アトリビュート(属性)は、情報システムにおいて最も基本的かつ重要な概念の一つです。データベース設計、XML/HTML文書構造、プログラミング言語のオブジェクト指向設計など、IT分野の様々な領域で中核的な役割を果たしています。応用情報技術者試験においても頻出のトピックであり、システム設計や開発において深い理解が求められる重要な概念です。
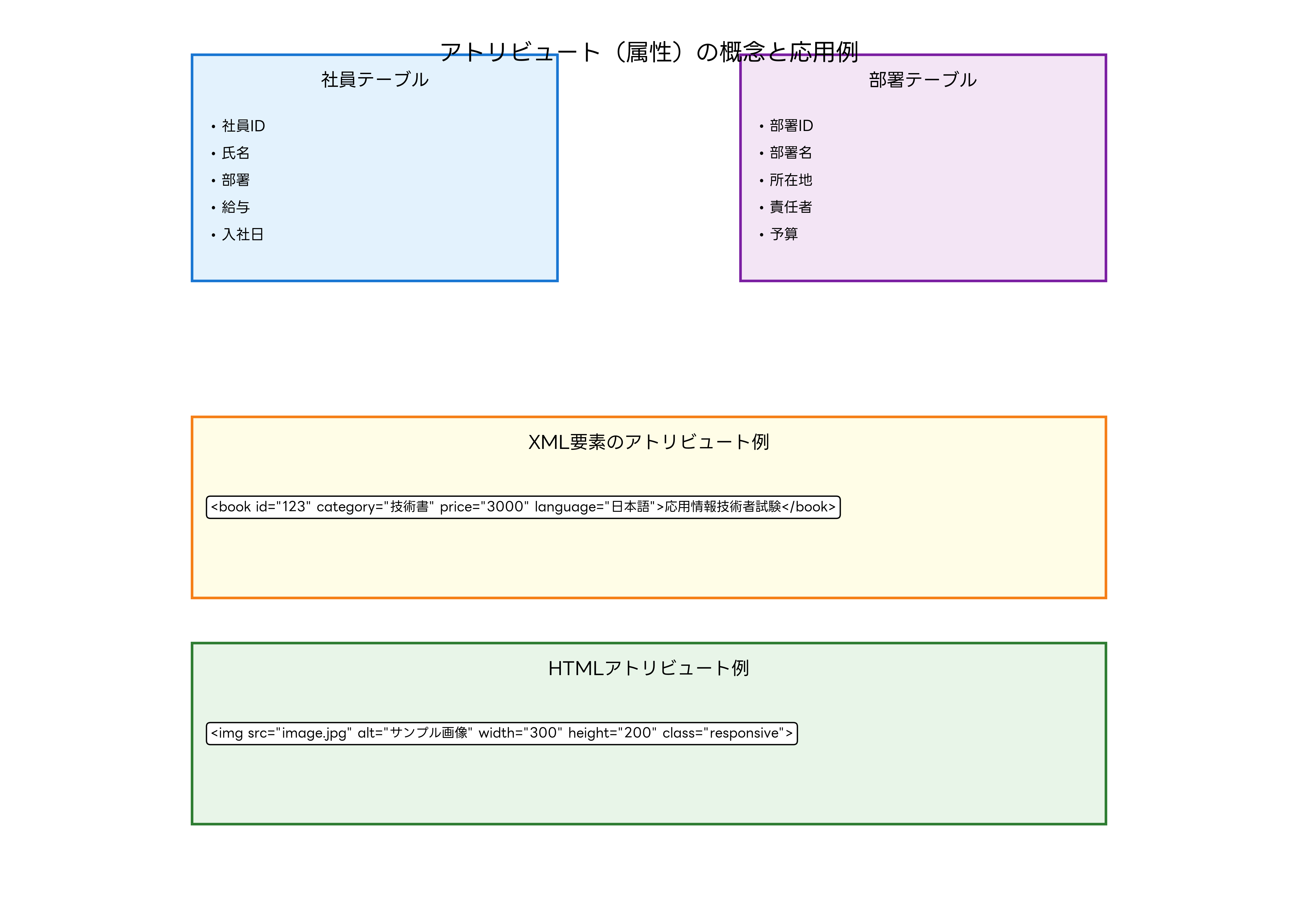
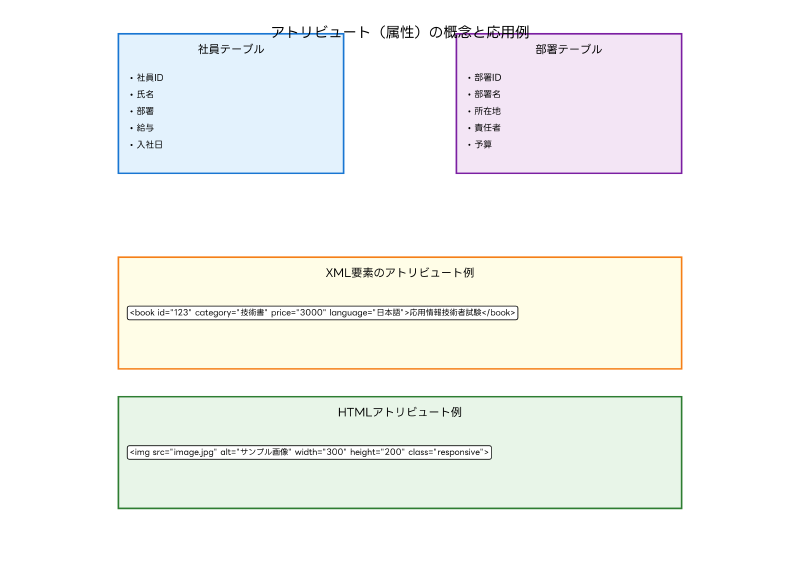
アトリビュートとは、エンティティ(実体)やオブジェクトが持つ特性や性質を表現するデータ要素のことです。例えば、「社員」というエンティティに対して、「社員ID」「氏名」「部署」「給与」などがアトリビュートとなります。これらの属性によって、個々の社員の特性が具体的に表現され、データとして管理することが可能になります。
デ ータベースにおけるアトリビュート
関係データベースにおいて、アトリビュートはテーブルの列(カラム)として実装されます。各アトリビュートには、データ型、制約条件、デフォルト値などの特性が定義され、データの整合性と品質を保つ役割を果たします。適切なアトリビュート設計は、データベースのパフォーマンス、保守性、拡張性に直接影響を与える重要な要素です。
データベース設計において、アトリビュートは様々な種類に分類されます。主キー属性は、テーブル内の各行を一意に識別する役割を持ち、データの整合性を保つ上で最も重要な属性です。外部キー属性は、他のテーブルとの関連性を表現し、参照整合性を維持する役割を果たします。これらの重要な属性を効率的に管理するためには、高性能なデータベース管理システムの導入が不可欠です。
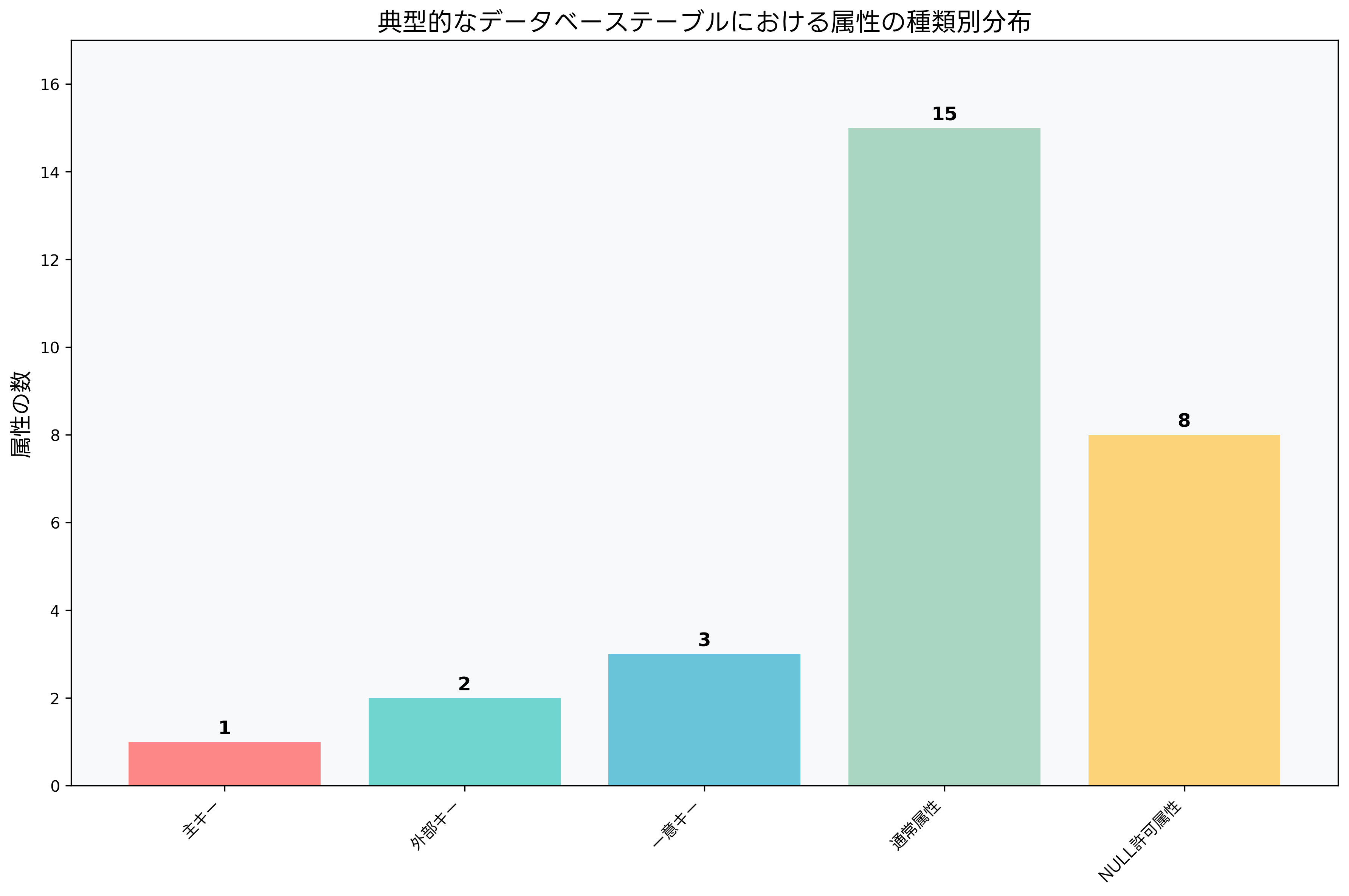
一意キー属性は、主キーとは別に一意性を保証する属性であり、重複を防ぐ重要な役割を果たします。例えば、社員テーブルにおいて、社員IDが主キーの場合、メールアドレスを一意キーとして設定することで、同じメールアドレスを持つ複数の社員レコードの作成を防ぐことができます。このような制約を効果的に管理するには、データベース制約管理ツールの活用が推奨されます。
NULL許可属性は、値が存在しない場合を許容する属性です。この概念は、現実世界のデータの不完全性を適切に表現するために重要です。例えば、顧客テーブルにおいて、FAX番号は必須ではないため、NULL値を許可する設計が適切です。しかし、NULL値の扱いは複雑であり、クエリの結果に予期しない影響を与える可能性があるため、慎重な設計が必要です。
データ型の選択は、アトリビュート設計における最も重要な決定の一つです。VARCHAR型は文字列データに使用され、最も汎用性の高いデータ型として広く利用されています。INT型は整数値を格納し、主キーや外部キー、数値計算に使用されます。DATE型とTIMESTAMP型は日時データを扱い、ビジネスロジックにおいて重要な役割を果たします。適切なデータ型を選択することで、ストレージ効率とクエリパフォーマンスを大幅に改善できます。
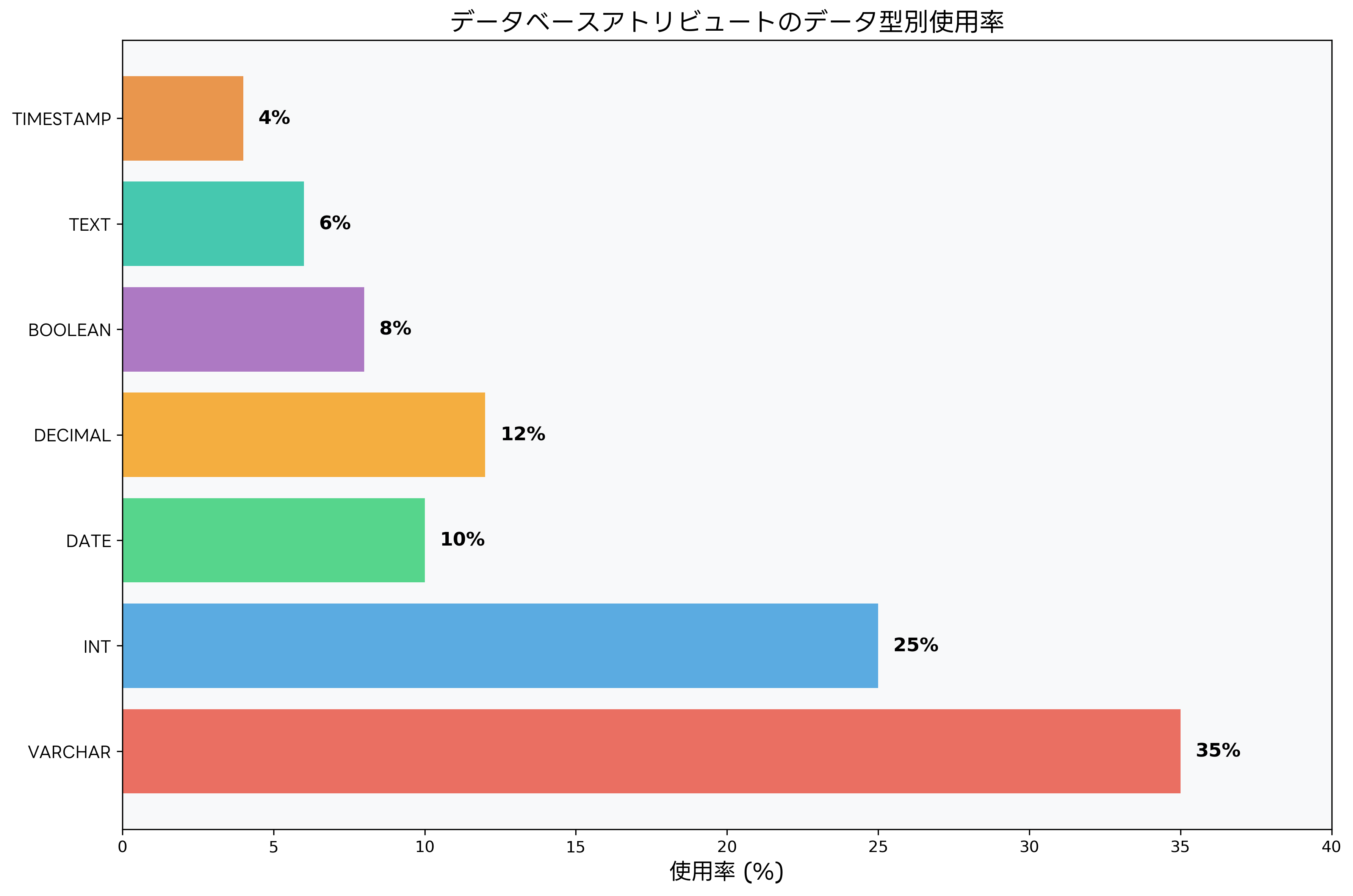
DECIMAL型は、金融データや精密な数値計算において重要な役割を果たします。浮動小数点型と異なり、丸め誤差が発生しないため、会計システムや科学計算において必須のデータ型です。BOOLEAN型は真偽値を表現し、フラグやステータスの管理に使用されます。TEXT型は大容量の文字列データを格納するために使用され、文書管理システムやコンテンツ管理システムにおいて重要な役割を果たします。
データベースの設計品質を向上させるためには、データベース設計支援ツールの活用が効果的です。これらのツールは、アトリビュートの正規化、依存関係の分析、パフォーマンス最適化などの機能を提供し、高品質なデータベース設計を支援します。
XML/HTMLにおけるアトリビュート
XML(Extensible Markup Language)とHTML(HyperText Markup Language)において、アトリビュートは要素に付加情報を提供する重要な仕組みです。XML文書では、要素の開始タグ内に属性名と属性値のペアとして記述され、要素の特性や動作を詳細に定義します。HTMLでは、要素の外観、動作、アクセシビリティなどを制御するために広く使用されています。
XMLアトリビュートの設計において、名前空間の概念は重要です。異なるスキーマで定義された同名の属性を区別するために、名前空間プレフィックスを使用します。例えば、xml:lang属性は言語情報を表し、xmlns属性は名前空間を定義します。このような標準的な属性を適切に活用することで、相互運用性の高いXML文書を作成できます。
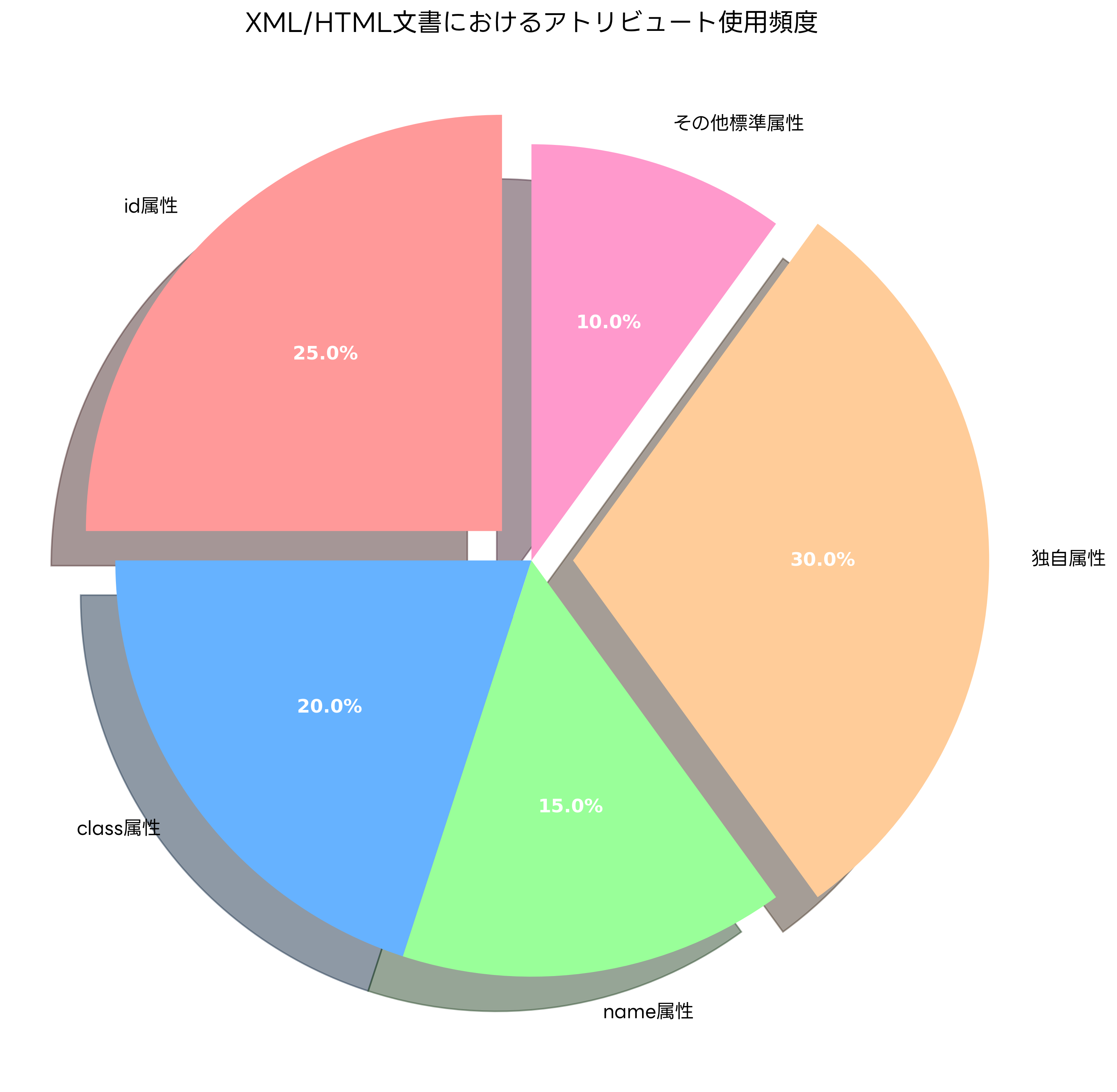
HTMLにおけるclass属性とid属性は、CSS(Cascading Style Sheets)やJavaScriptとの連携において中核的な役割を果たします。class属性は複数の要素に同じスタイルや動作を適用するために使用され、id属性は特定の要素を一意に識別するために使用されます。これらの属性を効果的に活用するためには、Webデザイン支援ツールやHTML/CSS開発環境の導入が推奨されます。
name属性は、フォーム要素において特に重要な役割を果たします。input要素、select要素、textarea要素などにname属性を設定することで、サーバーサイドでのデータ処理が可能になります。また、radio buttonやcheckboxのグループ化にも使用され、ユーザーインターフェースの設計において欠かせない属性です。
アクセシビリティ向上のためのアトリビュートも重要です。alt属性は画像要素に代替テキストを提供し、視覚障害者のためのスクリーンリーダーで読み上げられます。title属性はツールチップとして表示される追加情報を提供し、ユーザビリティの向上に貢献します。これらの属性を適切に設定することで、Webアクセシビリティの向上が実現できます。
独自属性(カスタム属性)の使用は、HTML5においてdata-*属性として標準化されました。例えば、data-product-id="12345"のような属性を定義することで、JavaScriptからアクセス可能な追加データを要素に埋め込むことができます。この仕組みにより、サーバーサイドのデータとクライアントサイドのスクリプトを効率的に連携させることが可能になります。
オブジェクト指向プログラミングにおけるアトリビュート
オブジェクト指向プログラミング(OOP)において、アトリビュートはオブジェクトの状態を表現するデータメンバーとして実装されます。クラス内で定義されるアトリビュートは、そのクラスから生成されるすべてのインスタンスが持つ共通の特性を定義します。適切なアトリビュート設計は、コードの再利用性、保守性、拡張性に大きな影響を与えます。
カプセル化の原則により、アトリビュートは通常プライベート(private)として定義され、ゲッターとセッターメソッドを通じてアクセスされます。この設計パターンにより、データの整合性を保ち、オブジェクトの内部実装を隠蔽することができます。例えば、Personクラスのage属性に対して、負の値が設定されることを防ぐバリデーション機能をセッターメソッドに実装できます。
継承関係において、アトリビュートの可視性(visibility)は重要な概念です。protected属性は、派生クラスからアクセス可能でありながら、外部からは隠蔽されます。public属性は自由にアクセス可能ですが、カプセル化の原則に反するため、慎重な使用が必要です。これらの概念を効果的に学習するためには、オブジェクト指向プログラミング教材の活用が推奨されます。
静的属性(static attribute)は、クラス全体で共有される属性であり、個々のインスタンスではなくクラス自体に属します。例えば、Carクラスにおいて、生産された車の総数を管理するためのstaticカウンタ属性を定義できます。この概念は、リソース管理やシングルトンパターンの実装において重要な役割を果たします。
アトリビュート設計のベストプラクティス
効果的なアトリビュート設計には、一貫した命名規則の採用が不可欠です。キャメルケース(camelCase)やスネークケース(snake_case)などの命名規則を組織全体で統一することで、コードの可読性と保守性が大幅に向上します。また、省略形の使用は最小限に留め、意味が明確に伝わる名前を選択することが重要です。

データの正規化は、データベースアトリビュート設計における基本原則です。第一正規化では、各属性が原子的な値を持つことを保証します。第二正規化では、部分関数従属を排除し、第三正規化では推移関数従属を排除します。これらの正規化により、データの冗長性を排除し、更新異常を防ぐことができます。正規化の理論と実践を学ぶためには、データベース正規化の専門書の活用が効果的です。
パフォーマンス最適化においては、インデックス戦略が重要な役割を果たします。頻繁に検索される属性にはインデックスを作成し、クエリのパフォーマンスを向上させます。ただし、過度なインデックス作成は更新処理のパフォーマンスを低下させるため、適切なバランスが必要です。データベースパフォーマンス監視ツールを使用して、継続的な最適化を実施することが推奨されます。
制約条件の定義は、データの品質を保つために重要です。NOT NULL制約は必須項目を定義し、CHECK制約は値の範囲や形式を制限します。UNIQUE制約は重複を防ぎ、FOREIGN KEY制約は参照整合性を保ちます。これらの制約を適切に定義することで、アプリケーションレベルでのバリデーション処理を簡略化し、データの整合性を確実に保つことができます。
応用情報技術者試験での出題傾向
応用情報技術者試験において、アトリビュートに関する問題は、データベース設計、システム設計、プログラミングの各分野で頻繁に出題されています。特に、ER図(Entity-Relationship Diagram)の読み取りや作成問題では、エンティティとアトリビュートの関係を正確に理解することが求められます。
午前問題では、アトリビュートの定義、データ型の特性、制約条件の効果などが問われます。例えば、「主キー属性に設定できない制約はどれか」といった問題や、「第三正規形を満たすために排除すべき関数従属はどれか」といった正規化に関する問題が出題されます。これらの問題に対応するためには、応用情報技術者試験の対策書での基礎知識の習得が重要です。
午後問題では、より実践的な場面でのアトリビュート設計能力が評価されます。要件定義書からER図を作成する問題、既存のデータベース設計の問題点を指摘する問題、パフォーマンス改善のためのインデックス設計問題などが出題されます。これらの問題に対応するためには、理論的な知識に加えて、実際のシステム開発経験やデータベース設計の実践書による学習が効果的です。
XMLやHTMLのアトリビュートに関する問題も出題されます。XML Schemaの定義、HTMLフォームの設計、Webアクセシビリティの考慮事項などが主要なトピックです。特に、Web技術の進歩に伴い、HTML5の新しい属性やXMLの名前空間に関する問題の出題頻度が増加しています。
試験対策としては、過去問題の徹底的な分析と反復練習が重要です。過去問題集を活用して、出題パターンを理解し、時間内に正確に解答する能力を身につけることが求められます。また、データベース実習環境を構築して、実際にテーブル設計やクエリ作成を行うことで、理論と実践の両面から理解を深めることができます。
実務における応用例
実際のシステム開発において、アトリビュート設計は プロジェクトの成功を左右する重要な要素です。ECサイトの商品管理システムでは、商品属性として、商品ID、商品名、価格、在庫数、カテゴリID、説明文、画像URL、作成日時、更新日時などを定義します。これらの属性を適切に設計することで、効率的な商品検索、在庫管理、価格更新などの機能を実現できます。
顧客管理システム(CRM)では、顧客属性として、顧客ID、氏名、メールアドレス、電話番号、住所、生年月日、性別、職業、登録日、最終ログイン日などを定義します。これらの属性を活用して、顧客セグメンテーション、マーケティング施策の効果測定、顧客満足度の向上などを実現できます。効果的な顧客管理を行うためには、CRMシステムの導入と適切な属性設計が不可欠です。
人事管理システムでは、従業員属性として、社員ID、氏名、部署、役職、給与、入社日、退社日、スキル、資格、評価履歴などを定義します。これらの属性を基に、人事評価、昇進管理、スキル開発計画の策定などを効率的に行うことができます。複雑な人事データを管理するためには、人事管理システムの導入が推奨されます。
新技術とアトリビュートの進化
近年の技術革新により、アトリビュートの概念も大きく進歩しています。NoSQLデータベースでは、従来の関係データベースの固定的なスキーマから脱却し、柔軟な属性定義が可能になりました。MongoDBやCouchDBなどのドキュメント指向データベースでは、JSON形式でネストした属性構造を定義でき、より複雑なデータモデルを表現できます。
ビッグデータ処理においては、スキーマレス(Schema-less)やスキーマオンリード(Schema-on-Read)の概念が重要になっています。データの構造が事前に定義されていない状況でも、処理時に動的に属性を解釈し、必要な情報を抽出できます。このような柔軟なデータ処理を実現するためには、ビッグデータ処理基盤の構築が必要です。
機械学習とAIの分野では、特徴量(feature)としてのアトリビュートが重要な役割を果たします。入力データの各属性が学習アルゴリズムの性能に直接影響するため、特徴量エンジニアリングと呼ばれる属性の選択・加工・組み合わせの技術が発達しています。効果的な特徴量エンジニアリングを行うためには、機械学習ツールやデータ分析環境の活用が不可欠です。
クラウドコンピューティング環境では、属性ベースアクセス制御(ABAC: Attribute-Based Access Control)が注目されています。ユーザーの属性、リソースの属性、環境の属性を組み合わせて、きめ細かなアクセス制御を実現します。この技術により、従来の役割ベースアクセス制御(RBAC)では困難だった複雑なセキュリティ要件に対応できます。
セキュリティとプライバシーの考慮事項
現代のアトリビュート設計においては、セキュリティとプライバシーの保護が最重要課題となっています。個人情報保護法やGDPR(一般データ保護規則)などの法規制により、個人を特定可能な属性の取り扱いには厳格な管理が求められています。氏名、メールアドレス、電話番号、住所などの個人識別属性は、適切な暗号化、アクセス制御、監査ログの記録が必要です。
データマスキングとデータ匿名化の技術により、個人識別属性を保護しながらデータ分析や開発環境での利用を可能にします。例えば、本番環境の顧客データをテスト環境で使用する際に、氏名を仮名に置換し、メールアドレスをランダムな文字列に変更することで、プライバシーを保護しながら現実的なデータでのテストが可能になります。このような処理を効率的に行うためには、データマスキングツールの導入が推奨されます。
属性レベルでの暗号化も重要な技術です。特に機密性の高い属性(給与情報、健康情報、金融情報など)については、データベースレベルでの暗号化に加えて、アプリケーションレベルでの暗号化を実装することで、多層防御を実現できます。データ暗号化ソリューションを活用することで、高度なセキュリティ要件に対応できます。
国際化とローカライゼーション
グローバルなシステム開発においては、多言語・多文化対応のためのアトリビュート設計が重要です。文字エンコーディングとしてUTF-8を標準採用し、多バイト文字を適切に処理できるようにします。また、言語固有の属性(言語コード、地域コード、通貨コード)を定義することで、ローカライゼーションに対応できます。
日付と時刻の属性については、タイムゾーンの考慮が不可欠です。UTC(協定世界時)での統一的な管理と、表示時のローカルタイムゾーンへの変換を適切に実装することで、グローバルなユーザーが混乱することなくシステムを利用できます。このような国際化対応を効率的に行うためには、国際化支援ツールの活用が効果的です。
文化的な違いも考慮する必要があります。例えば、名前の属性設計において、西洋式の「姓・名」の概念が適用できない文化圏では、より柔軟な名前属性の設計が必要です。住所の属性についても、国や地域によって構造が大きく異なるため、汎用的な設計と地域特化の設計を適切に組み合わせることが重要です。
まとめ
アトリビュート(属性)は、現代の情報システムにおいて基盤となる重要な概念です。データベース設計からWeb開発、オブジェクト指向プログラミングまで、あらゆる技術領域でその理解と適切な設計が求められています。応用情報技術者試験においても、アトリビュートに関する深い理解は必須の知識となっています。
技術の進歩とともに、アトリビュートの概念も進化し続けています。NoSQLデータベース、ビッグデータ処理、機械学習、クラウドコンピューティングなどの新しい技術領域においても、適切な属性設計が システムの成功を左右する重要な要素となっています。また、セキュリティ、プライバシー、国際化などの非機能要件への対応も、現代のアトリビュート設計において欠かせない考慮事項です。
継続的な学習と実践により、変化する技術環境に対応できるアトリビュート設計能力を身につけることが、ITプロフェッショナルとしての成長につながります。理論的な知識と実務経験を組み合わせ、ユーザーのニーズに応える高品質なシステムの構築を目指すことが重要です。