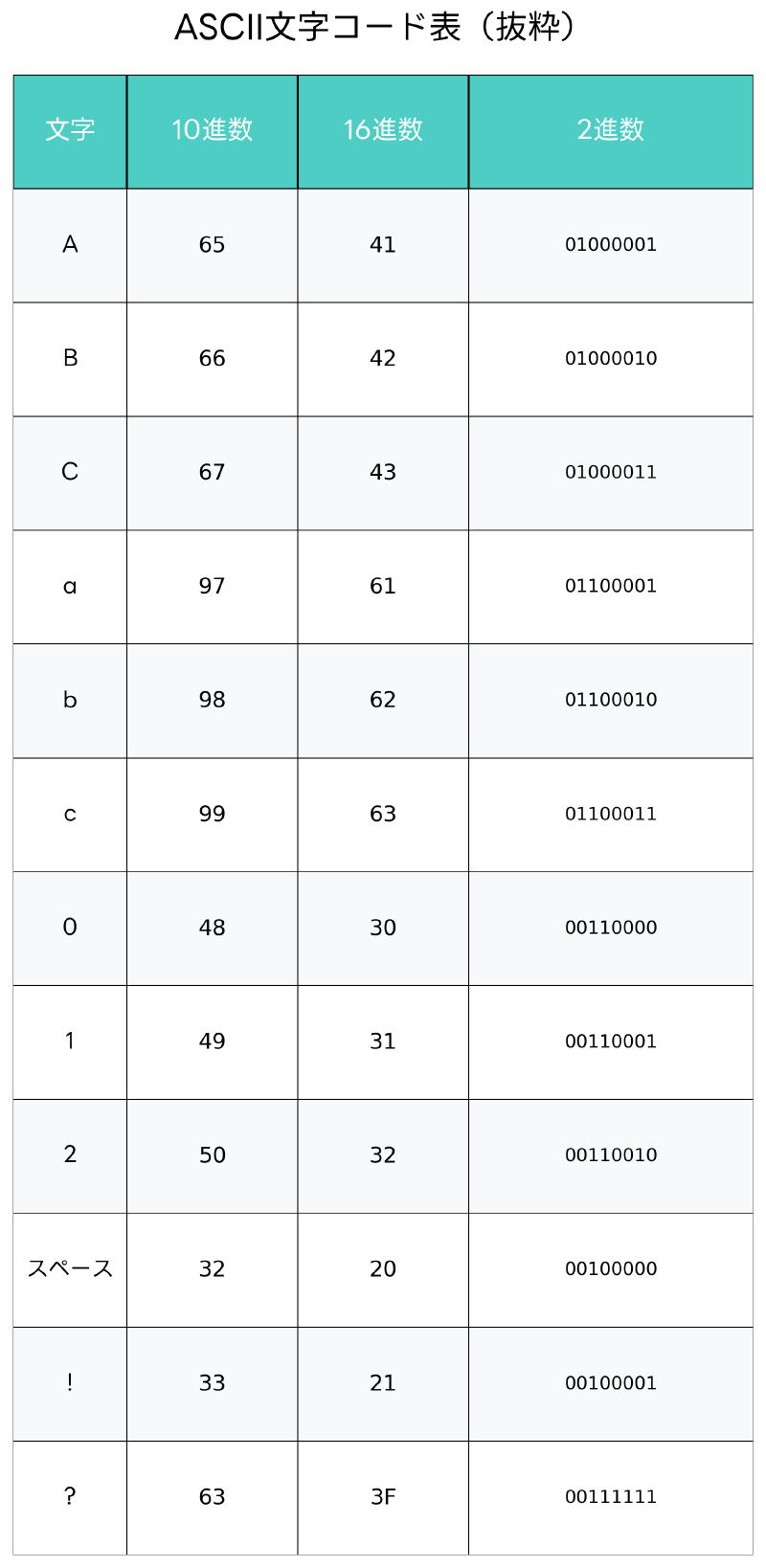
ASCII(American Standard Code for Information Interchange)は、コンピュータシステムにおける文字表現の基礎となる文字エンコーディング規格です。1963年にアメリカ規格協会(ASA、現在のANSI)によって策定されたこの規格は、現在でも世界中のコンピュータシステムで広く使用されています。応用情報技術者試験においても重要な基礎知識として頻繁に出題される内容であり、情報処理技術者にとって必須の理解事項です。
ASCIIは7ビット(128文字)で構成される文字エンコーディングシステムであり、英数字、記号、制御文字を含む基本的な文字セットを定義しています。この規格の登場により、異なるコンピュータシステム間での文字データの互換性が大幅に向上し、現代の情報社会の基盤を築く重要な役割を果たしました。
ASCII規格の歴史的背景と発展
ASCII規格が策定される以前、各コンピュータメーカーは独自の文字エンコーディングシステムを使用していました。IBMのEBCDIC、各社独自のコードシステムなど、統一性のない状況が続いていたため、システム間でのデータ交換が困難でした。この問題を解決するため、業界標準として統一された文字エンコーディング規格の必要性が高まりました。
1963年に最初のASCII規格(ASA X3.4-1963)が制定され、その後1967年と1986年に改訂が行われました。現在使用されているASCII規格は、1986年版(ANSI X3.4-1986)が基準となっています。この規格は、後にISO/IEC 646として国際標準化機構によって国際規格として採用され、世界的な標準として確立されました。
ASCIIの開発には、テレタイプ端末の制約も大きく影響しています。当時主流だったテレタイプ端末の機能に合わせて文字セットが設計されたため、現在でも使用される多くの制御文字(改行、タブ、ベルなど)が含まれています。古典的なテレタイプ端末の動作原理を理解することで、ASCII規格の設計思想をより深く理解できます。
ASCII文字コードの構造と分類
ASCIIは7ビット(0から127まで)で構成され、合計128文字を表現できます。これらの文字は機能に応じて以下のように分類されます。
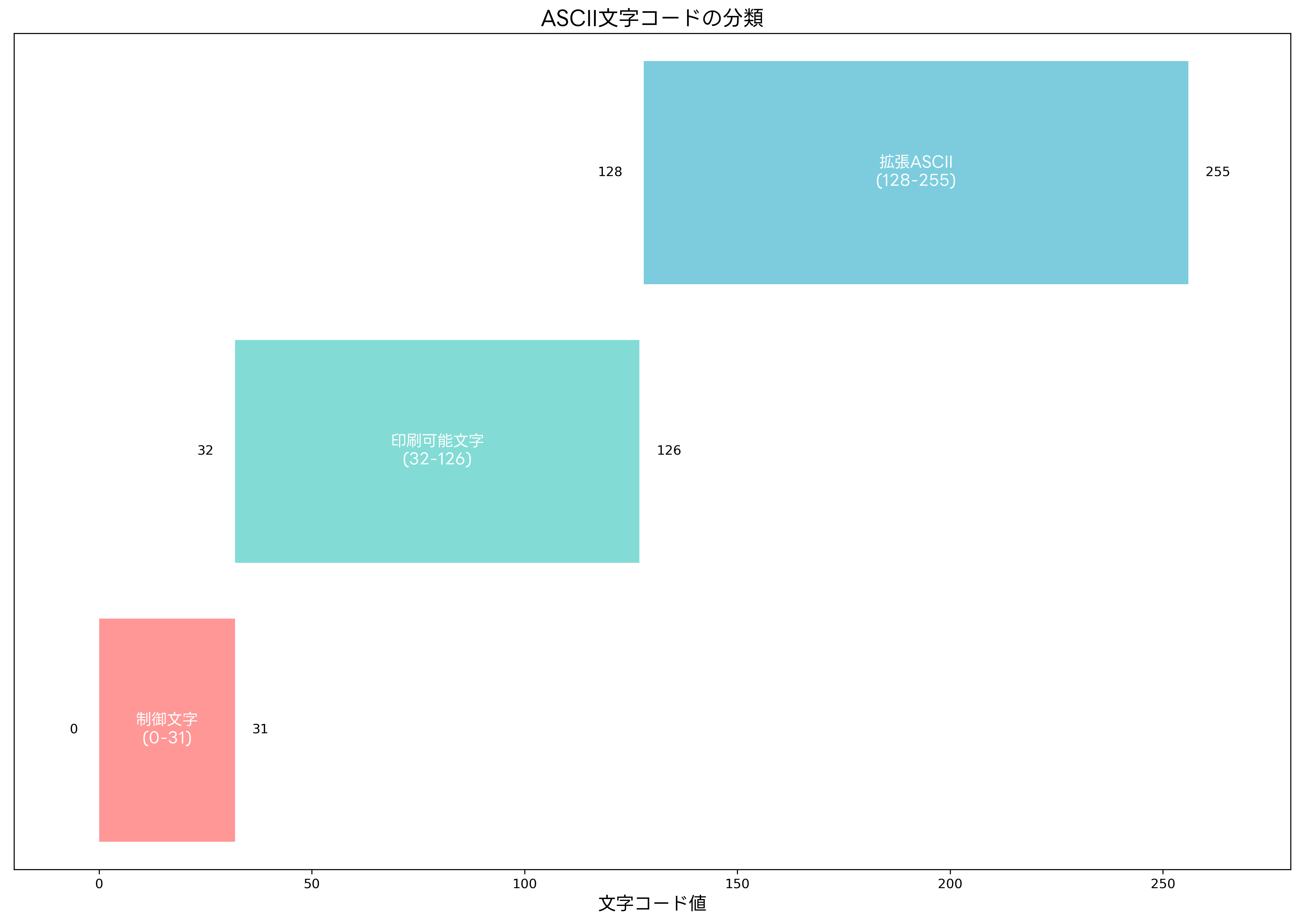
制御文字(0-31番)は、テキストの表示や通信制御のために使用される特殊な文字です。これらの文字は画面に表示されることはありませんが、改行(LF:10番)、復帰(CR:13番)、タブ(HT:9番)、ヌル文字(NUL:0番)など、テキスト処理において重要な役割を果たします。特に、改行コードの扱いは、Windows(CRLF)、Unix/Linux(LF)、古いMac(CR)といったオペレーティングシステムごとに異なるため、テキストエディタを選択する際の重要な考慮事項となります。
印刷可能文字(32-126番)は、実際に画面や紙に表示される文字です。この範囲には、スペース(32番)、英大文字(65-90番)、英小文字(97-122番)、数字(48-57番)、各種記号が含まれます。特に、数字の'0’から'9’までは48から57の連続した値に割り当てられており、文字から数値への変換処理においてよく利用されます。このような変換処理を効率的に行うためには、プログラミング学習書で基本的なアルゴリズムを学習することが重要です。
127番のDEL文字は、もともと紙テープのパンチホールをすべて開けることで文字を削除するために使用されていました。現在では削除機能として利用されることは少なくなりましたが、一部のシステムやプロトコルでは特別な意味を持つ制御文字として使用されています。
ASCIIコードの数値表現システム
ASCIIコードは、文字を数値で表現するシステムです。各文字には0から127までの一意の数値が割り当てられ、この数値を様々な進法で表現できます。コンピュータシステムでは、10進数、16進数、2進数での表現が一般的に使用されます。
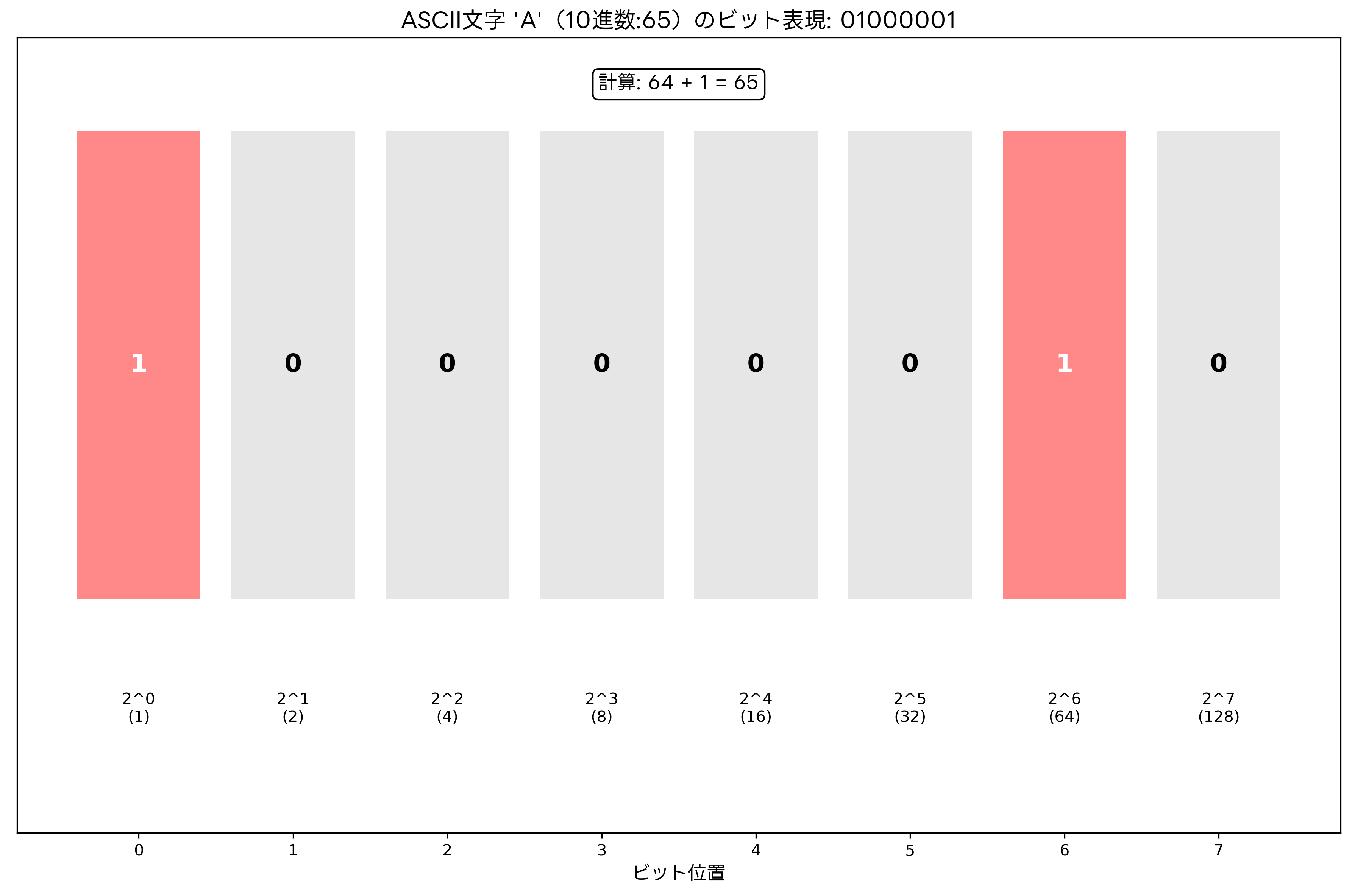
例えば、文字’A’は10進数で65、16進数で41、2進数で01000001として表現されます。この数値表現システムにより、コンピュータは文字データを数値として処理し、演算や比較を効率的に実行できます。文字’A’から’Z’までは連続した値(65-90)に割り当てられているため、大文字から小文字への変換は単純に32を加算することで実現できます(‘a’は97、‘A’は65なので差は32)。
2進数表現では、7ビットのパターンで文字を表現します。最上位ビット(8ビット目)は、元のASCII規格では使用されませんが、後の拡張ASCII規格では追加文字の表現に使用されるようになりました。この8ビット構造により、1バイト(8ビット)での文字表現が標準化され、コンピュータのメモリ管理や処理効率が向上しました。
ビット演算を理解するためには、コンピュータサイエンスの基礎書や論理演算学習教材を活用することが効果的です。これらの知識は、低レベルプログラミングやシステム開発において非常に重要です。
ASCII文字の使用頻度と最適化
英語テキストにおけるASCII文字の使用頻度は、文字圧縮アルゴリズムやキーボード配列の設計に重要な影響を与えています。統計的な分析により、英語において最も頻繁に使用される文字は’E’、‘T’、‘A’、‘O’、‘I’の順であることが知られています。
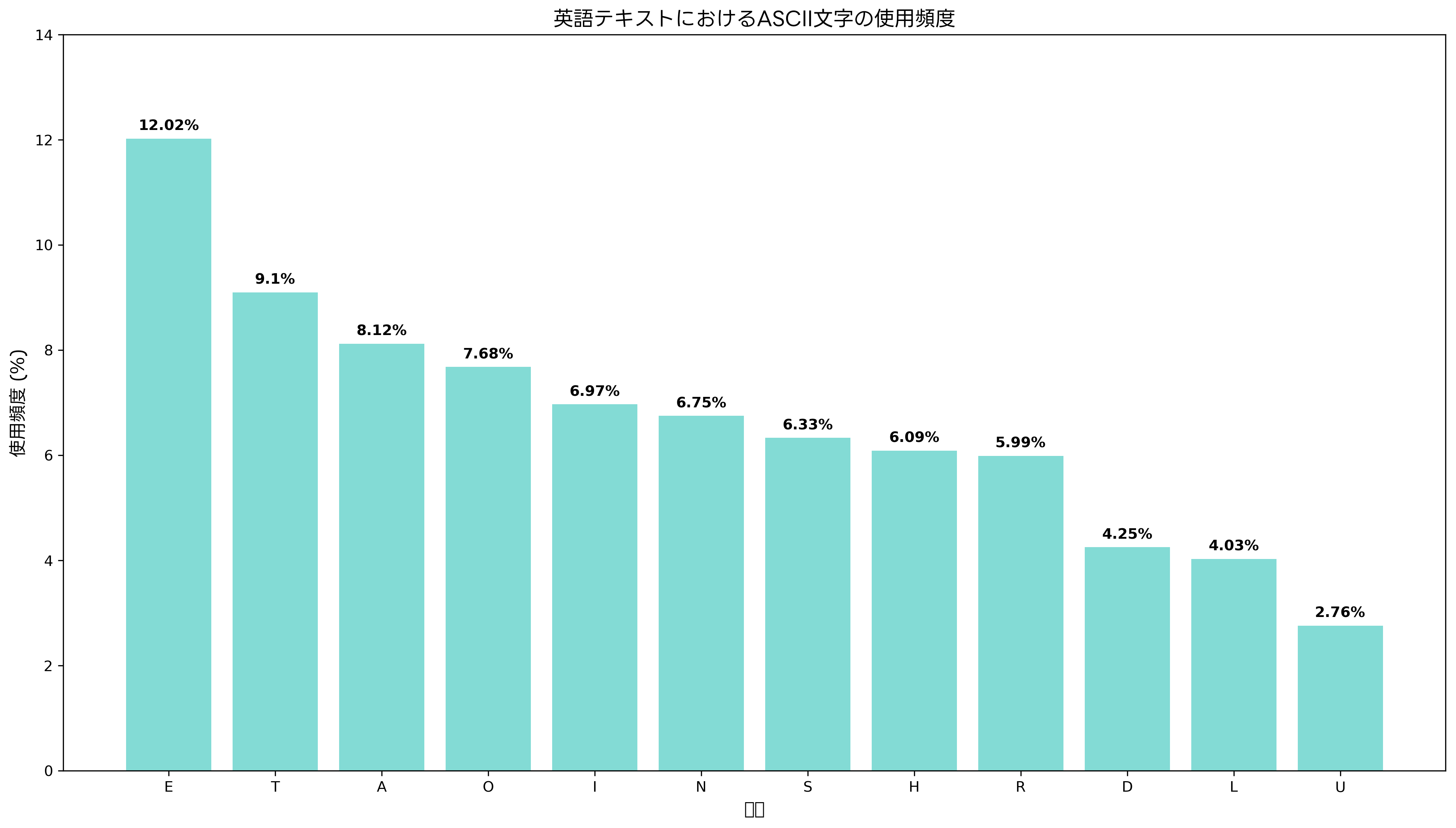
この頻度分析は、ハフマン符号化などの可変長符号化アルゴリズムの基礎となっています。頻度の高い文字により短いビット列を割り当てることで、テキストデータの圧縮効率を向上させることができます。データ圧縮技術の専門書では、このような統計的手法を詳しく学ぶことができます。
QWERTY配列のキーボードも、英語の文字使用頻度を考慮して設計されています。ただし、タイプライター時代の機械的制約も考慮されているため、現代のコンピュータ使用においては必ずしも最適とは言えません。より効率的なエルゴノミクスキーボードやプログラマー向けキーボードでは、文字使用頻度と手の動作効率を考慮した配列が採用されています。
テキスト処理プログラムの最適化において、ASCII文字の特性を活用することは重要です。例えば、大文字と小文字の変換、数字文字の数値変換、アルファベット文字の判定などは、ASCII文字コードの連続性を利用して効率的に実装できます。
他の文字エンコーディングとの比較
ASCIIは英語とラテン文字系言語のための文字エンコーディングであり、他の言語や文字体系には対応していません。この制限を解決するため、様々な拡張エンコーディングが開発されました。
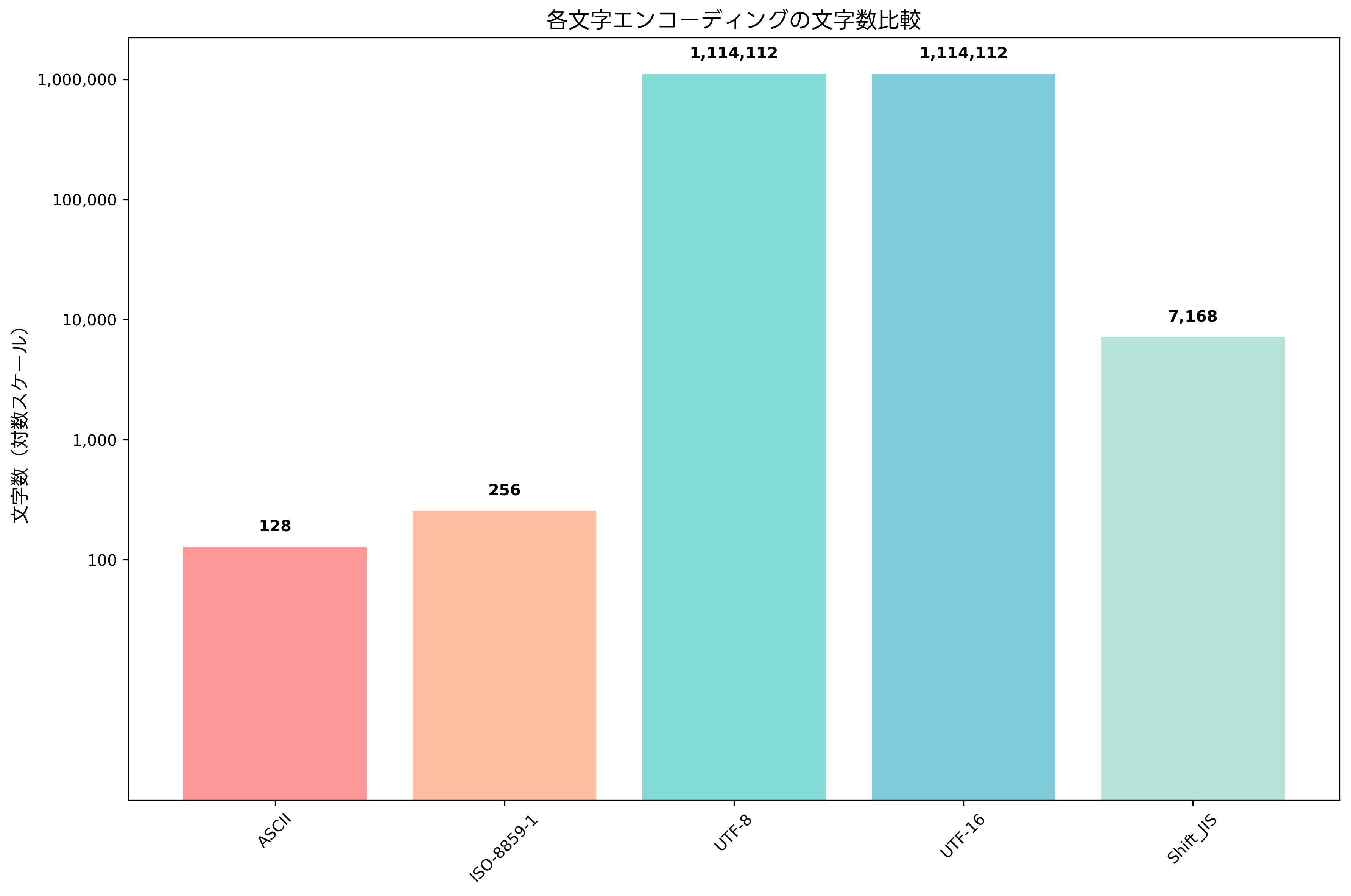
ISO-8859-1(Latin-1)は、ASCIIを8ビットに拡張した文字エンコーディングです。128-255番の領域に西欧言語で使用される追加文字(アクセント付き文字など)を定義しています。この拡張により、フランス語、ドイツ語、スペイン語などの西欧言語を表現できるようになりました。多言語対応ソフトウェア開発では、このような文字エンコーディングの理解が不可欠です。
UTF-8は、Unicodeの可変長エンコーディング方式であり、世界中のすべての文字を表現できます。UTF-8の優れた特徴の一つは、ASCII互換性です。ASCII文字(0-127番)はUTF-8でも同じバイト値で表現されるため、既存のASCIIベースのシステムとの互換性を保ちながら多言語対応が可能です。現代のWebシステムでは、UTF-8が標準的な文字エンコーディングとして使用されています。
Shift_JISは、日本語文字を表現するために開発されたエンコーディングです。ASCII文字をそのまま使用し、日本語文字(ひらがな、カタカナ、漢字)を2バイトで表現します。日本のWindows環境では長らく標準エンコーディングとして使用されてきましたが、現在はUTF-8への移行が進んでいます。日本語処理システム開発を学ぶ際には、これらのエンコーディングの特性を理解することが重要です。
UTF-16は、16ビット単位でUnicode文字を表現するエンコーディングです。BMP(基本多言語面)の文字は2バイトで表現され、それ以外の文字はサロゲートペアという仕組みで4バイトで表現されます。WindowsやJavaの内部文字表現として使用されており、システム間連携を行う際には重要な知識となります。
プログラミングにおけるASCII活用
プログラミング言語では、ASCII文字コードを活用した様々な処理が可能です。文字と数値の相互変換、文字列の並び替え、文字の種類判定など、基本的なテキスト処理の多くがASCII文字コードの特性を利用しています。
C言語やC++では、文字リテラル(‘A’など)は自動的にASCII文字コードの数値として扱われます。これにより、文字の比較や演算を数値として効率的に実行できます。例えば、‘A’ + 1は’B’を表す66という値になります。このような特性を活用することで、システムプログラミングにおいて効率的なコードを記述できます。
Pythonでは、ord()関数で文字からASCII文字コードを取得し、chr()関数で文字コードから文字を生成できます。これらの関数は、暗号化アルゴリズムやデータ変換処理の実装において頻繁に使用されます。Python学習教材では、これらの関数を活用した実践的なプログラミング技法を学ぶことができます。
Javaでは、char型がUTF-16でエンコードされたUnicode文字を表現しますが、ASCII範囲の文字については値が一致します。文字コード変換や国際化対応のプログラミングでは、Java国際化プログラミングの知識が重要です。
正規表現では、ASCII文字の範囲を指定する際に文字コードの知識が活用されます。[a-z]や[A-Z]、[0-9]といった文字クラスは、ASCII文字コードの連続性を利用した表現です。正規表現学習書では、このような文字エンコーディングと正規表現の関係を詳しく学ぶことができます。
セキュリティとASCII文字
ASCII文字は、セキュリティの観点からも重要な意味を持ちます。多くのセキュリティプロトコルや暗号化システムでは、ASCII文字のみを使用することで、文字エンコーディングに関する問題を回避しています。
SQLインジェクション攻撃の防御において、入力文字の検証は重要な対策の一つです。ASCII印刷可能文字のみを許可することで、多くの攻撃パターンを防ぐことができます。Webセキュリティ対策の実装では、このような文字フィルタリングの知識が不可欠です。
パスワードの強度評価においても、ASCII文字の種類(大文字、小文字、数字、記号)を考慮することが一般的です。各文字種を組み合わせることで、総当たり攻撃に対する耐性を向上させることができます。パスワードセキュリティの管理ツールでは、このような評価機能が実装されています。
ログファイルの解析においても、ASCII文字の理解は重要です。システムログやアクセスログは通常ASCII文字で記録されるため、ログ解析ツールの開発や運用では文字エンコーディングの知識が必要です。ログ解析システムの導入を検討する際には、ASCII文字処理能力も重要な評価項目となります。
データベースとASCII文字
データベースシステムにおいて、ASCII文字の理解は文字列処理や照合順序の設定に重要な役割を果たします。多くのデータベースシステムでは、ASCII照合順序がデフォルトの設定として使用されています。
MySQLでは、latin1_swedish_ci照合順序がデフォルトとして設定されることが多く、これはASCII文字の処理に最適化されています。ただし、多言語対応が必要な場合は、utf8mb4文字セットの使用が推奨されます。MySQL学習書では、文字セットと照合順序の適切な設定方法を学ぶことができます。
PostgreSQLでは、C照合順序がASCII文字コード順でのソートを提供します。この照合順序は処理速度が高速である反面、多言語文字の適切なソートはできません。国際化対応が必要な場合は、適切なロケール設定が必要です。PostgreSQL管理者ガイドでは、このような設定の詳細を学習できます。
Oracleデータベースでは、AL32UTF8キャラクタセットが推奨されていますが、既存システムでは米国7ASCIIが使用されている場合もあります。文字エンコーディングの変更は大規模な作業になるため、データベース移行計画の策定時には十分な検討が必要です。
インデックスの設計においても、ASCII文字の特性を活用できます。英数字のみを含むカラムでは、ASCII照合順序を使用することで、インデックスサイズの削減と検索性能の向上が期待できます。
応用情報技術者試験での出題傾向
応用情報技術者試験において、ASCII関連の問題は基本情報技術者試験よりも応用的な側面から出題される傾向があります。単純な文字コード変換だけでなく、システム設計や国際化対応の観点から問題が構成されることが多くあります。
午前問題では、文字エンコーディングの比較、データベースでの文字セット設定、Webシステムでの多言語対応などの文脈でASCII関連の知識が問われます。特に、UTF-8とASCIIの互換性、バイト数の計算、文字化けの原因と対策などは頻出のトピックです。
午後問題では、システム要件定義やアーキテクチャ設計の文脈で文字エンコーディングの選択が問われることがあります。国際化対応が必要なシステムでの文字エンコーディング選択、既存システムとの互換性確保、性能要件との兼ね合いなど、実践的な判断力が評価されます。
応用情報技術者試験対策書では、このような応用的な問題に対する解法や考え方を学ぶことができます。また、情報処理技術者試験過去問集を活用することで、出題傾向を把握し効率的な学習が可能です。
実際の業務経験がある場合は、自社システムの文字エンコーディング設計をASCIIとの関連で分析し、改善提案を考える練習も効果的です。このような実践的なアプローチにより、試験問題に対する理解力と解答力を向上させることができます。
現代システムにおけるASCIIの役割
現代のコンピュータシステムにおいて、ASCIIは直接的に使用される機会は減少していますが、その重要性は依然として高いものがあります。多くの現代的な文字エンコーディングは、ASCII互換性を維持することで既存システムとの連携を実現しています。
インターネットプロトコルの多くは、ASCIIベースで設計されています。HTTP、SMTP、FTPなどの基本的なプロトコルでは、制御情報やヘッダー情報にASCII文字を使用します。ネットワークプロトコル技術書では、これらのプロトコルにおけるASCIIの役割を詳しく学ぶことができます。
プログラミング言語の構文も、多くがASCII文字に基づいて設計されています。変数名や関数名に非ASCII文字を使用できる言語も増えていますが、予約語や演算子はASCII文字で定義されることが一般的です。プログラミング言語設計論では、このような設計思想の背景を理解できます。
JSONやXMLなどのデータ交換フォーマットでも、構造定義部分にはASCII文字が使用されます。データ部分では多言語文字を使用できますが、タグ名や属性名はASCII文字で記述することが推奨されています。データ交換フォーマット技術書では、このような実装上の考慮事項を学習できます。
コマンドラインインターフェースやシェルスクリプトでも、ASCIIの知識は重要です。多くのUNIXコマンドやLinuxツールは、ASCII文字ベースで設計されており、ファイル名やオプションの指定にASCII文字を使用します。システム管理実践書では、コマンドライン操作における文字エンコーディングの重要性を学ぶことができます。
まとめ
ASCIIは、1963年の策定以来、コンピュータシステムにおける文字表現の基礎として重要な役割を果たし続けています。7ビット128文字という制限はありますが、その単純性と明確性により、多くのシステムやプロトコルの基盤となっています。応用情報技術者試験においても、文字エンコーディングの基礎知識として重要な位置を占めています。
現代のシステム開発では、UTF-8などの多言語対応エンコーディングが主流となっていますが、ASCII互換性を維持することで既存システムとの連携を実現している場合が多くあります。このため、ASCIIの理解は現代の情報技術者にとっても必須の知識といえます。
文字エンコーディングの理解は、国際化対応、データベース設計、Webシステム開発、セキュリティ対策など、情報システムの様々な側面に影響します。継続的な学習により、変化する技術環境に対応できる基礎力を身につけることが重要です。ASCII規格の歴史と設計思想を理解することで、現代の文字エンコーディング技術をより深く理解し、適切なシステム設計判断を行うことができるようになります。