現代の情報社会において、大量のデータから有用な情報を抽出し、パターンを発見する技術は極めて重要です。その中核を成すのが分類技術です。分類は、データを異なるカテゴリーやクラスに自動的に振り分ける機械学習の手法であり、応用情報技術者試験でも重要な出題分野として扱われています。この技術は、企業の意思決定支援からセキュリティシステム、医療診断まで幅広い分野で活用されており、現代社会のデジタルインフラを支える基盤技術となっています。
分類は、教師あり学習の一種で、既知のラベル付きデータを用いて学習を行い、新しいデータに対して適切なクラスラベルを予測する技術です。この技術により、企業は顧客の行動パターンを予測し、マーケティング戦略を最適化することができます。また、金融機関では不正取引の検出、医療分野では疾患の早期発見など、社会の様々な課題解決に貢献しています。
分類の基本概念と重要性
分類技術の基本概念は、入力データの特徴量を分析し、事前に定義されたカテゴリーの中から最も適切なものを選択することです。この処理は人間の認識プロセスに似ており、例えば写真を見て「これは猫である」「これは犬である」と判断するのと同様の処理をコンピューターが自動的に実行します。
分類問題の成功の鍵は、適切な特徴量の選択と高品質な学習データの準備にあります。特徴量とは、分類対象のオブジェクトを数値的に表現した属性のことで、例えば画像分類では色の分布、エッジの特徴、テクスチャなどが特徴量となります。現代のデータサイエンスにおいて、効率的な特徴量抽出には高性能なデータ分析ソフトウェアや統計解析ツールが不可欠です。
分類技術は、ビジネスインテリジェンスの分野で特に重要な役割を果たしています。顧客データの分析により、購買傾向の予測、チャーン率の算出、個人化されたレコメンデーションの提供などが可能になります。これらの分析を効果的に実行するため、多くの企業がビジネスインテリジェンスプラットフォームや顧客分析システムを導入しています。
分類の種類と特徴
分類技術にはいくつかの種類があり、それぞれ異なる特徴と適用場面があります。最も基本的なのが二値分類で、データを2つのクラスに分類します。例えば、メールのスパム判定、医療診断における陽性・陰性の判定などがこれにあたります。二値分類は比較的シンプルで理解しやすく、多くの実用的な問題に適用できます。
多クラス分類は、3つ以上のクラスに分類する手法です。文書分類において、記事をスポーツ、政治、経済、科学などのカテゴリーに分類する場合がこれにあたります。多クラス分類では、クラス間の関係性や階層構造を考慮することが重要で、より高度なアルゴリズムと計算リソースが必要になります。
多ラベル分類は、一つのデータポイントが複数のラベルを同時に持つことができる分類手法です。例えば、映画のジャンル分類において、一つの映画が「アクション」と「コメディ」の両方のジャンルに属する場合があります。この種の分類は、現実世界の複雑な関係性をより正確に表現できますが、実装とモデルの解釈が複雑になります。
階層分類は、クラス間に階層関係がある場合の分類手法です。例えば、商品分類において「電子機器 > コンピューター > ノートパソコン」のような階層構造を持つ分類を扱います。このような分類には、階層分析専用ソフトウェアや分類体系管理システムの活用が効果的です。
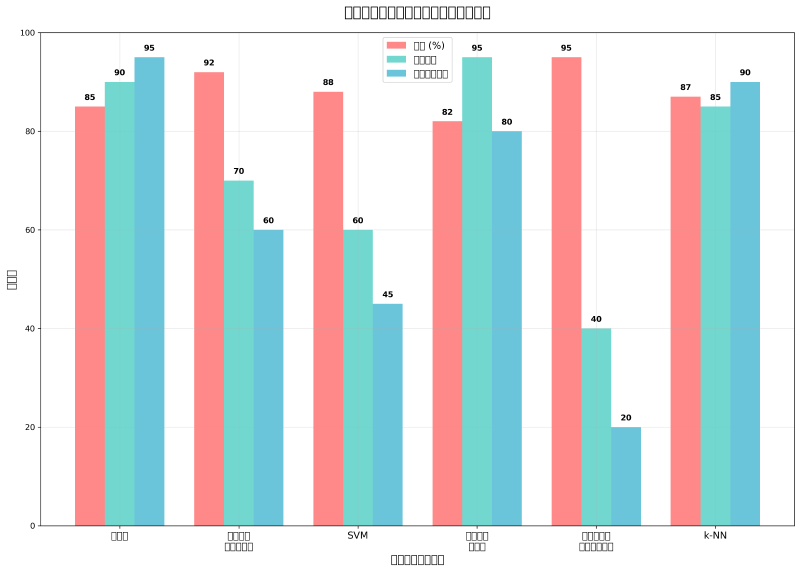
主要な分類アルゴリズム
決定木は、分類アルゴリズムの中でも特に理解しやすく、解釈しやすい手法として広く活用されています。決定木は、データの特徴量に基づいて一連の判定ルールを構築し、最終的な分類結果に到達する過程をツリー構造で表現します。この手法の最大の利点は、人間が理解しやすい形で分類ルールを提示できることです。
サポートベクターマシン(SVM)は、高次元データの分類に特に優れた性能を示すアルゴリズムです。SVMは、異なるクラスのデータポイントを最適に分離する超平面を見つけることで分類を行います。この手法は、テキスト分類や画像分類などの複雑なデータに対して高い性能を発揮します。SVMの実装と最適化には、専用の数値計算ライブラリや機械学習開発環境の活用が推奨されます。
ランダムフォレストは、複数の決定木を組み合わせて予測精度を向上させるアンサンブル学習の代表例です。この手法は、個々の決定木の予測を統合することで、より安定した分類性能を実現します。ランダムフォレストは、過学習を抑制し、様々な種類のデータに対して頑健な性能を示すため、実用的なアプリケーションで広く採用されています。
ニューラルネットワークは、脳の神経回路を模倣した分類アルゴリズムで、特に深層学習の発展により注目を集めています。多層のニューラルネットワークは、複雑な非線形関係を学習することができ、画像認識、自然言語処理、音声認識などの分野で革新的な成果を上げています。深層学習の実装には、高性能GPUや深層学習フレームワークが必要不可欠です。
ナイーブベイズは、ベイズの定理に基づく確率的分類手法で、特にテキスト分類やスパムフィルタリングで優れた性能を発揮します。この手法は、計算が高速で、少ないデータでも比較的良い性能を示すという利点があります。また、結果の解釈が容易で、各特徴量がクラス分類に与える影響を定量的に評価できます。
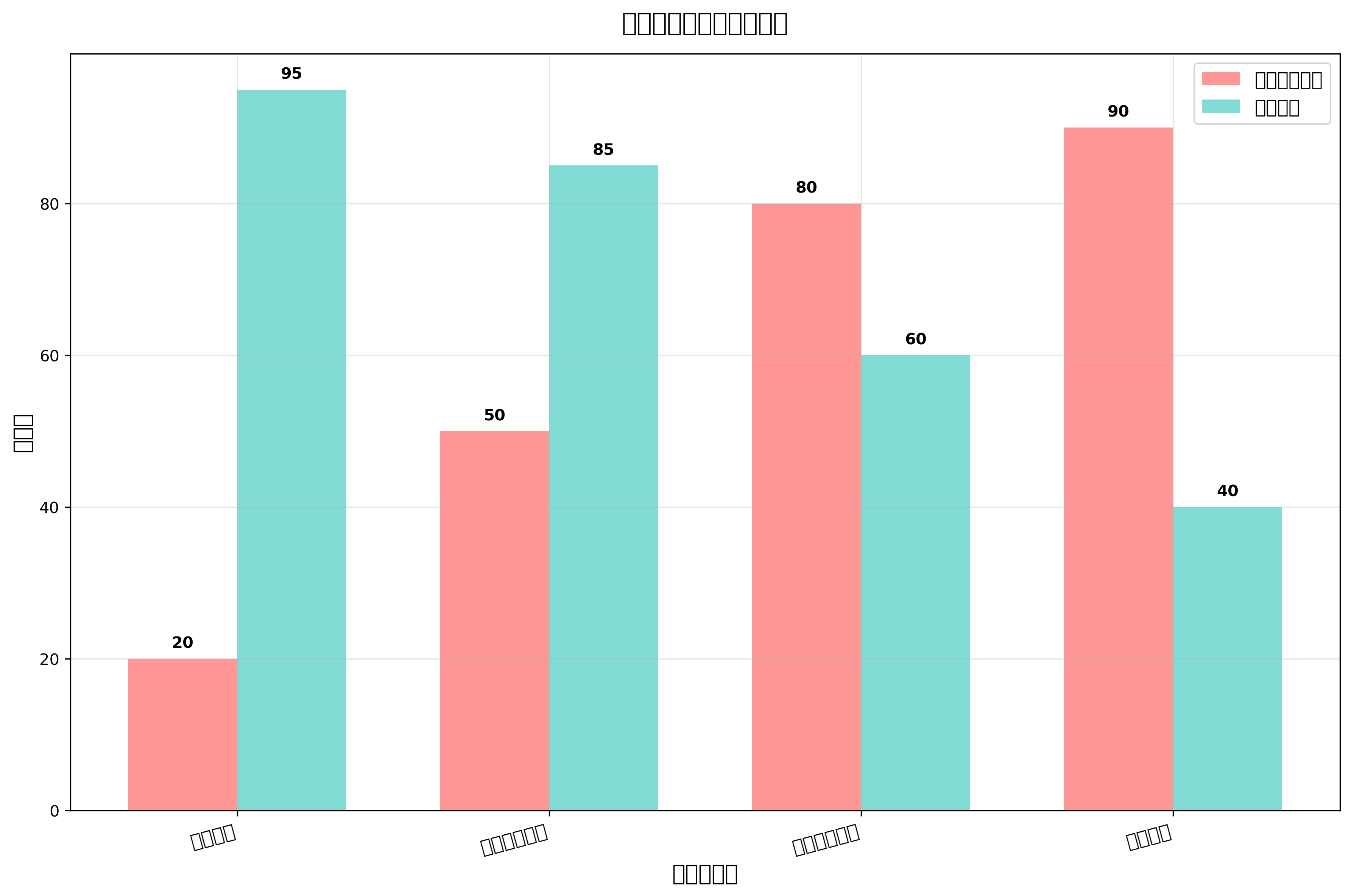
特徴量選択と前処理
分類の性能を向上させるためには、適切な特徴量選択が極めて重要です。特徴量選択は、分類に最も有用な変数を識別し、不要な変数を除去するプロセスです。これにより、計算効率の向上、過学習の防止、モデルの解釈しやすさの向上が期待できます。
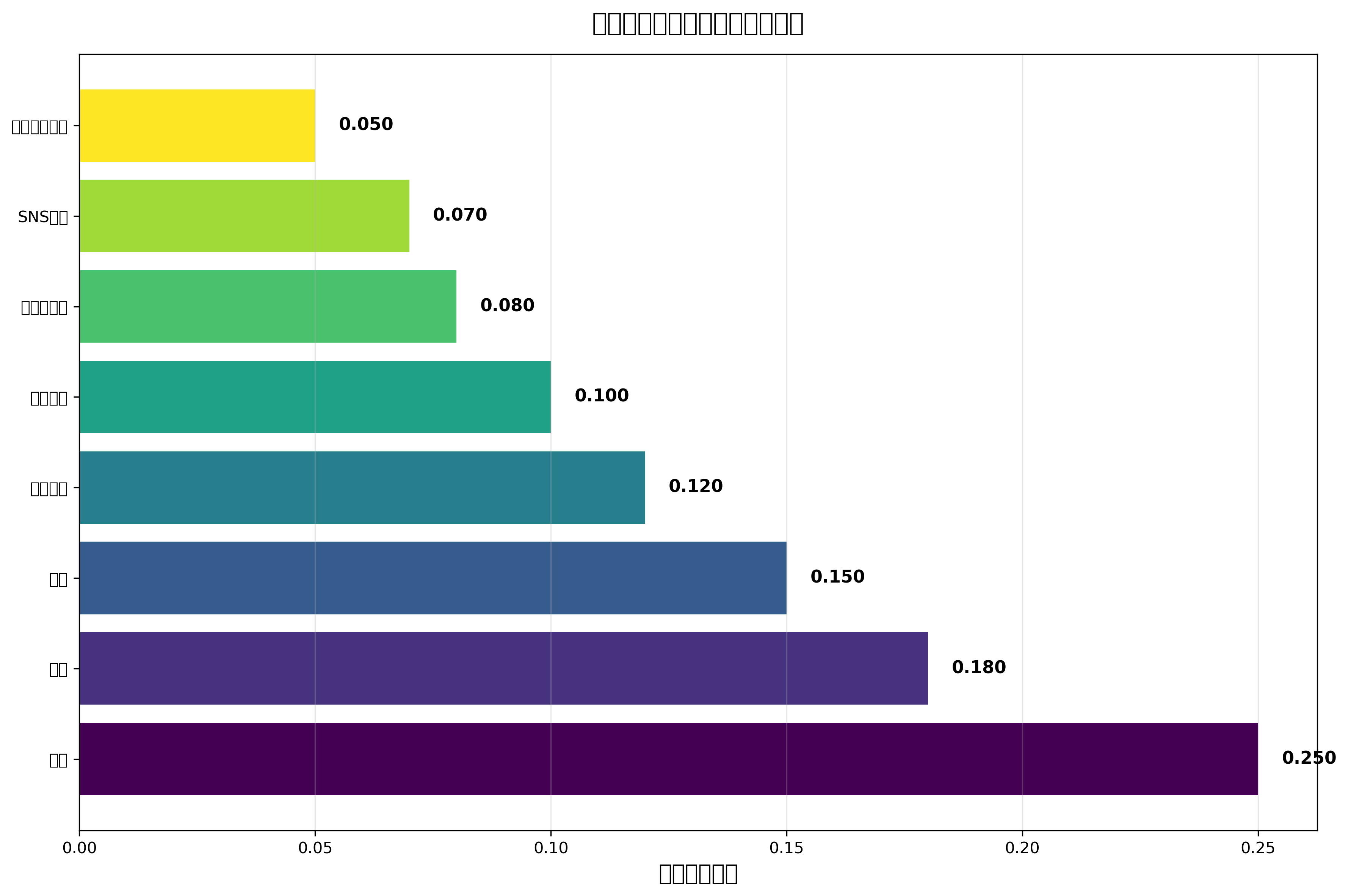
特徴量選択の手法には、統計的検定に基づく方法、情報理論に基づく方法、機械学習モデルに基づく方法などがあります。統計的検定では、各特徴量とターゲット変数の相関性を評価し、有意性の高い特徴量を選択します。情報理論に基づく方法では、相互情報量やエントロピーを用いて、特徴量の情報価値を評価します。
データの前処理も分類性能に大きな影響を与えます。欠損値の処理、外れ値の検出と処理、正規化やスケーリングなどが重要な前処理ステップです。特に、異なる尺度の特徴量が混在する場合、適切な正規化を行わないとアルゴリズムの性能が大幅に低下する可能性があります。効率的なデータ前処理には、データクリーニングツールやデータ変換ソフトウェアの活用が有効です。
次元削減も重要な前処理技術の一つです。高次元データでは、次元の呪いと呼ばれる現象により分類性能が低下することがあります。主成分分析(PCA)や線形判別分析(LDA)などの次元削減手法を用いることで、データの本質的な構造を保ちながら次元数を削減できます。
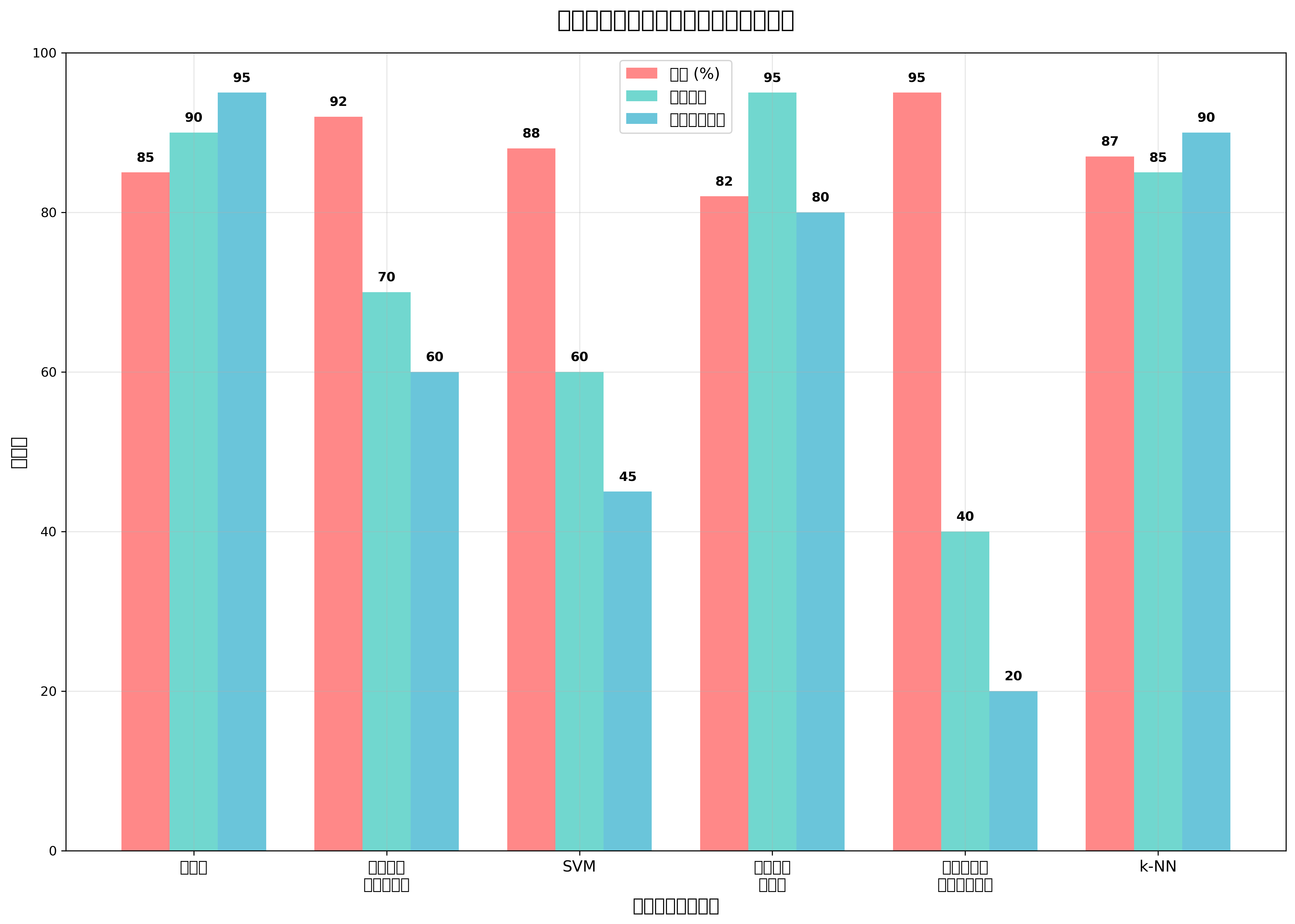
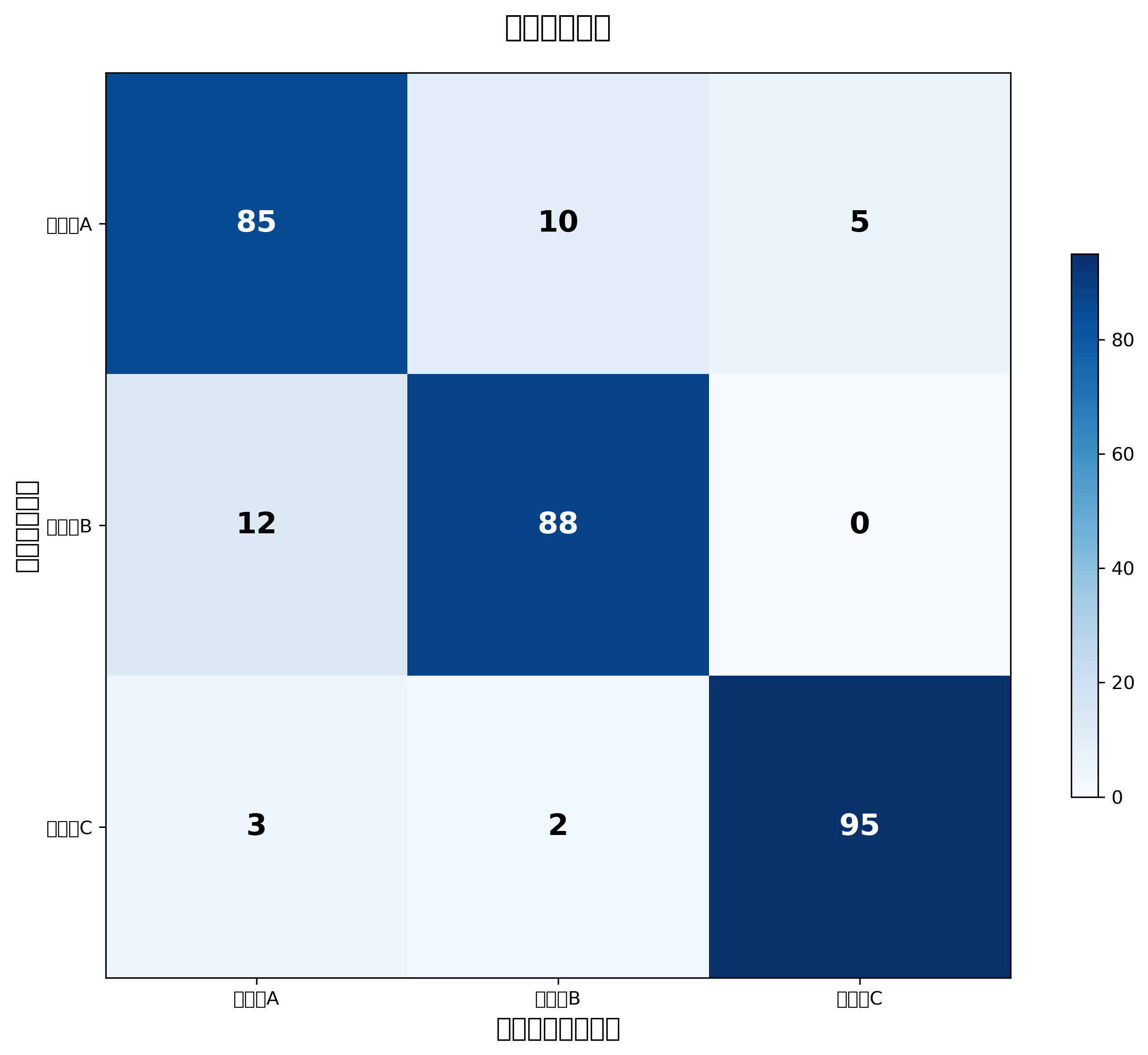
性能評価と検証手法
分類モデルの性能評価は、実用的なシステムを構築するために欠かせないプロセスです。最も基本的な評価指標は正解率(Accuracy)ですが、データの分布が偏っている場合には適切でない場合があります。そのような状況では、適合率(Precision)、再現率(Recall)、F1スコアなどの指標が重要になります。
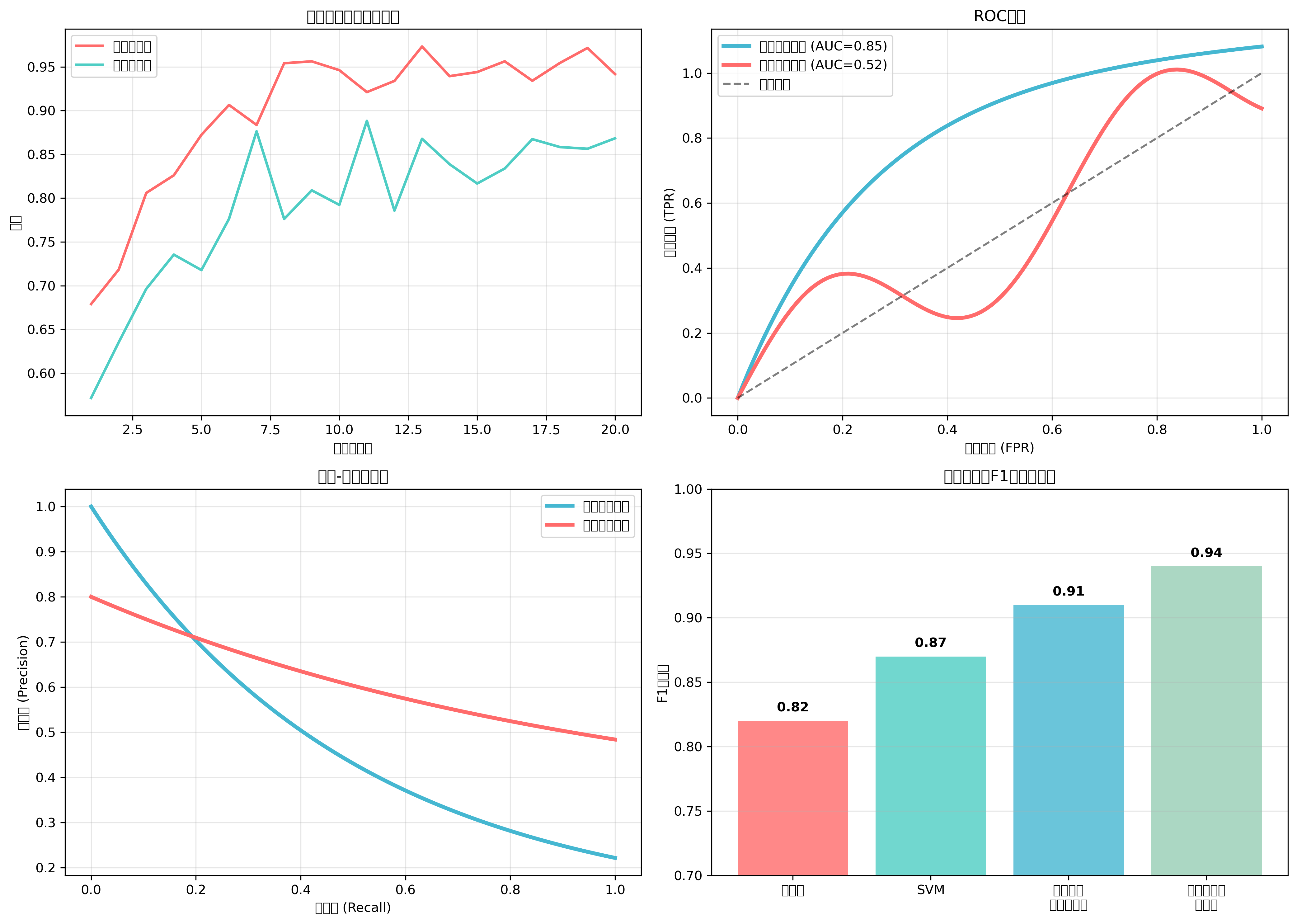
適合率は、陽性と予測したサンプルのうち実際に陽性だったものの割合を示し、再現率は実際の陽性サンプルのうち正しく陽性と予測できたものの割合を示します。F1スコアは適合率と再現率の調和平均で、両方をバランスよく評価する指標です。これらの指標を正確に計算し分析するため、性能評価ツールや統計分析パッケージの導入が推奨されます。
ROC曲線とAUC(Area Under Curve)は、二値分類の性能を包括的に評価する手法です。ROC曲線は、偽陽性率と真陽性率の関係をプロットしたもので、AUCはその曲線の下の面積を表します。AUCが1に近いほど優秀な分類器であることを示します。
交差検証は、モデルの汎化性能を評価するための重要な手法です。データをk個のグループに分割し、そのうちk-1個を学習に使用し、残りの1個をテストに使用します。これをk回繰り返すことで、より信頼性の高い性能評価が可能になります。実際の開発現場では、交差検証ツールやモデル検証フレームワークが広く活用されています。
実用的な応用例
分類技術は、現代社会の様々な分野で実用的に活用されています。電子商取引では、顧客の購買行動データを基に顧客セグメンテーションを行い、パーソナライズされたマーケティングを実現しています。また、商品レビューの感情分析により、ブランドイメージの監視や商品改善の指標として活用されています。
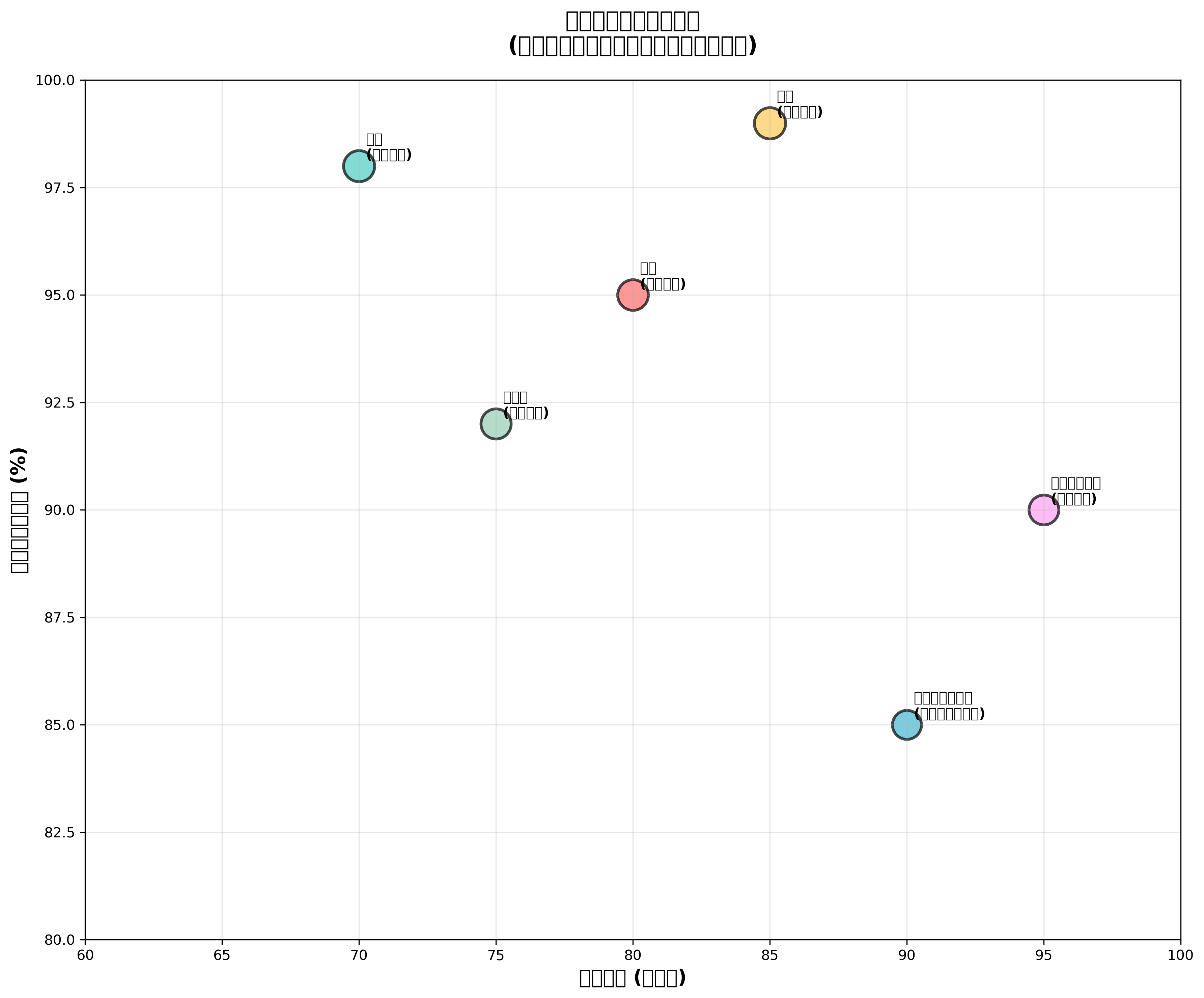
金融業界では、クレジットスコアリング、不正取引検出、投資リスク評価などに分類技術が活用されています。特に不正取引検出では、リアルタイムでの高精度な分類が求められるため、リアルタイム分析システムや高速データ処理プラットフォームの導入が重要です。
医療分野では、画像診断支援、疾患の早期発見、薬剤の効果予測などに分類技術が応用されています。医療画像の分類では、畳み込みニューラルネットワーク(CNN)が特に優秀な性能を示しており、放射線科医の診断支援として実用化が進んでいます。医療データの分析には、医療用画像解析ソフトや医療統計ソフトウェアが必要不可欠です。
製造業では、品質管理、予知保全、生産最適化に分類技術が活用されています。センサーデータから設備の異常を早期発見し、計画的なメンテナンスを実施することで、ダウンタイムの削減とコスト効率の向上を実現しています。これらのシステムには、IoTデータ分析プラットフォームや予知保全システムが導入されています。
分類技術の最新動向
近年の分類技術は、深層学習の発展により大きく進歩しています。特に、畳み込みニューラルネットワーク(CNN)は画像分類の分野で革命的な成果を上げ、人間の認識精度を上回る性能を実現しています。また、リカレントニューラルネットワーク(RNN)やトランスフォーマーは、時系列データやテキストデータの分類において優秀な性能を示しています。
転移学習は、分類技術の実用性を大幅に向上させた重要な技術です。事前に大規模なデータセットで学習されたモデルを、特定のタスクに適用することで、少ないデータでも高性能な分類器を構築できます。この技術により、中小企業でも高度な分類システムを比較的容易に導入できるようになりました。転移学習の実装には、深層学習ライブラリや事前学習モデルの活用が不可欠です。
アンサンブル学習も重要な技術トレンドの一つです。複数の分類器の予測を組み合わせることで、個々の分類器よりも高い性能を実現できます。バギング、ブースティング、スタッキングなどの手法があり、実用的なシステムで広く採用されています。
説明可能AI(Explainable AI)は、分類モデルの予測根拠を人間が理解できる形で提示する技術です。金融や医療などの規制が厳しい分野では、AIの判断根拠を説明することが法的に求められる場合があり、この技術の重要性が高まっています。説明可能AIの実装には、AI解釈性ツールや可視化ソフトウェアの活用が有効です。
応用情報技術者試験での出題傾向
応用情報技術者試験において、分類技術は午前問題と午後問題の両方で出題される重要な分野です。午前問題では、各種分類アルゴリズムの特徴、評価指標の計算、前処理手法などが問われます。特に、決定木、SVM、ニューラルネットワークの基本概念と特徴を理解しておくことが重要です。
午後問題では、具体的なビジネスシーンでの分類技術の応用が問われます。顧客分析、リスク評価、品質管理などの文脈で、適切なアルゴリズムの選択、評価指標の解釈、システム設計などが出題されます。これらの問題に対応するためには、理論的な知識だけでなく、実践的な応用例を理解しておくことが必要です。
試験対策としては、応用情報技術者試験の参考書や機械学習の基本書を活用して、理論と実践のバランスを取った学習が効果的です。また、過去問題集を繰り返し解くことで、出題パターンを把握し、時間配分の練習を積むことが重要です。
実際の業務経験がある場合は、自社のデータ分析事例を分類技術の観点から分析し、改善提案を考える練習も有効です。また、実習用データセットを使って実際に分類モデルを構築してみることで、理論と実践の橋渡しができます。
実装時の注意点とベストプラクティス
分類システムを実装する際には、いくつかの重要な注意点があります。まず、データの品質確保が最重要課題です。不完全なデータや偏ったデータでは、どれほど優秀なアルゴリズムを使用しても良い結果は得られません。データ収集の段階から品質管理を徹底し、データ品質管理ツールを活用することが推奨されます。
過学習の防止も重要な課題です。学習データに過度に適合したモデルは、新しいデータに対する汎化性能が低下します。正則化手法の適用、交差検証による性能評価、適切な学習データ量の確保などにより過学習を防ぐことができます。
スケーラビリティも考慮すべき重要な要素です。小規模なデータでは高性能を示すアルゴリズムも、大規模データでは計算時間やメモリ使用量の制約により実用的でない場合があります。システム設計の初期段階から、予想されるデータ量と計算リソースを考慮した設計が必要です。大規模データの処理には、分散処理フレームワークやクラウド分析サービスの活用が効果的です。
継続的なモデル改善のためのMLOps(Machine Learning Operations)の実装も重要です。本番環境でのモデル性能の監視、新しいデータによる再学習、A/Bテストによる効果測定などを自動化することで、分類システムの継続的な改善が可能になります。
まとめ
分類技術は、現代の情報社会における中核的な技術として、様々な分野で重要な役割を果たしています。基本的な二値分類から複雑な多クラス・多ラベル分類まで、問題の性質に応じて適切な手法を選択することが成功の鍵となります。応用情報技術者試験においても重要な出題分野であり、理論的な理解と実践的な応用能力の両方が求められます。
技術の進歩により、深層学習、転移学習、説明可能AIなどの新しい手法が登場し、分類技術の可能性はさらに広がっています。これらの最新技術を効果的に活用するためには、基本的な分類理論の理解が不可欠です。また、実装時には、データ品質の確保、過学習の防止、スケーラビリティの考慮など、多面的な検討が必要です。
今後も分類技術は進歩を続け、より高精度で効率的な手法が開発されることが期待されます。継続的な学習と実践により、変化する技術動向に対応できる能力を身につけることが、この分野で成功するための重要な要素となります。