
大文字小文字区別(Case Sensitivity)は、コンピュータシステムにおいて大文字と小文字を異なる文字として扱うかどうかを決定する重要な概念です。この概念は、プログラミング言語、ファイルシステム、データベース、ユーザー認証、セキュリティなど、情報システムの様々な分野で重要な役割を果たします。応用情報技術者試験においても、システム設計やセキュリティの文脈で頻出する重要なトピックです。

現代の情報システムでは、大文字小文字区別の設定によってシステムの動作が大きく変わります。特に、マルチプラットフォーム対応のシステム開発やセキュリティ設計において、この概念の理解は欠かせません。開発者やシステム管理者は、対象とする環境の大文字小文字区別の特性を正確に把握し、適切な設計を行う必要があります。
大文字小文字区別の基本概念
大文字小文字区別には、大きく分けて二つのアプローチがあります。Case Sensitiveな環境では、大文字(A-Z)と小文字(a-z)が異なる文字として扱われます。例えば、「User」と「user」は完全に異なる識別子として認識されます。一方、Case Insensitiveな環境では、大文字と小文字は同じ文字として扱われ、「User」と「user」は同一の識別子として認識されます。
この違いは、文字列の比較処理において特に重要になります。Case Sensitiveな環境では、文字列比較の際にASCII値やUnicode値を直接比較するため、処理が高速になる傾向があります。しかし、Case Insensitiveな環境では、比較前に文字列を統一的な形式(通常は小文字)に変換する処理が必要となり、若干のオーバーヘッドが発生します。
プログラミングにおいて、大文字小文字区別は変数名、関数名、クラス名などの識別子の扱いに直接影響します。プログラミング学習書籍を参照すると、多くの言語では大文字小文字を区別することが分かります。例えば、Javaでは「myVariable」と「MyVariable」は別々の変数として扱われます。これにより、より表現力豊かなコードを書くことができる反面、誤入力によるバグが発生しやすくなるというトレードオフがあります。
大文字小文字区別の概念は、国際化(i18n)の観点からも重要です。英語以外の言語、特に大文字小文字の概念がない言語(例:中国語、日本語のひらがな・カタカナ)や、複雑な大文字小文字ルールを持つ言語(例:ドイツ語のエスツェット)を扱う際には、特別な配慮が必要になります。国際化対応プログラミングガイドでは、このような複雑なケースへの対応方法が詳しく説明されています。
ファイルシステムでの大文字小文字区別
ファイルシステムにおける大文字小文字区別は、オペレーティングシステムによって大きく異なります。この違いは、クロスプラットフォーム開発において重要な考慮事項となります。
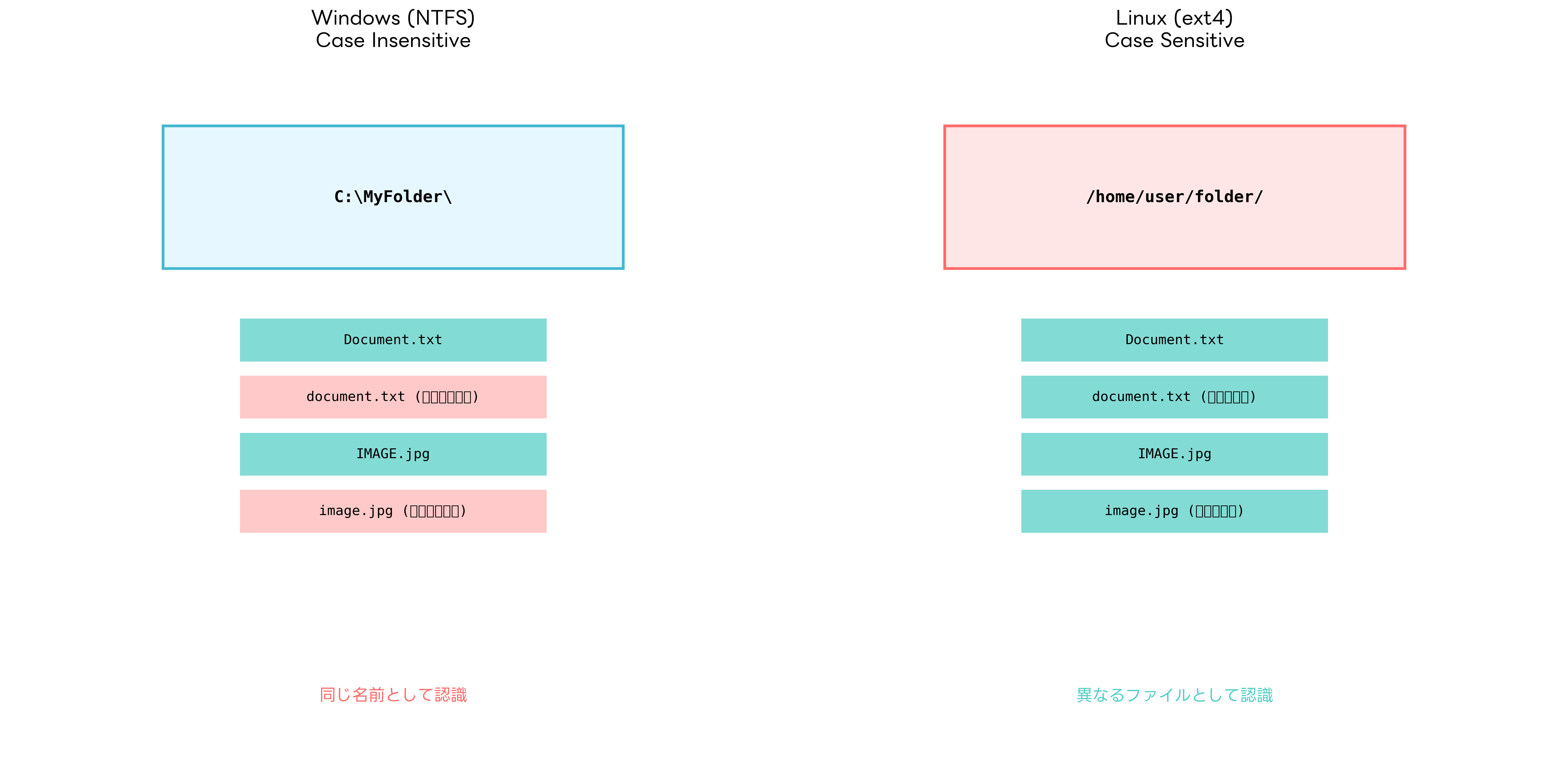
Windows系のファイルシステム(NTFS、FAT32)は、基本的にCase Insensitiveです。つまり、「Document.txt」と「document.txt」は同じファイルとして扱われ、同一ディレクトリに両方のファイルを作成することはできません。しかし、興味深いことに、NTFSは内部的には大文字小文字を保持しています。これは「Case Preserving」と呼ばれる機能で、ファイル名を「Document.txt」で作成すると、その大文字小文字の形式が保存されます。ただし、アクセス時には大文字小文字の違いは無視されます。
一方、Unix系システム(Linux、macOS、BSD)のファイルシステムは、一般的にCase Sensitiveです。ext4、XFS、ZFSなどのファイルシステムでは、「Document.txt」と「document.txt」は完全に異なるファイルとして扱われ、同一ディレクトリに両方を配置することができます。これにより、より柔軟なファイル命名が可能になる反面、混乱やミスの原因となることもあります。
macOSは特殊なケースです。macOSのデフォルトファイルシステムであるAPFSは、Case Insensitiveがデフォルト設定ですが、Case Sensitiveモードでフォーマットすることも可能です。この柔軟性により、開発者は必要に応じて動作を選択できます。Mac開発環境構築ガイドでは、この設定方法と注意点が詳しく解説されています。
ファイルシステムの大文字小文字区別は、Webサーバーの動作にも大きな影響を与えます。LinuxベースのWebサーバーでは、URLとファイルパスの大文字小文字が厳密に一致する必要があります。例えば、「/Images/photo.jpg」というURLでアクセスした場合、サーバー上に「/images/photo.jpg」というファイルが存在していても、404エラーが発生します。この問題を解決するため、Webサーバー設定ガイドや.htaccessリライトルール参考書を活用した適切な設定が必要です。
クラウドストレージサービスも、プロバイダーによって大文字小文字区別の扱いが異なります。Amazon S3は大文字小文字を区別しますが、Microsoft OneDriveは区別しません。このような違いを理解し、適切に対応するためには、クラウドストレージ開発ガイドなどの専門書籍を参考にすることが重要です。
プログラミング言語での大文字小文字区別
プログラミング言語における大文字小文字区別は、言語設計の基本的な特徴の一つです。大部分の現代的なプログラミング言語は、Case Sensitiveな設計を採用しています。

Java、C#、Python、JavaScript、C++、Ruby、PHP、Go、Rustなど、主要なプログラミング言語のほとんどがCase Sensitiveです。これらの言語では、変数名「userName」と「UserName」は完全に異なる識別子として扱われます。この特徴により、より表現力豊かで読みやすいコードを書くことができます。例えば、クラス名は大文字で始める(PascalCase)、変数名は小文字で始める(camelCase)といった命名規則を適用できます。
Java完全ガイドやPython実践プログラミングなどの専門書では、これらの言語での大文字小文字区別の重要性と、それを活用した効果的なコーディングスタイルが詳しく説明されています。
一方で、一部の古いプログラミング言語や特殊な用途の言語では、Case Insensitiveな設計を採用しているものもあります。例えば、Visual Basic .NET、Pascal、FORTRANなどは、大文字小文字を区別しません。これらの言語では、「MyVariable」と「myvariable」は同じ変数として扱われます。
SQLは興味深いケースです。標準SQLでは、識別子(テーブル名、カラム名など)は大文字小文字を区別しないことになっていますが、実際のデータベース管理システムの実装では、システムによって動作が異なります。MySQLはデフォルトでCase Insensitive、PostgreSQLは基本的にCase Sensitiveですが、引用符で囲まない識別子は小文字に変換されるという複雑な動作をします。
この複雑さに対応するため、SQLプログラミング実践ガイドやデータベース設計パターン集などの書籍を参考にして、ポータブルなSQLコードを書く技術を身につけることが重要です。
データベースシステムでの大文字小文字区別
データベースシステムにおける大文字小文字区別は、システム設計において特に注意が必要な分野です。データベース管理システム(DBMS)によって、テーブル名、カラム名、データ値の扱いが大きく異なります。
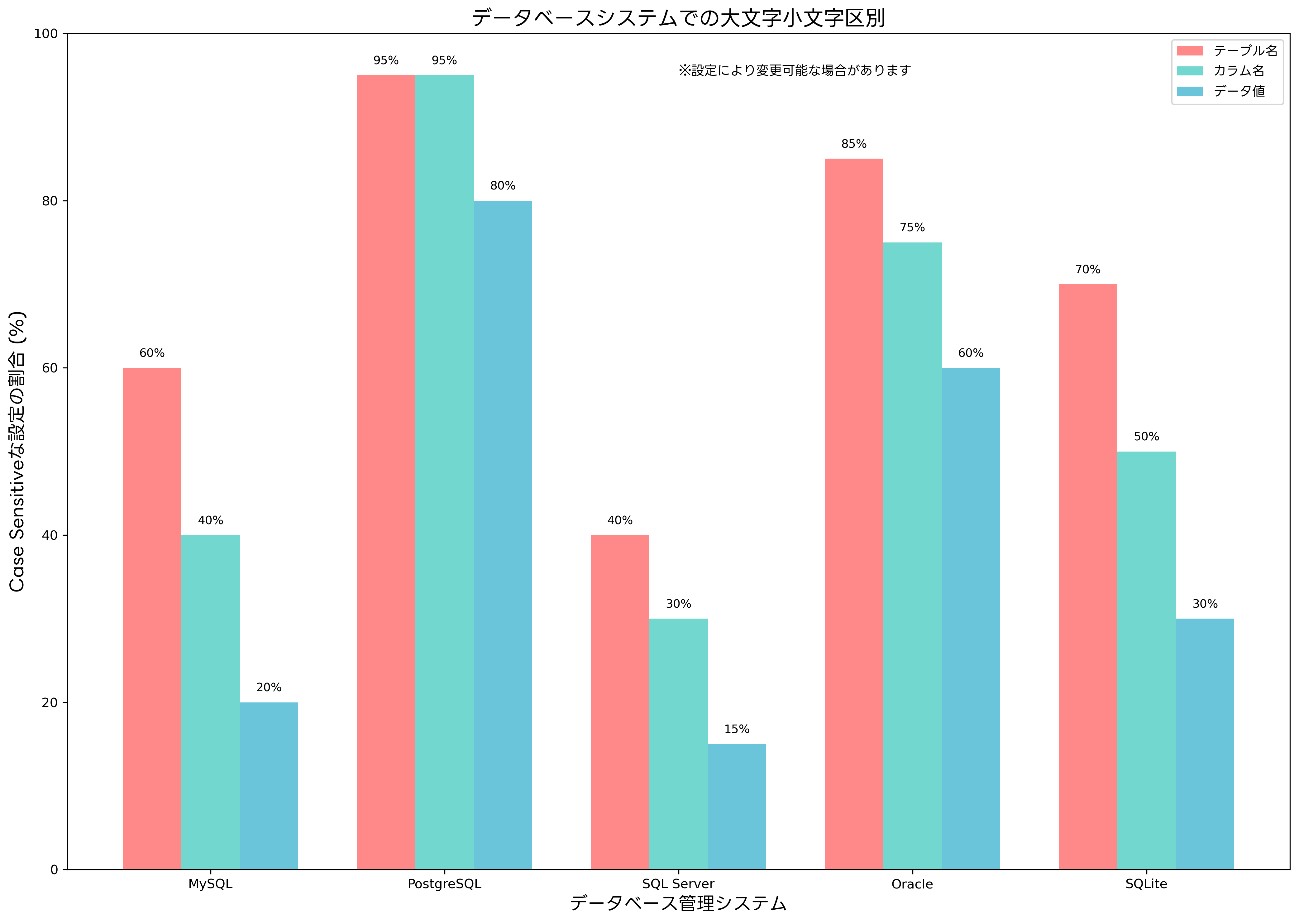
MySQLは、オペレーティングシステムの影響を強く受けます。Linuxでは大文字小文字を区別しますが、Windowsでは区別しません。これは、MySQLがファイルシステムを直接使用してテーブルを格納するためです。この動作の違いは、マルチプラットフォーム対応のアプリケーション開発において重要な考慮事項となります。MySQL実践運用ガイドでは、この問題への対処法が詳しく解説されています。
PostgreSQLは、より複雑な動作をします。引用符で囲まれていない識別子は、内部的に小文字に変換されて処理されます。例えば、「CREATE TABLE UserTable」と実行すると、実際には「usertable」という名前のテーブルが作成されます。一方、「CREATE TABLE “UserTable”」のように引用符で囲むと、大文字小文字がそのまま保持されます。この動作を正しく理解するためには、PostgreSQL徹底活用ガイドなどの専門書籍が役立ちます。
SQL Serverは、照合順序(Collation)の設定によって大文字小文字区別の動作が決まります。デフォルトの照合順序では大文字小文字を区別しませんが、「SQL_Latin1_General_CP1_CS_AS」のようなCase Sensitiveな照合順序を選択することで、区別するように設定できます。この柔軟性により、アプリケーションの要件に応じて適切な設定を選択できます。
Oracleデータベースは、デフォルトで大文字小文字を区別しません。ただし、引用符で囲まれた識別子は区別されます。また、データ値の比較においても、デフォルトでは大文字小文字を区別しませんが、BINARY演算子を使用することで厳密な比較を行うことができます。[Oracle Database管理者ガイド](https://www.amazon.co.jp/s?k=Oracle Database管理者ガイド&tag=amazon-product-items-22)では、これらの高度な機能の使用方法が詳しく説明されています。
NoSQLデータベースでも、大文字小文字区別は重要な考慮事項です。MongoDBはJavaScriptベースであるため、フィールド名は大文字小文字を区別します。また、クエリにおいても、デフォルトでは大文字小文字を区別しますが、正規表現オプションを使用することで区別しない検索も可能です。NoSQLデータベース設計ガイドでは、このような現代的なデータベースシステムでの実践的な設計手法が紹介されています。
セキュリティへの影響
大文字小文字区別は、情報セキュリティにおいて重要な影響を与えます。特に、認証、アクセス制御、攻撃の防御において、この概念の理解は不可欠です。
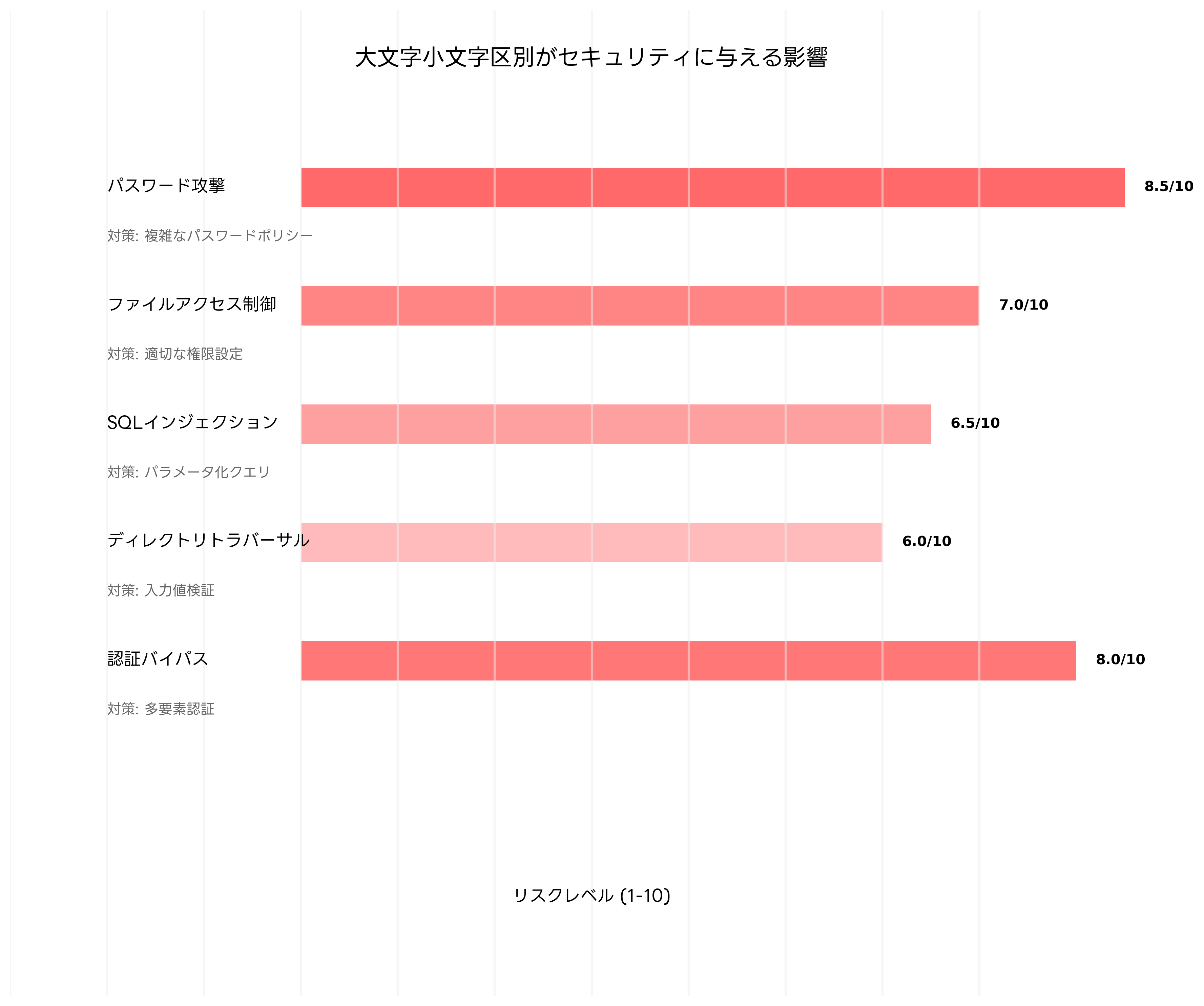
パスワード認証における大文字小文字区別は、セキュリティ強度に直接影響します。大文字小文字を区別するシステムでは、「Password」と「password」は異なるパスワードとして扱われます。これにより、攻撃者が総当たり攻撃(ブルートフォース攻撃)を行う際の組み合わせ数が大幅に増加し、セキュリティが向上します。26文字のアルファベットのみを使用する場合と、大文字小文字を区別して52文字を使用する場合では、可能な組み合わせ数に指数的な差が生じます。
情報セキュリティ実践ガイドでは、パスワードの複雑性を高めるための具体的な手法が紹介されており、大文字小文字の組み合わせの重要性が強調されています。また、パスワード管理ツールを使用することで、複雑なパスワードを安全に管理できます。
ファイルアクセス制御においても、大文字小文字区別は重要な役割を果たします。Unix系システムでは、「/etc/passwd」と「/etc/Passwd」は異なるファイルとして扱われるため、アクセス権限も個別に設定されます。攻撃者がファイル名の大文字小文字を変更することで、意図しないファイルにアクセスしようとする攻撃(パストラバーサル攻撃の一種)を防ぐためには、適切なアクセス制御の設定が必要です。
SQLインジェクション攻撃においても、大文字小文字区別が影響することがあります。データベースの設定によっては、攻撃者が大文字小文字を変更することで、WAF(Web Application Firewall)のフィルタリングを回避しようとする場合があります。例えば、「SELECT」が検出される場合に「select」や「SeLeCt」を使用する攻撃手法です。Webセキュリティ対策ガイドでは、このような攻撃への対策が詳しく説明されています。
認証バイパス攻撃では、大文字小文字区別の実装の不整合を狙った攻撃が行われることがあります。例えば、ユーザー名の検証とセッション管理で大文字小文字区別の扱いが異なる場合、攻撃者がこの差異を悪用してアクセス権限を不正に取得する可能性があります。このような脆弱性を防ぐためには、セキュアコーディングガイドラインに従った一貫した実装が重要です。
応用情報技術者試験での出題傾向
応用情報技術者試験において、大文字小文字区別に関する問題は、プログラミング、データベース、セキュリティの分野で出題されることが多くあります。特に、システム設計やマルチプラットフォーム対応に関する文脈で、この概念の理解が問われます。
午前問題では、プログラミング言語の特徴に関する問題で大文字小文字区別が取り上げられることがあります。例えば、「JavaScriptにおいて、変数名『userName』と『Username』は同じ変数を指すか」といった基本的な知識を問う問題や、「Unix系システムとWindows系システムでファイル名の扱いに違いがあるか」といった、オペレーティングシステムの特徴に関する問題が出題されます。
データベースに関する問題では、SQLの識別子の扱いや、異なるDBMS間での移植性に関連して大文字小文字区別が問われます。「MySQLとPostgreSQLでテーブル名の大文字小文字区別の動作に違いがあるか」といった実践的な知識が必要な問題も出題されます。応用情報技術者試験データベース対策では、このような実践的な問題への対策が詳しく解説されています。
午後問題では、より実践的な場面での大文字小文字区別の考慮が問われます。システム設計の問題において、クロスプラットフォーム対応やセキュリティ考慮事項として、大文字小文字区別の扱いを適切に設計できるかが評価されます。また、プログラミング問題では、大文字小文字を区別する処理と区別しない処理の実装方法が問われることもあります。
セキュリティ分野では、大文字小文字区別がセキュリティホールの原因となるケースや、適切な対策方法に関する問題が出題されます。情報セキュリティマネジメント試験対策でも、類似の問題が扱われており、併せて学習することで理解を深めることができます。
試験対策としては、応用情報技術者試験完全対策やプログラミング問題集を活用して、実践的な問題演習を積むことが重要です。
実装における注意点とベストプラクティス
実際のシステム開発において大文字小文字区別を適切に扱うためには、設計段階からの慎重な検討が必要です。特に、マルチプラットフォーム対応やマイグレーション、国際化対応において、この概念は重要な役割を果たします。
クロスプラットフォーム開発では、異なるオペレーティングシステム間でのファイルシステムの違いを考慮する必要があります。WindowsとLinuxの両方で動作するアプリケーションを開発する場合、ファイル名やパス名は常に一貫した命名規則を適用すべきです。一般的なベストプラクティスとして、すべて小文字を使用し、単語の区切りにはハイフンやアンダースコアを使用する方法があります。クロスプラットフォーム開発ガイドでは、このような実践的な設計手法が詳しく解説されています。
データベース設計では、将来の移行可能性を考慮して、可能な限り大文字小文字区別に依存しない設計を心がけるべきです。テーブル名やカラム名は一貫して小文字を使用し、複数の単語を組み合わせる場合はアンダースコアで区切るスネークケース(snake_case)を採用することが推奨されます。データベース設計パターンでは、このような移植性の高い設計手法が体系的に説明されています。
Webアプリケーション開発では、URLの設計において大文字小文字区別を考慮する必要があります。SEOの観点からも、URLは小文字で統一し、単語の区切りにはハイフンを使用することが推奨されています。また、Webサーバーの設定で適切なリダイレクトルールを設定し、大文字小文字の違いによる404エラーを防ぐことも重要です。SEO対策実践ガイドでは、URLの正規化に関する詳細な手法が紹介されています。
APIの設計においても、一貫した命名規則を適用することが重要です。RESTful APIでは、リソース名は小文字の複数形を使用し、単語の区切りにはハイフンを使用するのが一般的です。例:「/api/user-profiles」「/api/order-items」。API設計ベストプラクティスでは、このような標準的な設計パターンが詳しく解説されています。
国際化と大文字小文字区別
国際化(Internationalization, i18n)の文脈では、大文字小文字区別はより複雑な問題となります。言語によって大文字小文字の概念や変換ルールが大きく異なるためです。
英語以外の言語では、大文字小文字の変換が単純な対応関係にならない場合があります。例えば、ドイツ語の「ß」(エスツェット)は、大文字変換すると「SS」になります。また、トルコ語では、「i」の大文字は「İ」(点付きのI)であり、通常の「I」とは異なります。このような複雑性に対応するためには、Unicode正規化ガイドや多言語対応プログラミングなどの専門書籍を参考にする必要があります。
日本語の場合、ひらがなとカタカナの間には大文字小文字のような関係性がありますが、厳密には異なる文字体系です。全角文字と半角文字の問題も考慮する必要があります。例えば、「アイウエオ」(全角カタカナ)と「アイウエオ」(半角カタカナ)は、視覚的には似ていますが、コンピュータ上では全く異なる文字として扱われます。
中国語や韓国語でも、簡体字と繁体字の違い、あるいはハングルの合成文字の正規化など、大文字小文字区別に類似した複雑な問題があります。これらの言語を扱うシステムでは、適切な正規化処理とルール設定が不可欠です。東アジア言語処理技術では、このような専門的な技術が詳しく解説されています。
現代の開発フレームワークでの扱い
現代のWebフレームワークやアプリケーションフレームワークでは、大文字小文字区別に関する課題を解決するための機能が提供されています。これらの機能を適切に活用することで、より堅牢で保守性の高いシステムを構築できます。
React、Vue.js、Angularなどのフロントエンドフレームワークでは、コンポーネント名やプロパティ名の命名規則が重要です。これらのフレームワークはJavaScriptベースであるため、大文字小文字を区別しますが、HTMLの属性名は大文字小文字を区別しないという特殊な状況があります。モダンフロントエンド開発では、このような複雑な環境での適切な開発手法が説明されています。
Spring Boot、Django、Express.jsなどのバックエンドフレームワークでは、ルーティングやデータベースアクセスにおいて大文字小文字区別の設定を柔軟に制御できます。例えば、Spring Bootでは、データベースの物理命名戦略(PhysicalNamingStrategy)を設定することで、JavaのcamelCaseからデータベースのsnake_caseへの自動変換を行うことができます。
ORMフレームワーク(Hibernate、Django ORM、Sequelizeなど)では、オブジェクトのプロパティ名とデータベースのカラム名の間のマッピングを自動化する機能があります。これにより、プログラミング言語の命名規則とデータベースの命名規則の違いを透明に処理できます。ORM設計パターンでは、このような高度な機能の活用方法が詳しく解説されています。
将来の展望と新技術
人工知能と機械学習の分野では、大文字小文字区別に関する新しいアプローチが開発されています。自然言語処理において、文脈に応じて大文字小文字を適切に正規化する技術や、多言語対応の高度な正規化アルゴリズムが実用化されています。
クラウドネイティブなアプリケーション開発では、Kubernetes、Docker、マイクロサービスなどの技術において大文字小文字区別が重要な考慮事項となります。コンテナ名、サービス名、設定ファイルの命名など、様々な場面で一貫した命名規則を適用する必要があります。クラウドネイティブ開発ガイドでは、このような現代的な開発環境での実践的な手法が紹介されています。
GraphQLやgRPCなどの新しいAPI技術でも、大文字小文字区別は重要な設計要素です。これらの技術では、スキーマ定義において一貫した命名規則を適用することで、より保守性の高いAPIを構築できます。次世代API設計では、このような最新技術での設計手法が詳しく解説されています。
まとめ
大文字小文字区別(Case Sensitivity)は、現代の情報システム開発において基本的でありながら奥深い概念です。プログラミング言語、ファイルシステム、データベース、セキュリティ、国際化など、様々な分野で重要な役割を果たします。応用情報技術者試験においても、この概念の理解は必須の知識です。
システム設計者や開発者は、対象とする環境やプラットフォームの特性を正確に把握し、一貫した命名規則と適切な実装を行う必要があります。特に、マルチプラットフォーム対応やマイグレーション、国際化対応において、大文字小文字区別の適切な処理は、システムの信頼性と保守性を大きく左右します。
現代の開発フレームワークや新技術では、大文字小文字区別に関する課題を解決するための高度な機能が提供されています。これらの機能を適切に活用し、継続的に学習することで、より堅牢で効率的なシステムを構築することができます。技術の進歩とともに、この分野の知識も更新し続けることが、優れたシステム開発者になるための重要な要素です。