従来のスケールを超えたアラート管理が必要になります。軽量プロトコル、省電力通信、階層型集約などの技術により、効率的な大規模IoT監視が可能になります。
まとめ
アラートシステムは、現代のIT運用における要となる技術基盤です。効果的なアラート管理により、システムの信頼性向上、運用効率の最適化、ビジネス継続性の確保が実現できます。応用情報技術者として、理論的な理解と実践的なスキルの両方を身につけることで、高品質なITサービスの提供に貢献できます。
技術の進歩とともに、アラート システムも進化し続けています。AI/ML、クラウドネイティブ、自律運用などの新技術を活用しながら、組織のニーズに適したアラート戦略を策定することが重要です。継続的な学習と実践により、変化する技術環境に適応できる能力を身につけ、価値の高いITサービスを提供し続けることができます。