CPU(Central Processing Unit、中央処理装置)は、コンピュータシステムの中核を担う最も重要な部品です。「コンピュータの頭脳」とも呼ばれるCPUは、あらゆる演算処理や制御を担当し、現代のデジタル社会を支える根幹技術です。応用情報技術者試験においても頻出の重要トピックであり、コンピュータアーキテクチャの理解には欠かせない知識です。
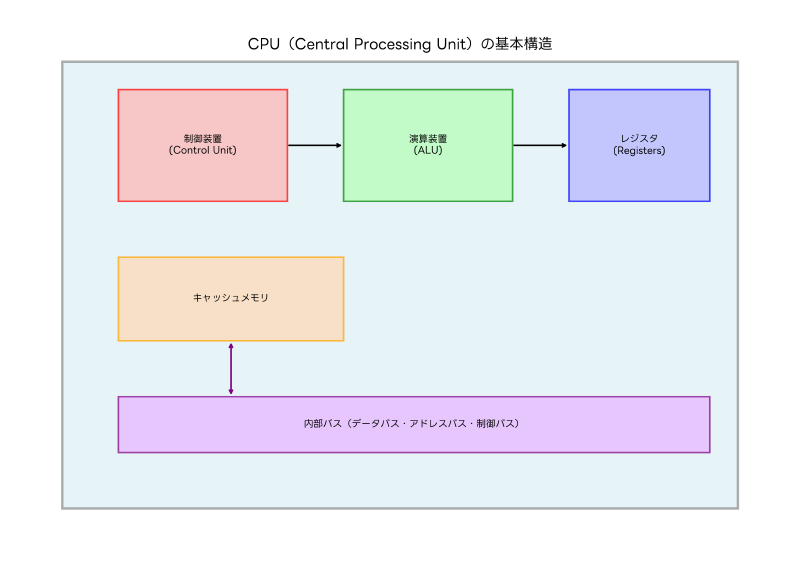
CPUは、制御装置、演算装置、レジスタ、キャッシュメモリなどの複数の要素から構成され、これらが協調して動作することで、プログラムの実行やデータの処理を実現しています。現代のCPUは、ナノメートル単位の微細な製造プロセスにより、数十億個のトランジスタを集積し、驚異的な処理能力を実現しています。
CPUの基本構造と動作原理
CPUの基本構造は、大きく制御装置(Control Unit)、演算装置(ALU:Arithmetic Logic Unit)、レジスタ(Registers)の三つの主要部分に分けられます。これらの構成要素が連携することで、プログラムの命令を解釈し、必要な演算を実行し、結果を適切な場所に格納する一連の処理が行われます。
制御装置は、CPUの司令塔として機能し、メモリから命令を読み込み、その命令を解析して他の部分に適切な制御信号を送る役割を担います。制御装置により、命令の実行順序が管理され、プログラムが正しく動作するための基盤が提供されます。現代の高性能CPU搭載パソコンでは、この制御装置が非常に高度に最適化されており、複雑な処理を効率的に実行できます。
演算装置(ALU)は、実際の数値計算や論理演算を実行する部分です。加算、減算、乗算、除算などの算術演算から、AND、OR、NOTなどの論理演算、さらにはシフト演算やビット操作まで、多様な演算機能を提供します。現代のCPUでは、複数のALUを並列配置することで、同時に複数の演算を実行できる設計が採用されています。
レジスタは、CPU内部にある高速なデータ記憶領域で、演算に使用するデータや演算結果を一時的に保存します。レジスタのアクセス速度は極めて高速で、通常1クロックサイクルでデータの読み書きが可能です。汎用レジスタ、アドレスレジスタ、インデックスレジスタ、ステータスレジスタなど、用途に応じて様々な種類のレジスタが存在します。
キャッシュメモリは、CPUとメインメモリの間に配置される高速メモリで、頻繁にアクセスされるデータや命令を一時的に保存することで、メモリアクセス時間の短縮を図ります。L1、L2、L3といった階層構造を持ち、CPUに近いほど高速でアクセスできます。現代のワークステーションでは、大容量のキャッシュメモリにより、データ集約的な処理でも高い性能を発揮できます。
命令実行サイクルとパイプライン処理
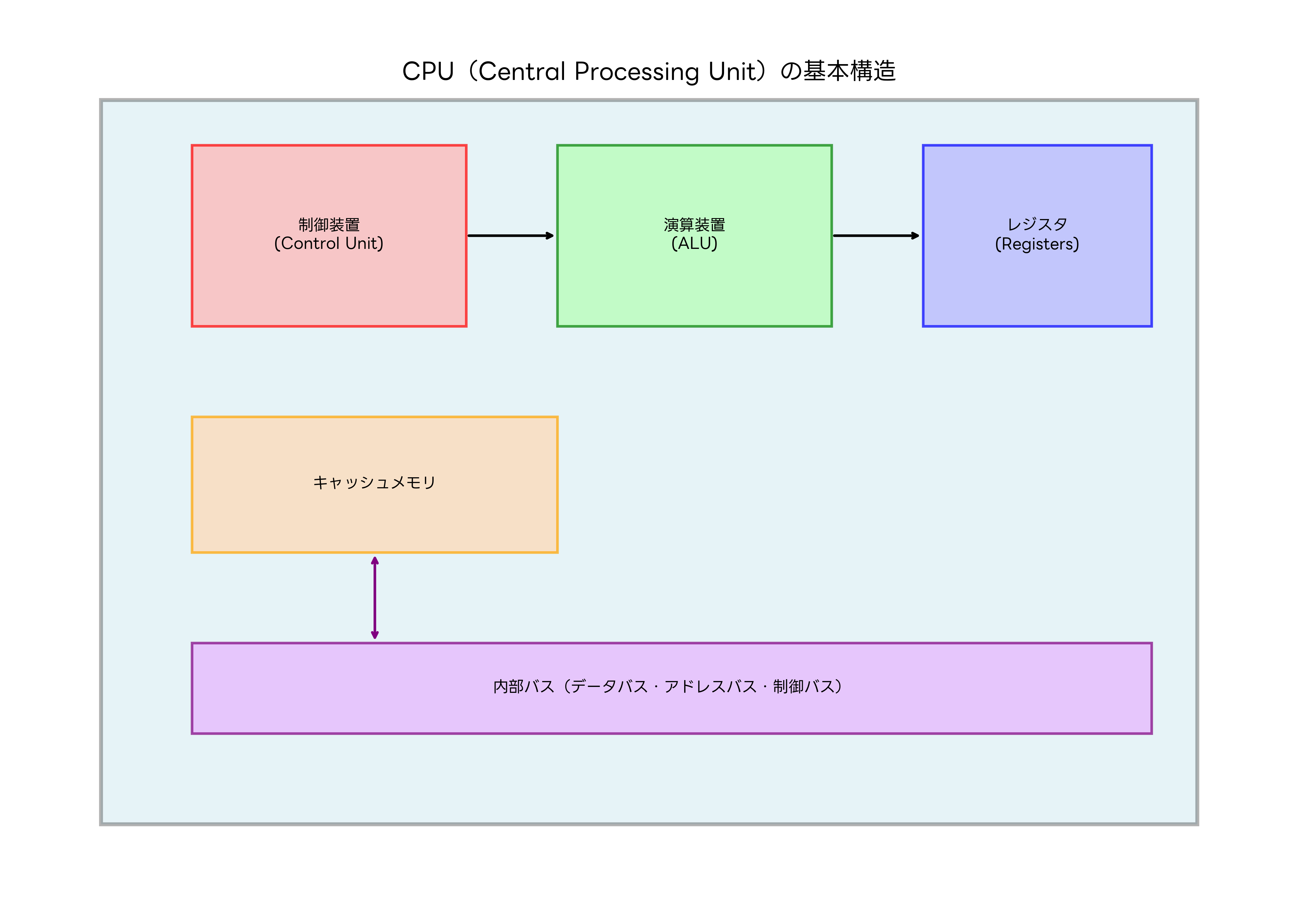
CPUが命令を実行する際の基本的な流れは、フェッチ(Fetch)、デコード(Decode)、実行(Execute)、ライトバック(Write Back)の4段階から構成される命令実行サイクルに従います。この一連の処理により、プログラムの各命令が順次実行され、所期の結果が得られます。
フェッチ段階では、プログラムカウンタが示すメモリアドレスから次に実行すべき命令を読み込みます。この際、命令キャッシュから高速に命令を取得することで、メモリアクセスの遅延を最小限に抑えます。現代の高性能プロセッサでは、分岐予測機能により、条件分岐命令の結果を予測して事前に適切な命令をフェッチすることで、処理効率を向上させています。
デコード段階では、取得した命令を解析し、どのような操作を実行すべきかを判断します。命令の種類、演算対象のレジスタやメモリアドレス、演算の種類などを特定し、実行段階で必要な制御信号を準備します。複雑命令セットコンピュータ(CISC)では、一つの命令が複数のマイクロオペレーションに分解される場合があります。
実行段階では、デコードされた命令に基づいて実際の演算処理が行われます。ALUによる算術・論理演算、メモリアクセス、レジスタ間のデータ転送などが実行されます。浮動小数点演算や複雑な演算については、専用の演算ユニットが使用され、高精度で高速な計算が実現されます。
ライトバック段階では、実行結果をレジスタやメモリに書き戻します。この際、データの整合性を保つため、適切な同期制御が行われます。また、実行結果に基づいてプログラムカウンタが更新され、次に実行すべき命令のアドレスが決定されます。
パイプライン処理は、これら4段階の処理を並列実行することで、CPUの処理能力を向上させる技術です。一つの命令が実行段階にある間に、次の命令をデコード段階で処理し、さらに次の命令をフェッチ段階で読み込むことで、理論上は毎クロックサイクルで一つの命令を完了できます。現代のCPUでは、10段階以上の深いパイプラインを採用し、さらなる高速化を実現しています。
CPU性能の指標と進化
CPU性能を評価する指標には、クロック周波数、コア数、IPC(Instruction Per Clock)、キャッシュ容量、アーキテクチャ効率などがあります。これらの指標は相互に関連し合い、総合的な処理能力を決定します。
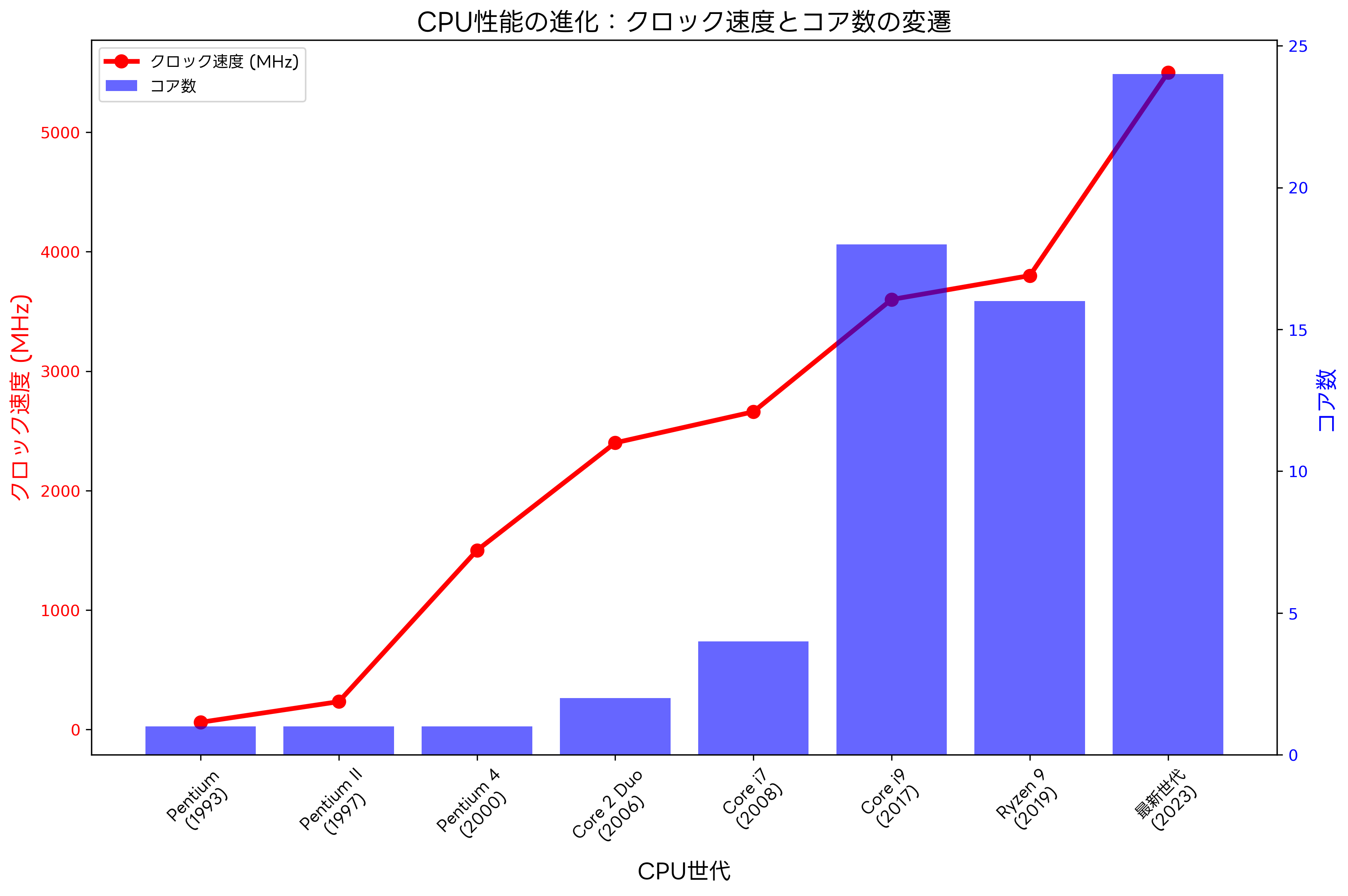
クロック周波数は、CPUが1秒間に実行できるクロックサイクル数を示し、ヘルツ(Hz)で表されます。より高いクロック周波数は、より多くの命令を短時間で実行できることを意味します。しかし、物理的な制約により、単純にクロック周波数を向上させることには限界があり、現代のCPU設計では他の手法との組み合わせによる性能向上が重視されています。
マルチコア設計は、一つのCPUチップ内に複数の処理コアを搭載することで、並列処理能力を向上させる技術です。デュアルコア、クアッドコア、8コア、16コアなど、用途に応じて様々なコア数のCPUが開発されています。マルチコアプロセッサ搭載PCでは、マルチタスク処理や並列計算において顕著な性能向上が期待できます。
IPCは、1クロックサイクルあたりに実行できる命令数を示す指標で、CPUのアーキテクチャ効率を表します。スーパースカラー設計により、複数の実行ユニットを並列動作させることで、IPCの向上が図られています。また、アウトオブオーダー実行により、命令間の依存関係を解析して実行順序を最適化することで、さらなる効率向上が実現されています。
キャッシュメモリの容量と階層構造も重要な性能要因です。L1キャッシュは最も高速でCPUに近く、通常32KB~64KB程度の容量を持ちます。L2キャッシュは256KB~1MB程度、L3キャッシュは8MB~32MB程度の容量を持ち、より大きなデータセットに対応します。ゲーミングPCでは、大容量キャッシュにより、ゲームデータの高速アクセスが可能になり、滑らかなゲーム体験が実現されます。
メモリ階層とCPUの関係
CPUとメモリシステムの関係は、コンピュータ全体の性能に大きな影響を与える重要な要素です。メモリ階層は、速度、容量、コストのトレードオフを考慮して設計され、効率的なデータアクセスを実現しています。
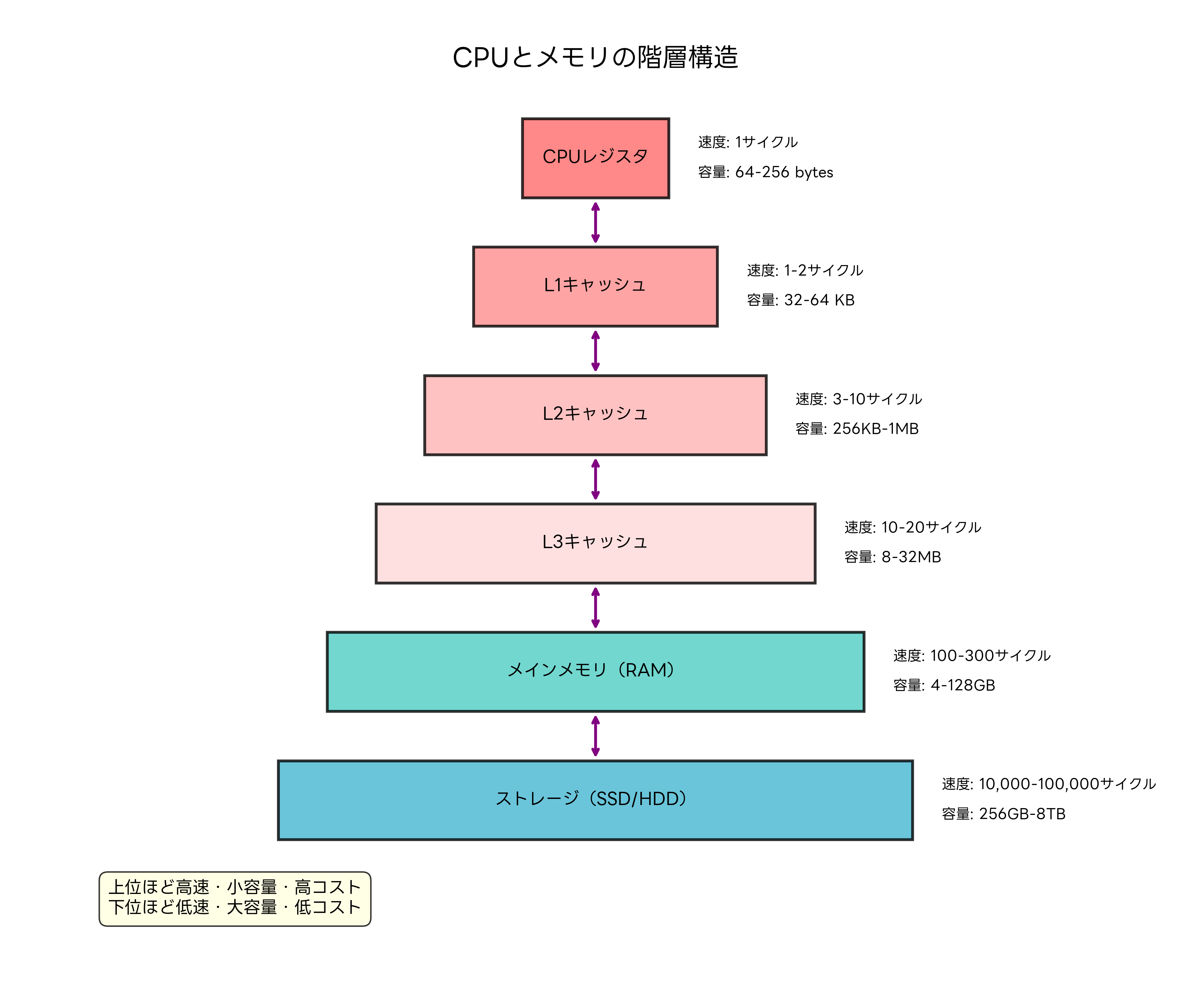
最上位層のCPUレジスタは、最も高速なアクセスが可能で、通常1クロックサイクルでデータの読み書きができます。容量は64~256バイト程度と小さいですが、演算に直接使用されるデータの一時保存に使用されます。レジスタの効率的な利用は、コンパイラの最適化技術により実現され、プログラムの実行速度に直接影響します。
L1キャッシュは、CPUコアに最も近い位置にあるキャッシュメモリで、データキャッシュと命令キャッシュに分離されている場合が多いです。アクセス時間は1~2クロックサイクルと高速で、頻繁にアクセスされるデータや命令を保存します。L1キャッシュのヒット率向上は、CPU性能に直接的な影響を与えるため、キャッシュ設計の最適化が重要です。
L2キャッシュは、L1キャッシュよりも大容量で、アクセス時間は3~10クロックサイクル程度です。L1キャッシュでミスしたデータアクセスをカバーし、メインメモリへのアクセス回数を削減します。現代のマルチコアプロセッサでは、各コア専用のL2キャッシュと、全コアで共有するL3キャッシュの組み合わせが一般的です。
L3キャッシュは、最も大容量のキャッシュメモリで、通常8MB~32MBの容量を持ちます。アクセス時間は10~20クロックサイクル程度で、コア間でのデータ共有や、メインメモリアクセスの削減に重要な役割を果たします。ワークステーション用CPUでは、大容量L3キャッシュにより、大規模なデータセットを扱う科学計算や画像処理で高い性能を発揮できます。
メインメモリ(RAM)は、現在実行中のプログラムやデータを格納する主記憶装置です。アクセス時間は100~300クロックサイクルと、キャッシュメモリと比べて大幅に遅いですが、4GB~128GBという大容量を提供します。高速メモリの採用により、メモリボトルネックの軽減が可能です。
ストレージデバイス(SSDやHDD)は、永続的なデータ保存を担当し、容量は256GB~8TB以上と非常に大きいですが、アクセス時間は10,000~100,000クロックサイクルと極めて遅いです。高速SSDの使用により、OS起動時間やアプリケーション読み込み時間の大幅な短縮が可能です。
CPUの使用率管理と最適化
CPU使用率の監視と管理は、システムパフォーマンスの最適化において重要な要素です。適切なCPU使用率の維持により、応答性の確保と電力効率の向上を両立できます。
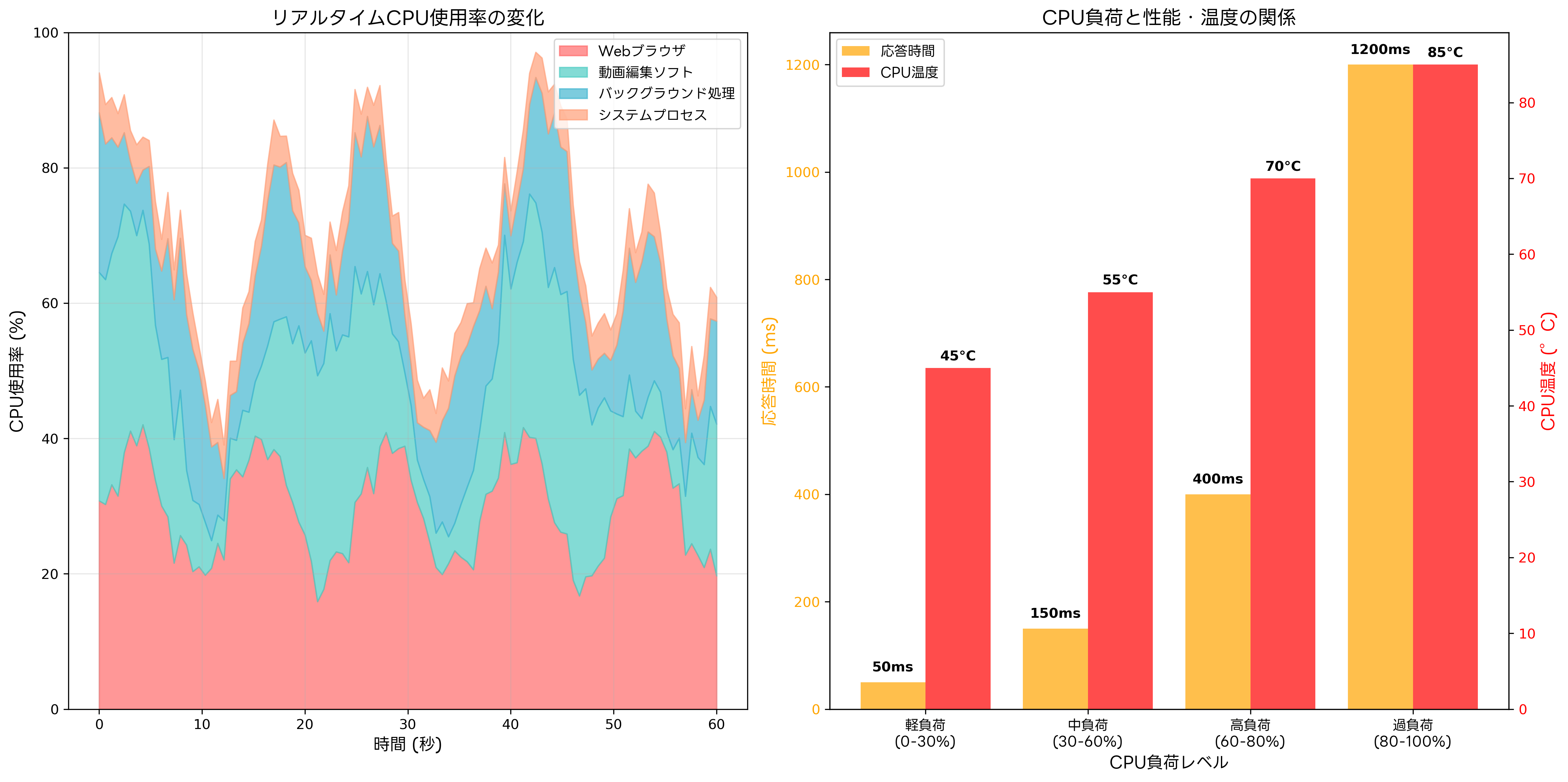
CPU使用率が30%以下の軽負荷状態では、システムは十分な余裕を持って動作し、新しいタスクの開始や優先度の高い処理に迅速に対応できます。この状態では、CPUの動的電圧制御や省電力機能が活用され、消費電力の削減が可能です。省電力設計のPCでは、軽負荷時の効率的な電力管理により、長時間の連続使用が可能になります。
30%~60%の中負荷状態では、複数のアプリケーションが同時に動作し、マルチタスク処理が活発に行われます。この範囲では、CPU性能と消費電力のバランスが最適化され、効率的な処理が実現されます。オペレーティングシステムのスケジューラが重要な役割を果たし、各プロセスに適切なCPU時間を割り当てます。
60%~80%の高負荷状態では、CPUが集約的な処理を実行しており、応答時間の増加や温度上昇が発生する可能性があります。この状態では、CPUクーリングシステムの効果的な動作が重要になり、高性能CPUクーラーの使用により、安定した動作を維持できます。
80%を超える過負荷状態では、システムの応答性が大幅に低下し、タスクの完了時間が延長されます。この状態が継続すると、CPUの熱制御機能により、クロック周波数の自動削減(サーマルスロットリング)が発生し、性能が制限される可能性があります。適切な負荷分散や、マルチコアプロセッサの活用により、過負荷状態の回避が可能です。
プロセスの優先度管理も重要な最適化手法です。リアルタイム処理、対話的処理、バックグラウンド処理など、アプリケーションの特性に応じて適切な優先度を設定することで、ユーザー体験の向上が図れます。プロフェッショナル向けワークステーションでは、高度な優先度制御により、重要な処理の優先実行が保証されます。
省電力技術とエネルギー効率
現代のCPU設計において、省電力技術とエネルギー効率の向上は重要な技術課題です。モバイルデバイスからデータセンターまで、あらゆる用途でエネルギー効率の改善が求められています。
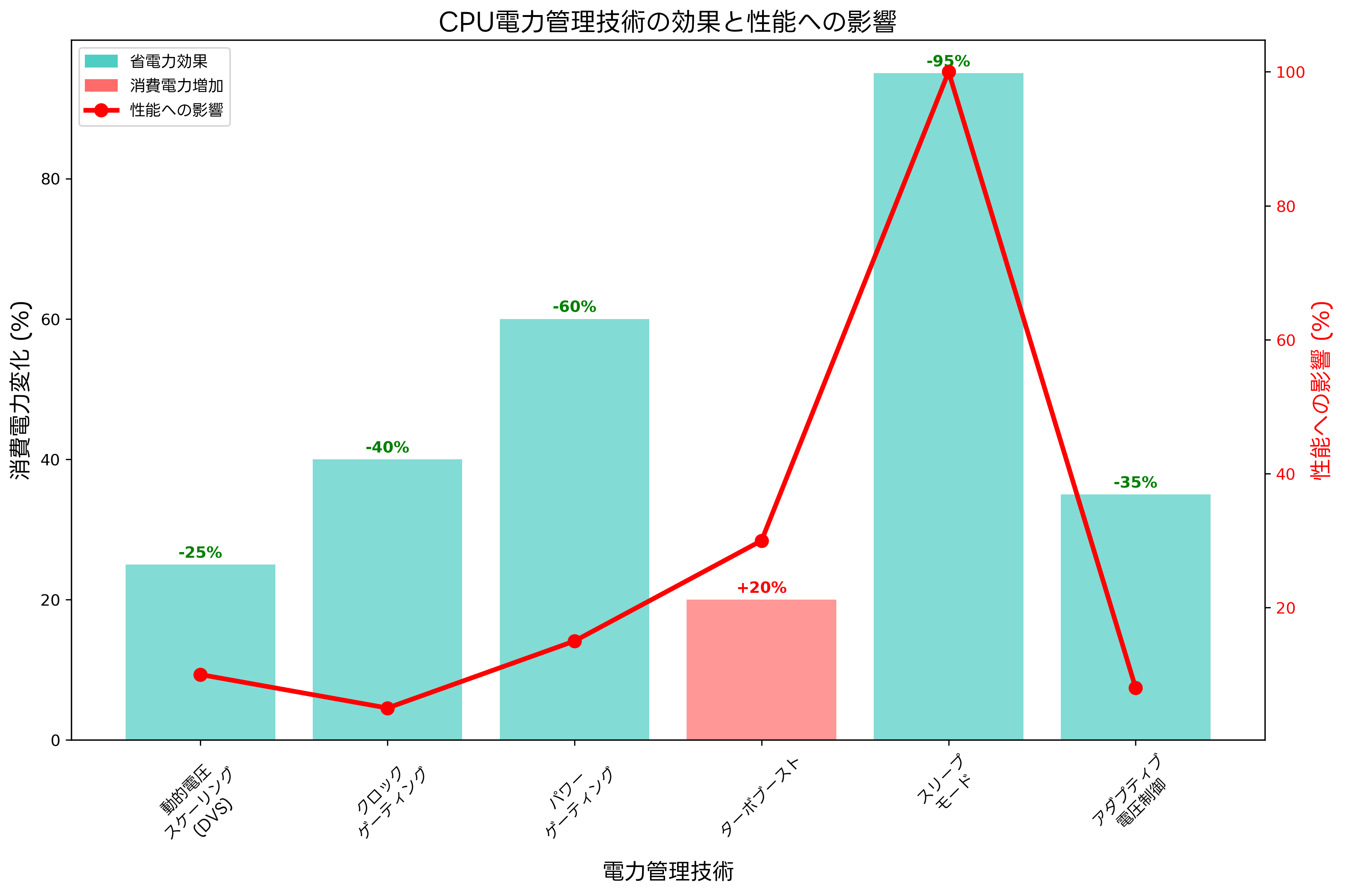
動的電圧・周波数制御(DVFS:Dynamic Voltage and Frequency Scaling)は、処理負荷に応じてCPUの動作電圧とクロック周波数を動的に調整する技術です。軽負荷時には低電圧・低周波数で動作し、高負荷時には高電圧・高周波数で動作することで、必要十分な性能を提供しながら消費電力を最小化します。
クロックゲーティングは、使用されていない回路ブロックへのクロック供給を停止することで、動的電力消費を削減する技術です。実行ユニット、キャッシュ、レジスタファイルなど、細かい単位でクロック制御を行うことで、効果的な省電力が実現されます。モバイルワークステーションでは、クロックゲーティング技術により、バッテリー駆動時間の延長が可能です。
パワーゲーティングは、使用されていない回路ブロックへの電源供給を完全に遮断する技術で、リーク電流による静的電力消費を大幅に削減できます。ただし、電源の再投入には時間がかかるため、適切なタイミングでの制御が重要です。
ターボブースト技術は、一部のCPUコアの負荷が軽い場合に、他のコアのクロック周波数を一時的に定格以上に向上させる技術です。全体の消費電力と温度の制約内で、単一スレッド性能の向上を図ります。ゲーミングノートPCでは、ターボブースト機能により、ゲーム実行時の高い性能を実現できます。
スリープモードやアイドル状態の最適化により、使用されていない期間の消費電力を最小限に抑えます。浅いスリープから深いスリープまで、複数の省電力状態を階層的に管理し、復帰時間と省電力効果のバランスを最適化します。
アダプティブ電圧制御は、製造プロセスのばらつきや動作条件の変化に応じて、各CPUチップの最適動作電圧を個別に調整する技術です。過剰な電圧マージンを削減することで、エネルギー効率の向上が可能です。
応用情報技術者試験での出題傾向
応用情報技術者試験におけるCPU関連の出題は、基本的なアーキテクチャの理解から高度な最適化技術まで幅広い分野にわたります。特に、コンピュータシステムの分野では、CPUの動作原理や性能評価に関する問題が頻出しています。
午前問題では、CPUの基本構造、命令実行サイクル、パイプライン処理、キャッシュメモリの動作原理、性能計算などが主要な出題範囲です。例えば、「4段パイプラインで10個の命令を実行する場合の所要サイクル数を求める」といった計算問題や、「キャッシュヒット率が性能に与える影響を評価する」といった応用問題が出題されます。
午後問題では、より実践的な場面でのCPU性能分析や最適化戦略の立案が問われます。システム設計において、CPU性能要件の分析、ボトルネック特定、最適化手法の選択などの能力が評価されます。また、省電力設計やリアルタイムシステムでのCPU利用などの応用分野も出題対象です。
試験対策としては、応用情報技術者試験対策書を活用して、理論的な知識を体系的に学習することが重要です。また、コンピュータアーキテクチャの専門書により、最新の技術動向や設計手法を理解することで、より深い知識を身につけられます。
実践的な学習として、システム監視ツールを使用して、実際のCPU使用率やパフォーマンスメトリクスを観察し、理論と実際の動作を関連付けることが効果的です。また、ベンチマークソフトウェアを使用して、異なるCPU構成での性能比較を行うことで、実践的な分析能力を養うことができます。
最新技術動向と将来展望
CPU技術の進歩は目覚ましく、人工知能、量子コンピューティング、エッジコンピューティングなどの新しい分野での需要に対応した革新的な設計が継続的に開発されています。
プロセッサの微細化は、ムーアの法則に従って進歩してきましたが、物理的な限界に近づいているため、新しいアプローチが模索されています。3次元積層技術、新材料の活用、量子効果の利用などにより、さらなる性能向上と小型化が期待されています。
ヘテロジニアスコンピューティングは、異なる特性を持つ複数の処理ユニットを組み合わせることで、アプリケーションの特性に最適化された処理を実現する技術です。CPUコア、GPUコア、AI専用コア、DSPなどを統合したSoC(System on Chip)設計により、総合的な性能向上と省電力化が図られています。
エッジAIの普及により、低消費電力でリアルタイム推論が可能なAI専用チップの需要が高まっています。AI対応エッジデバイスでは、従来のCPUアーキテクチャを拡張したニューラルプロセッシングユニット(NPU)が搭載され、効率的なAI処理が実現されています。
量子コンピューティング技術の発展により、特定の計算問題において指数関数的な性能向上が期待されています。量子ビット(qubit)を利用した計算原理は従来のCPUとは根本的に異なりますが、従来型コンピュータとの協調動作により、新しい計算パラダイムが確立されつつあります。
サーバーレスコンピューティングやコンテナ技術の普及により、CPU資源の動的割り当てと効率的利用が重要になっています。クラウドインフラ対応ハードウェアでは、仮想化技術の最適化と、マルチテナント環境での性能隔離が重要な設計要素となっています。
セキュリティ機能の強化
現代のCPUには、ハードウェアレベルでのセキュリティ機能が組み込まれており、システム全体の安全性向上に重要な役割を果たしています。これらの機能は、ソフトウェアだけでは実現困難な高度なセキュリティ対策を提供します。
ハードウェア仮想化支援機能は、仮想マシンの実行を効率化し、ホストOSとゲストOSの完全な分離を実現します。Intel VT-xやAMD-Vなどの技術により、仮想環境でのセキュリティ境界の強化が可能です。仮想化対応サーバーでは、これらの機能により、安全で効率的な仮想環境の構築が可能です。
メモリ保護機能は、プロセス間のメモリ領域を厳密に分離し、不正なメモリアクセスを防止します。NX(No eXecute)ビット、SMEP(Supervisor Mode Execution Prevention)、SMAP(Supervisor Mode Access Prevention)などの機能により、バッファオーバーフローやコード注入攻撃に対する防御が強化されています。
暗号化処理の高速化も重要なセキュリティ機能です。AES-NI、SHA-NI、AVX512などの専用命令セットにより、暗号化・復号化処理や暗号学的ハッシュ計算を高速化し、セキュリティ機能の性能オーバーヘッドを最小化できます。セキュリティ特化サーバーでは、これらの機能により、高速で安全な暗号化処理が実現されています。
まとめ
CPU(Central Processing Unit)は、現代コンピュータシステムの中核を担う極めて重要な部品です。制御装置、演算装置、レジスタ、キャッシュメモリなどの基本構成要素から、パイプライン処理、マルチコア設計、省電力技術まで、多岐にわたる技術が集約されています。
応用情報技術者試験においては、CPUアーキテクチャの理解が必須であり、基本的な動作原理から最新の最適化技術まで幅広い知識が求められます。理論的な学習と実践的な経験を組み合わせることで、深い理解を獲得できます。
技術の進歩とともに、CPU設計はより複雑で高度になっていますが、基本的な原理と概念は変わりません。AI、IoT、量子コンピューティングなどの新しい技術分野でも、CPUの基礎知識は重要な基盤となります。継続的な学習により、変化する技術環境に対応できる能力を身につけることが重要です。
現代社会のデジタル化の進展とともに、CPUの重要性はますます高まっています。効率的で安全なコンピューティング環境の実現には、CPUの深い理解と適切な活用が不可欠です。今後も技術革新が続く分野として、常に最新の動向を把握し、実践的な知識を蓄積していくことが求められます。