現代のコンピュータシステムにおいて、処理性能の向上は終わることのない追求です。その中でも、キャッシュメモリは最も重要な技術の一つとして位置づけられています。応用情報技術者試験でも頻出の重要トピックであり、コンピュータアーキテクチャを理解する上で欠かせない知識です。キャッシュメモリの仕組みを理解することで、なぜ現代のコンピュータが高速に動作できるのか、その核心を掴むことができます。
キャッシュメモリとは、CPUと主記憶装置(メインメモリ)の間に配置される高速なメモリのことです。CPUが頻繁にアクセスするデータや命令を一時的に格納し、メインメモリへのアクセス回数を減らすことで、システム全体の処理速度を大幅に向上させる役割を果たします。この技術により、理論的には数百倍から数千倍もの性能向上が実現可能となっています。
メモリ階層における位置づけと重要性
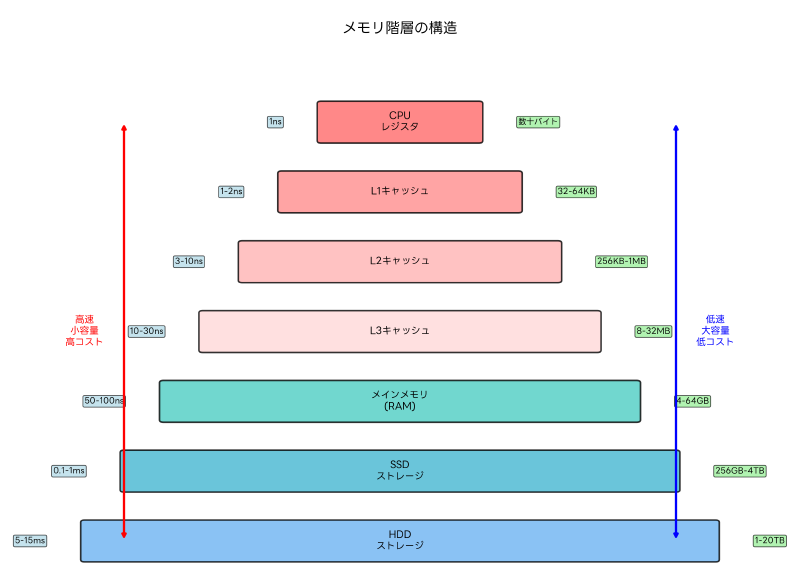
コンピュータのメモリシステムは階層構造を持っており、キャッシュメモリはその中核を担っています。CPUに最も近い場所に位置するレジスタから始まり、L1キャッシュ、L2キャッシュ、L3キャッシュ、メインメモリ、そして外部記憶装置まで、段階的に容量が大きくなり、アクセス速度が遅くなる構造となっています。
この階層構造において、キャッシュメモリは「局所性の原理」を活用してシステム性能を向上させます。局所性の原理には時間的局所性と空間的局所性があります。時間的局所性とは、最近アクセスされたデータが再びアクセスされる傾向のことで、空間的局所性とは、あるデータがアクセスされると、その近くのデータもアクセスされる傾向のことです。
現代の[高性能プロセッサ](https://www.amazon.co.jp/s?k=Intel Core i9 プロセッサ&tag=amazon-product-items-22)では、複数レベルのキャッシュが搭載されており、それぞれが異なる役割を担っています。L1キャッシュは最も高速でCPUコアに直結しており、[専門的なCPU解説書](https://www.amazon.co.jp/s?k=CPU アーキテクチャ 解説書&tag=amazon-product-items-22)によると、通常1サイクルでアクセス可能な設計となっています。
メモリ階層の設計思想は、コストパフォーマンスの最適化にあります。高速なメモリは製造コストが高く、大容量化が困難です。一方、低速なメモリは安価で大容量化が容易です。キャッシュメモリは、この相反する要求を巧みに調和させ、実用的な性能とコストのバランスを実現しています。
キャッシュの効果を最大化するためには、適切なメモリ管理ツールの活用も重要です。システム管理者は、パフォーマンス監視ソフトウェアを使用してキャッシュの動作状況を詳細に分析し、システムの最適化を図ることができます。
L1、L2、L3キャッシュの特徴と役割分担
現代のマルチレベルキャッシュシステムでは、各レベルが異なる特徴を持ち、相互補完的に動作します。L1キャッシュは最も高速で、通常は命令キャッシュ(I-cache)とデータキャッシュ(D-cache)に分離されています。この分離により、CPUが同時に命令とデータにアクセスできるため、パイプライン処理の効率が向上します。
L1キャッシュの容量は通常16KBから64KB程度と小さく設定されています。これは、容量を小さくすることでアクセス速度を最大化するためです。最新のワークステーションでは、L1キャッシュのヒット率が98%以上を達成することも珍しくありません。
L2キャッシュは統合キャッシュとして設計されることが多く、命令とデータを区別せずに格納します。容量は256KBから1MB程度で、L1キャッシュでヒットしなかったアクセスを処理します。L2キャッシュのアクセス時間は通常3から10サイクル程度で、L1キャッシュほどではありませんが、メインメモリと比較すると圧倒的に高速です。
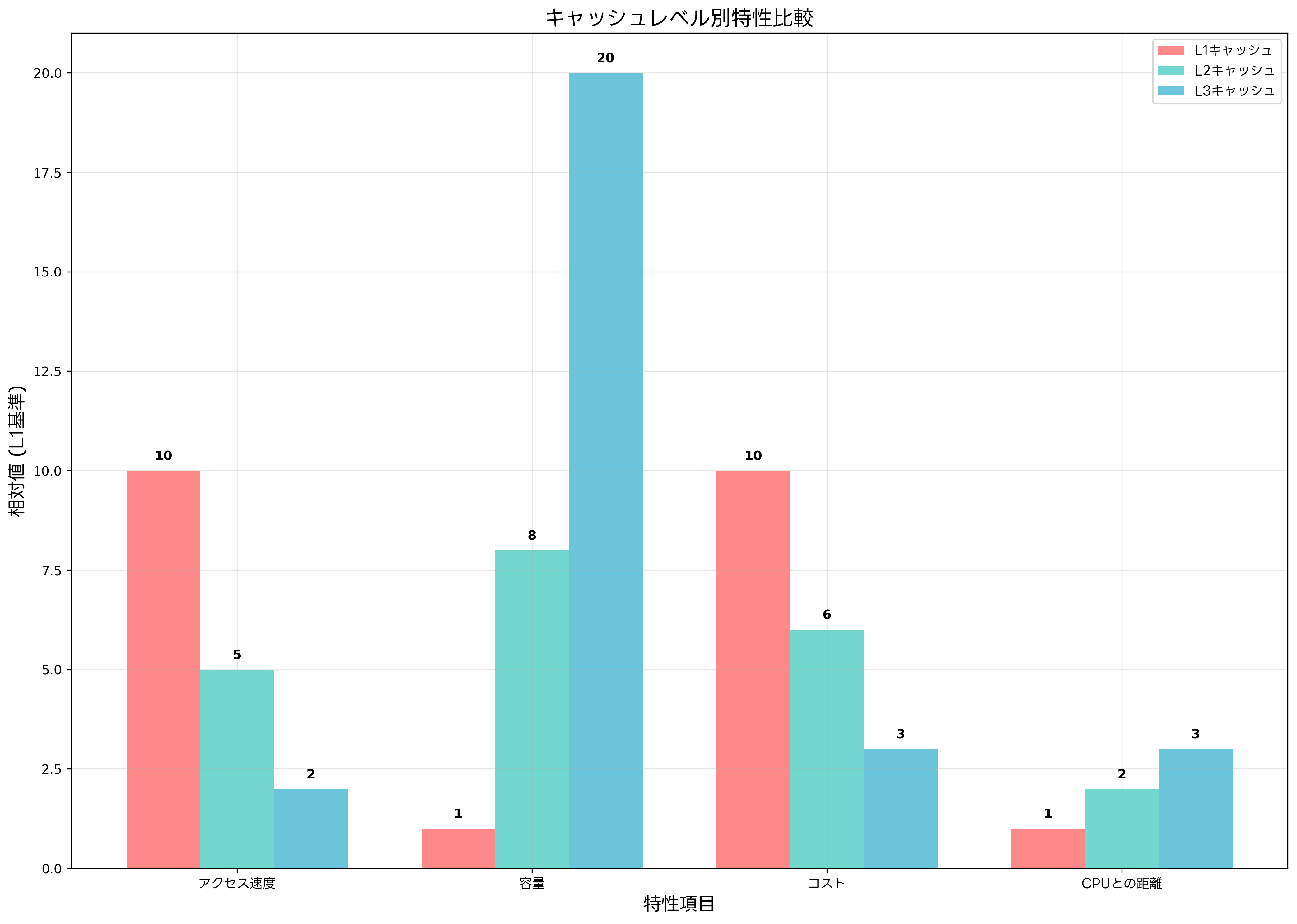
L3キャッシュは複数のCPUコア間で共有されることが一般的で、8MBから32MB程度の大容量を持ちます。このレベルでは、コア間でのデータ共有やキャッシュコヒーレンシの維持が重要な役割となります。L3キャッシュは、[サーバー用途の高性能CPU](https://www.amazon.co.jp/s?k=Xeon プロセッサ&tag=amazon-product-items-22)において特に重要で、データベースサーバーやWebサーバーなどの用途で威力を発揮します。
各レベルのキャッシュは包含的(Inclusive)または排他的(Exclusive)な関係を持ちます。包含的キャッシュでは、上位レベルのデータが下位レベルにも存在し、排他的キャッシュでは各レベルが独立したデータを保持します。コンピュータアーキテクチャの専門書では、これらの設計思想について詳細に解説されています。
キャッシュの設計においては、レイテンシとスループットの最適化が重要です。高性能メモリモジュールとの連携により、キャッシュミス時のペナルティを最小化し、全体的な性能向上を実現しています。
キャッシュの動作原理とアルゴリズム
キャッシュメモリの動作は、アドレスマッピング、データの読み書き、置換アルゴリズムの三つの要素で構成されています。アドレスマッピングには、ダイレクトマップ、フルアソシアティブ、セットアソシアティブの三つの方式があります。
ダイレクトマップ方式は最もシンプルで、メインメモリの特定のアドレスが常にキャッシュの同じ位置にマップされます。実装が簡単で高速ですが、競合によるキャッシュミスが発生しやすいという欠点があります。一方、フルアソシアティブ方式では、データをキャッシュの任意の位置に格納できるため、競合は少なくなりますが、検索処理が複雑になります。
セットアソシアティブ方式は、上記二つの方式の折衷案として開発されました。キャッシュをセットに分割し、各セット内では任意の位置に格納できる方式です。2-way、4-way、8-wayなどの構成があり、現代の[高性能CPU](https://www.amazon.co.jp/s?k=AMD Ryzen プロセッサ&tag=amazon-product-items-22)では8-wayセットアソシアティブが一般的に採用されています。
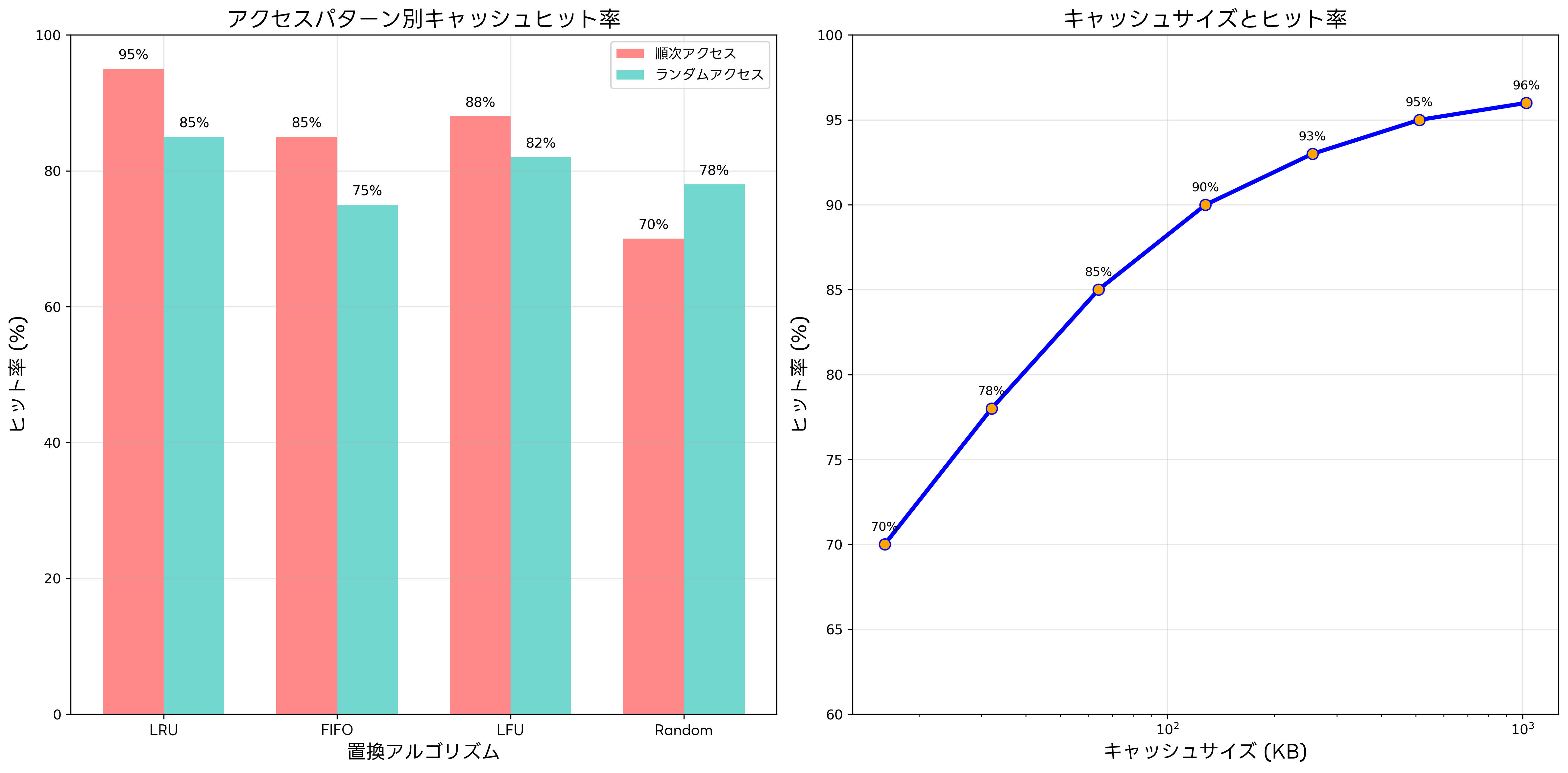
キャッシュが満杯になった際の置換アルゴリズムも重要な要素です。LRU(Least Recently Used)は最も古いデータを置き換える方式で、時間的局所性を考慮した効率的なアルゴリズムです。FIFO(First In, First Out)は実装が簡単ですが、必ずしも最適ではありません。LFU(Least Frequently Used)は使用頻度の低いデータを置き換える方式です。
現代のプロセッサでは、これらのアルゴリズムを組み合わせたハイブリッド方式や、機械学習を活用した予測的な置換アルゴリズムも研究されています。[キャッシュアルゴリズムの研究書](https://www.amazon.co.jp/s?k=キャッシュアルゴリズム 研究&tag=amazon-product-items-22)では、最新の研究成果について詳しく説明されています。
キャッシュの書き込み方式には、ライトスルー(Write-Through)とライトバック(Write-Back)があります。ライトスルー方式では、キャッシュとメインメモリの両方に同時に書き込むため、データの整合性は保たれますが、書き込み処理が遅くなります。ライトバック方式では、まずキャッシュのみに書き込み、後でメインメモリに反映させるため高速ですが、データの管理が複雑になります。
プリフェッチ機能も重要な最適化技術です。CPUが将来アクセスするであろうデータを事前にキャッシュに読み込むことで、キャッシュミスを予防します。[プリフェッチ対応のSSD](https://www.amazon.co.jp/s?k=NVMe SSD&tag=amazon-product-items-22)と組み合わせることで、さらなる性能向上が期待できます。
現代プロセッサにおけるキャッシュ構成
現代のマルチコアプロセッサでは、複雑なキャッシュ階層が構築されています。各CPUコアには専用のL1およびL2キャッシュが配置され、L3キャッシュは全コアで共有される構成が一般的です。この設計により、コア固有の処理は高速に実行し、コア間でのデータ共有も効率的に行えます。
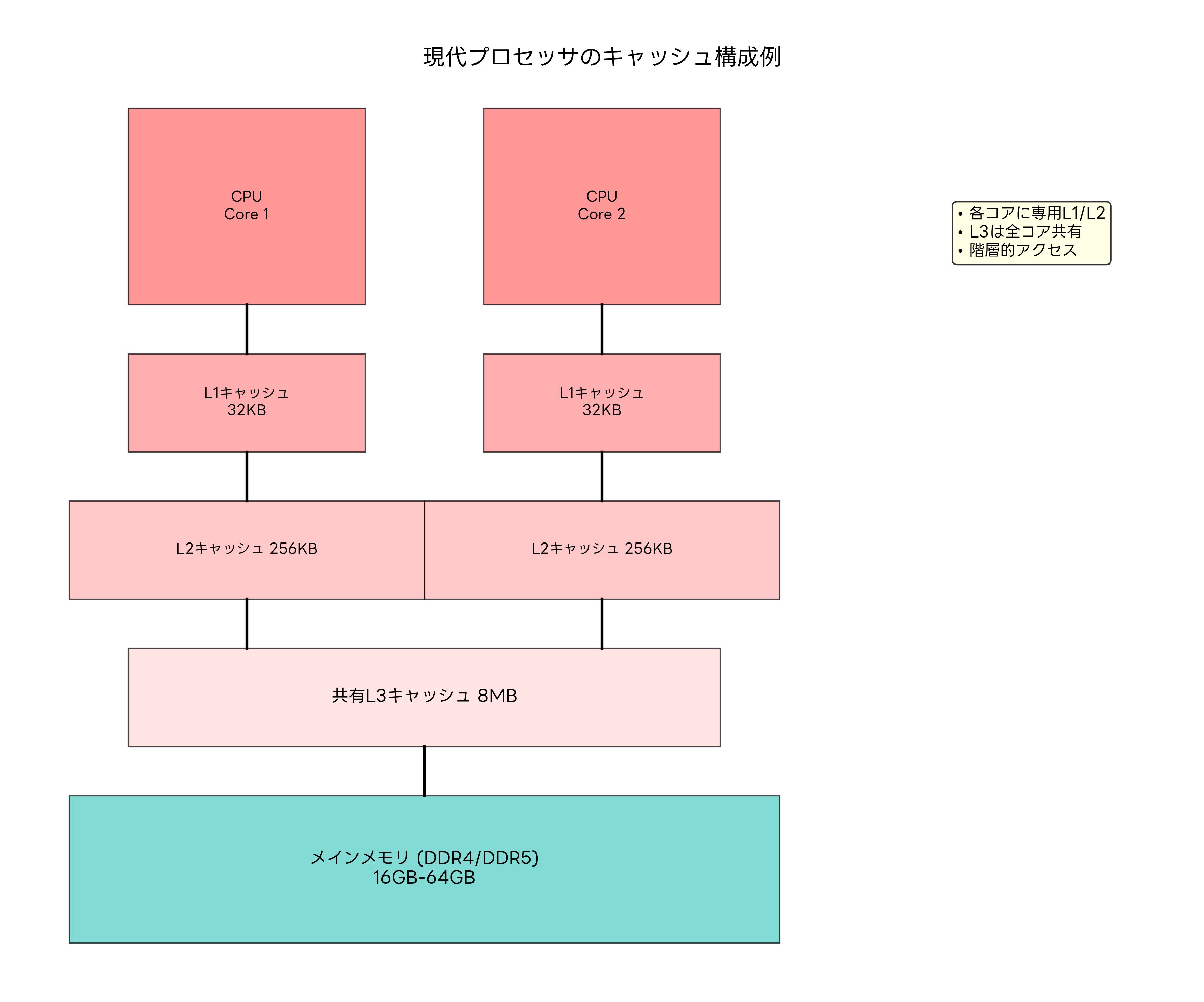
キャッシュコヒーレンシ(Cache Coherency)は、マルチコア環境での重要な課題です。複数のコアが同じデータのコピーを持つ場合、一つのコアがデータを変更すると、他のコアのキャッシュとの整合性を保つ必要があります。MESI(Modified, Exclusive, Shared, Invalid)プロトコルなどの仕組みにより、この問題が解決されています。
[マルチコア対応の開発書](https://www.amazon.co.jp/s?k=マルチコア プログラミング&tag=amazon-product-items-22)では、キャッシュコヒーレンシを考慮した効率的なプログラミング手法について詳しく解説されています。
Non-Uniform Memory Access(NUMA)アーキテクチャでは、メモリアクセスの局所性がさらに重要になります。各CPUソケットに専用のメモリコントローラが配置され、ローカルメモリへのアクセスが高速化されます。NUMA対応のサーバーでは、適切なメモリ配置により大幅な性能向上が実現できます。
ハイパースレッディング技術では、物理的な一つのコアが複数の論理的なコアとして動作します。この場合、L1およびL2キャッシュは論理コア間で共有されるため、キャッシュの効率的な利用がより重要になります。[ハイパースレッディング対応CPU](https://www.amazon.co.jp/s?k=インテル ハイパースレッディング&tag=amazon-product-items-22)では、適切なワークロード配置により性能を最大化できます。
キャッシュ性能の測定と最適化
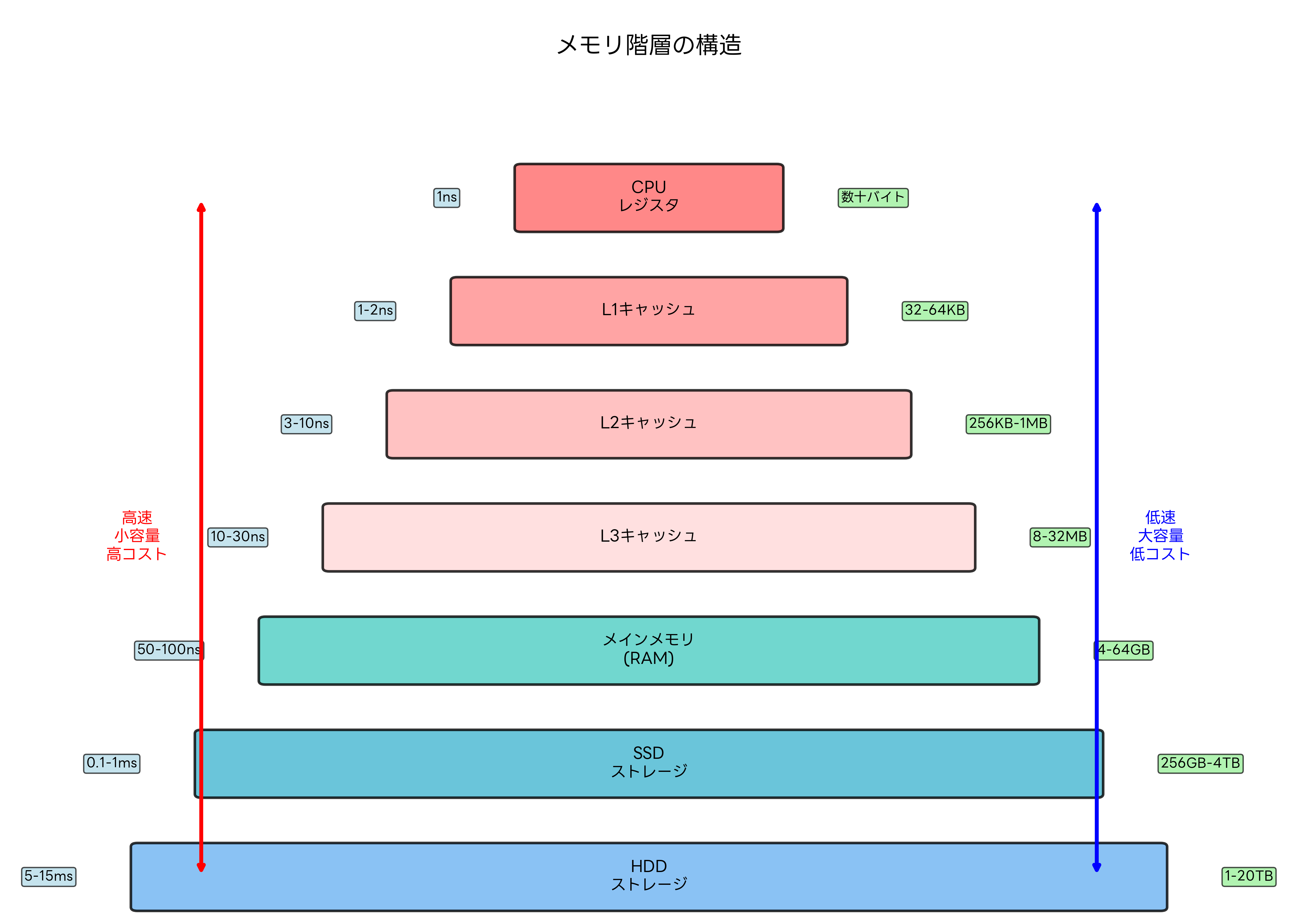
キャッシュの性能評価には、ヒット率、ミス率、平均メモリアクセス時間(AMAT: Average Memory Access Time)などの指標が用いられます。ヒット率は、キャッシュからデータを取得できた割合を示し、通常は90%以上の値が期待されます。ミス率はヒット率の逆数で、1からヒット率を引いた値です。
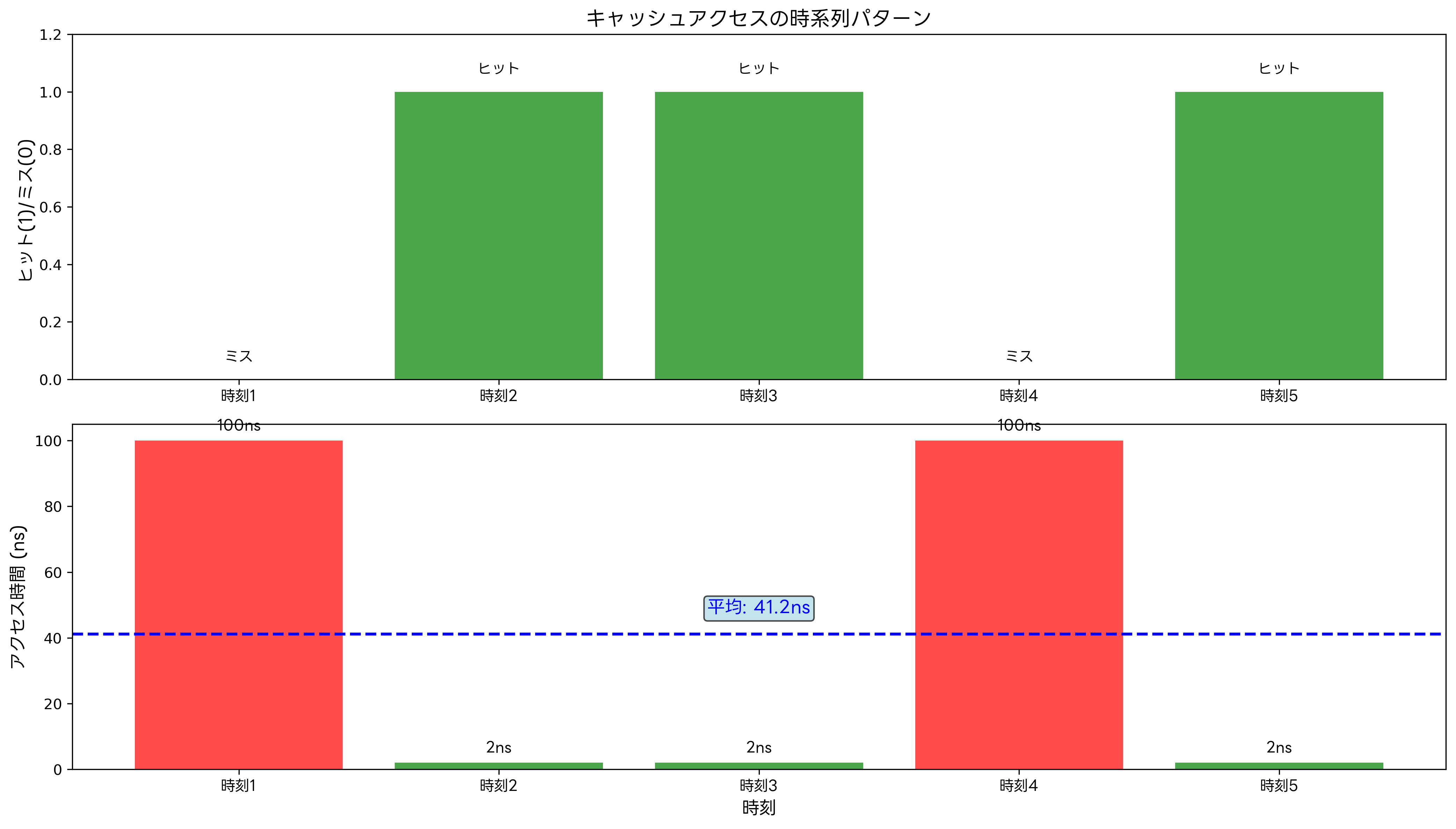
平均メモリアクセス時間の計算式は「AMAT = ヒット時間 + ミス率 × ミスペナルティ」で表されます。この式から、ヒット率の向上がシステム性能に与える影響の大きさが理解できます。例えば、ヒット率が90%から95%に向上すると、AMATは大幅に改善されます。
システムパフォーマンス測定ツールを使用することで、実際のワークロードでのキャッシュ効率を詳細に分析できます。Windows環境ではパフォーマンスモニターツール、Linux環境では[システム監視ツール](https://www.amazon.co.jp/s?k=Linux システム監視&tag=amazon-product-items-22)が有効です。
キャッシュ最適化のプログラミング技法として、データ構造の工夫があります。配列の要素を順次アクセスすることで空間的局所性を活用したり、頻繁に使用される変数を近い位置に配置することで時間的局所性を向上させたりできます。高性能コンピューティングの専門書では、このような最適化技法が豊富に紹介されています。
コンパイラレベルでの最適化も重要です。ループアンローリング、データプリフェッチ、キャッシュブロッキングなどの技法により、コンパイラがキャッシュフレンドリーなコードを生成できます。最適化コンパイラの解説書では、これらの技術について詳細に説明されています。
仮想メモリとの関係
キャッシュメモリは仮想メモリシステムと密接に関連しています。仮想アドレスから物理アドレスへの変換処理もキャッシュされる必要があり、TLB(Translation Lookaside Buffer)というアドレス変換専用のキャッシュが使用されます。TLBのヒット率が低いと、ページテーブルへのアクセスが頻発し、システム性能が大幅に低下します。
ページフォルト処理においても、キャッシュの考慮が重要です。新しいページがメモリにロードされる際、関連するキャッシュラインが無効化され、しばらくの間はキャッシュミスが多発する可能性があります。仮想メモリ管理の専門書では、このような現象への対処法が詳しく解説されています。
大容量メモリを搭載したサーバーシステムでは、メモリ管理の重要性がさらに高まります。適切なメモリ配置とキャッシュ戦略により、大規模なデータ処理でも高い性能を維持できます。
応用情報技術者試験での出題傾向と対策
応用情報技術者試験においては、キャッシュメモリに関する問題が午前問題、午後問題ともに継続的に出題されています。特に、コンピュータシステムの分野では、キャッシュの仕組み、性能計算、最適化手法などが頻繁に問われます。
午前問題では、キャッシュの基本概念、ヒット率とアクセス時間の計算、キャッシュアルゴリズムの特徴などが出題されます。例えば、「キャッシュヒット率が90%、キャッシュアクセス時間が2ns、メインメモリアクセス時間が100nsの場合の平均アクセス時間を求めよ」といった計算問題がよく出題されます。
午後問題では、より実践的なシステム設計や性能分析の文脈でキャッシュが取り上げられます。Webサーバーの性能向上策として、データベースシステムの最適化として、あるいは組み込みシステムのリアルタイム性向上策として、キャッシュ技術の活用が問われることがあります。
応用情報技術者試験の参考書では、キャッシュメモリの章で体系的に学習できます。また、過去問題集を活用して、出題パターンを把握することが重要です。
実務経験がある場合は、自社システムのキャッシュ戦略を分析し、改善提案を考える練習も効果的です。システム性能分析ツールを使用して、実際のキャッシュ動作を観察することで、理論と実践を結びつけることができます。
最新技術動向と将来展望
キャッシュメモリ技術は現在も急速に進歩しています。3D積層技術により、より大容量のキャッシュを小さな面積で実現する技術が開発されています。また、不揮発性メモリ技術を活用したストレージクラスメモリが、従来のキャッシュ階層に新たなレイヤーを追加する可能性があります。
機械学習を活用したスマートキャッシュも注目されています。アクセスパターンを学習し、より精密なプリフェッチやより適切な置換判断を行うことで、従来のキャッシュアルゴリズムを上回る性能が期待されています。[AI技術の応用に関する書籍](https://www.amazon.co.jp/s?k=AI ハードウェア最適化&tag=amazon-product-items-22)では、このような最新動向が紹介されています。
エッジコンピューティングやIoTデバイスの普及により、低消費電力かつ高性能なキャッシュ設計の需要が高まっています。組み込みシステム用のメモリでは、電力効率を重視した新しいキャッシュアーキテクチャが求められています。
量子コンピューティングの発展に伴い、量子メモリを活用した全く新しいキャッシュ概念も研究されています。従来の制約を超えた性能向上の可能性があり、量子コンピューティングの入門書でその概要を学ぶことができます。
まとめ
キャッシュメモリは、現代コンピュータシステムの性能を支える基盤技術です。CPUとメインメモリ間の速度差を埋める重要な役割を果たし、局所性の原理を活用してシステム全体の処理速度を大幅に向上させています。L1、L2、L3の多層構造により、コストと性能のバランスを最適化し、実用的なシステムを実現しています。
応用情報技術者試験においても重要なトピックであり、基本原理から実践的な応用まで幅広い知識が求められます。キャッシュヒット率の計算、アルゴリズムの特徴、最適化手法などを体系的に理解することで、試験での高得点を狙うことができます。
技術の進歩とともに、キャッシュメモリも進化を続けています。3D積層技術、機械学習の活用、新しいメモリ技術の導入など、今後さらなる性能向上が期待されます。これらの最新動向を把握し、継続的な学習を通じて、変化する技術環境に対応できる能力を身につけることが重要です。