データモデリングは、現実世界の業務やデータを情報システムで扱える形に抽象化・構造化する重要な技術です。応用情報技術者試験において頻出の分野であり、システム開発の上流工程で欠かせない知識として位置づけられています。適切なデータモデリングを行うことで、保守性が高く拡張可能なシステムを構築できるため、システム設計者やデータベース管理者にとって必須のスキルとなっています。
データモデリングは単なる技術的な作業ではなく、業務要件を深く理解し、将来的な変更にも対応できる柔軟な設計を行う創造的なプロセスです。このプロセスを通じて、データの整合性、効率性、再利用性を確保し、組織全体の情報資産を価値あるものに変換していきます。
データモデリングの基本概念と目的
データモデリングの主な目的は、複雑な現実世界のデータ構造を、コンピューターで処理可能な論理的で一貫性のある形式に変換することです。このプロセスでは、データ間の関係性を明確にし、データの重複を排除し、整合性を保つための制約を定義します。
効果的なデータモデリングを実践するためには、データモデリングツールの活用が重要です。これらのツールは、複雑なデータ構造を視覚的に表現し、設計の妥当性を検証する機能を提供します。特に大規模なシステム設計では、エンタープライズ向けデータモデリングソフトウェアを使用することで、チーム間での情報共有と設計品質の向上を実現できます。
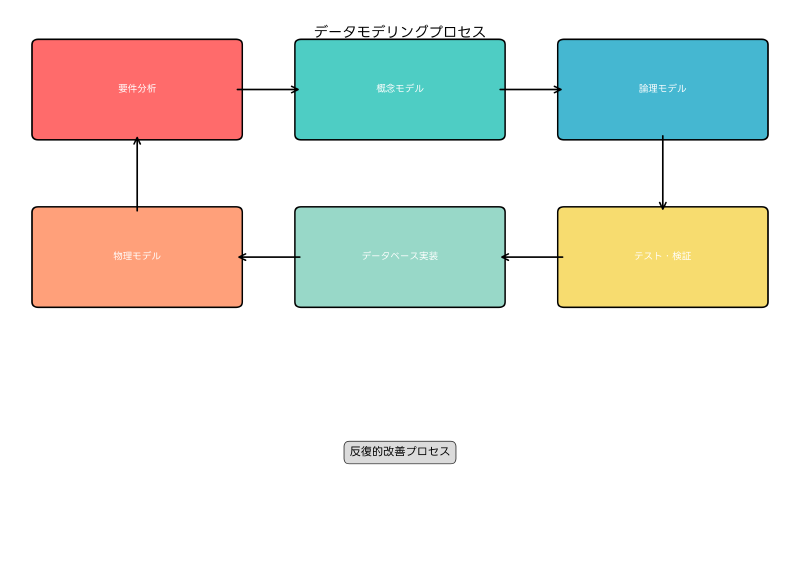
データモデリングには、概念モデル、論理モデル、物理モデルという3つの段階があります。概念モデルでは業務要件を高レベルで表現し、論理モデルでは具体的なデータ構造を定義し、物理モデルでは特定のデータベース管理システムに最適化された構造を設計します。各段階で適切なデータベース設計参考書を活用することで、理論と実践の両面から理解を深めることができます。
現代の企業では、従来の構造化データに加えて、半構造化データや非構造化データも含めた包括的なデータモデリングが求められています。このような多様なデータ形式に対応するため、NoSQLデータベース設計書やビッグデータ処理技術書による学習も重要になっています。
ERモデル(Entity-Relationship Model)の理解と実践
ERモデルは、データモデリングにおいて最も広く使用される手法の一つです。エンティティ(実体)、リレーションシップ(関係)、アトリビュート(属性)という3つの基本要素を使用して、現実世界のデータ構造を表現します。
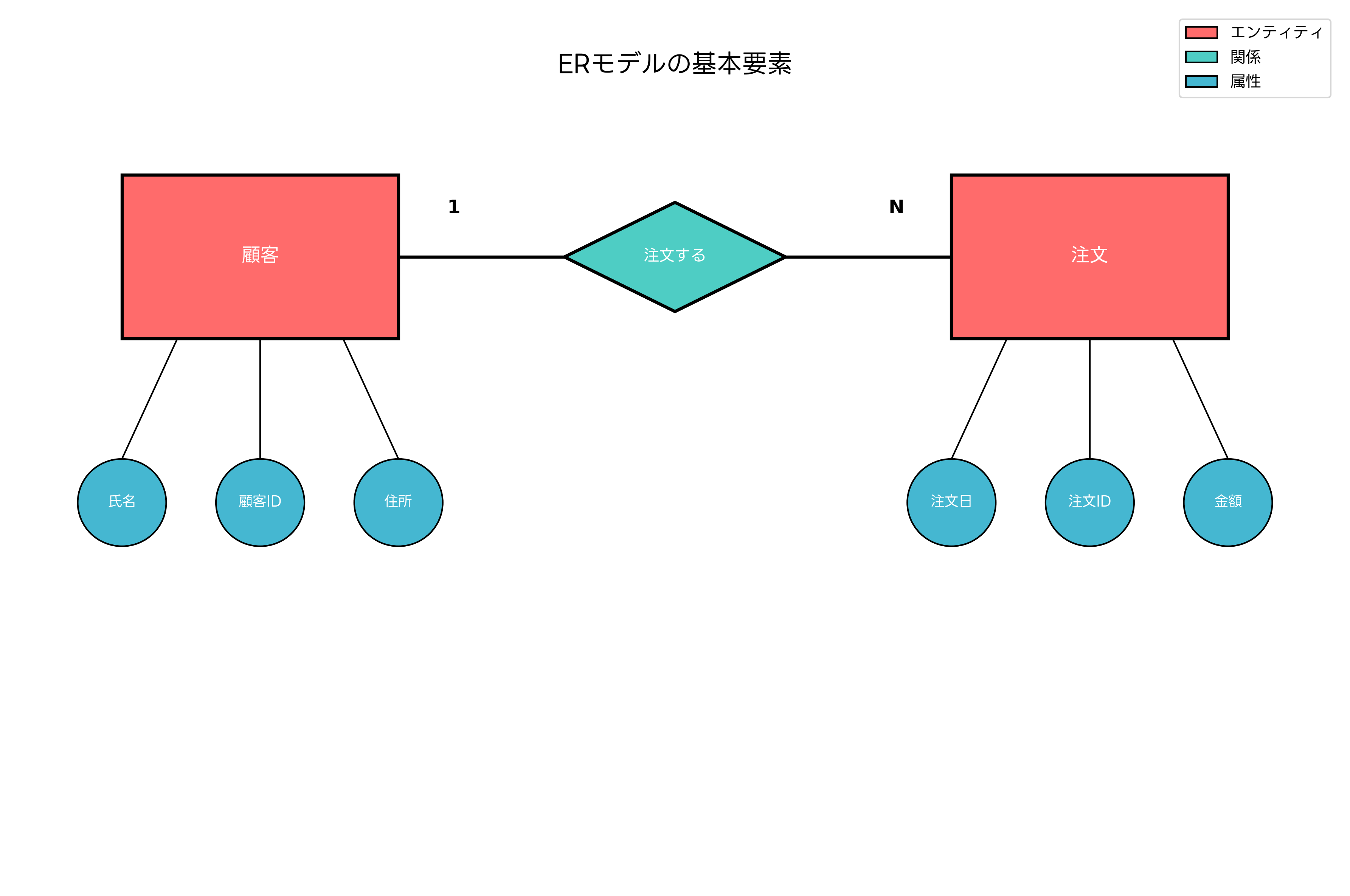
エンティティは、システムで管理すべき具体的な対象物や概念を表します。例えば、販売管理システムでは「顧客」「商品」「注文」などがエンティティになります。リレーションシップは、エンティティ間の関係を表し、一対一、一対多、多対多といった多重度を持ちます。アトリビュートは、エンティティが持つ特性や属性を表し、主キー、外部キー、通常属性に分類されます。
ERモデルの設計には、適切な表記法の理解が不可欠です。一般的にはChen記法やIE記法(Information Engineering記法)が使用され、それぞれに特徴があります。実際の設計作業では、ER図作成ソフトウェアを使用することで、効率的に図表を作成し、チーム内での共有を円滑に行うことができます。
複雑なビジネス要件を扱う場合、拡張ERモデル(EER:Extended Entity-Relationship Model)の概念も重要になります。継承、集約、特化・汎化といった概念を使用することで、より現実に即したモデリングが可能になります。これらの高度な概念については、データベース理論書で詳しく学習することをお勧めします。
実際のシステム開発では、ERモデルから論理設計、物理設計へと段階的に詳細化していきます。このプロセスでは、データベース設計パターン集を参考にすることで、よくある設計課題に対する効果的な解決策を学ぶことができます。
正規化理論:データの整合性と効率性の追求
正規化は、データベース設計における最も重要な概念の一つであり、データの冗長性を排除し、更新時の異常を防ぐための体系的な手法です。第1正規形から第5正規形まで定義されていますが、実際の設計では第3正規形までを適用することが一般的です。
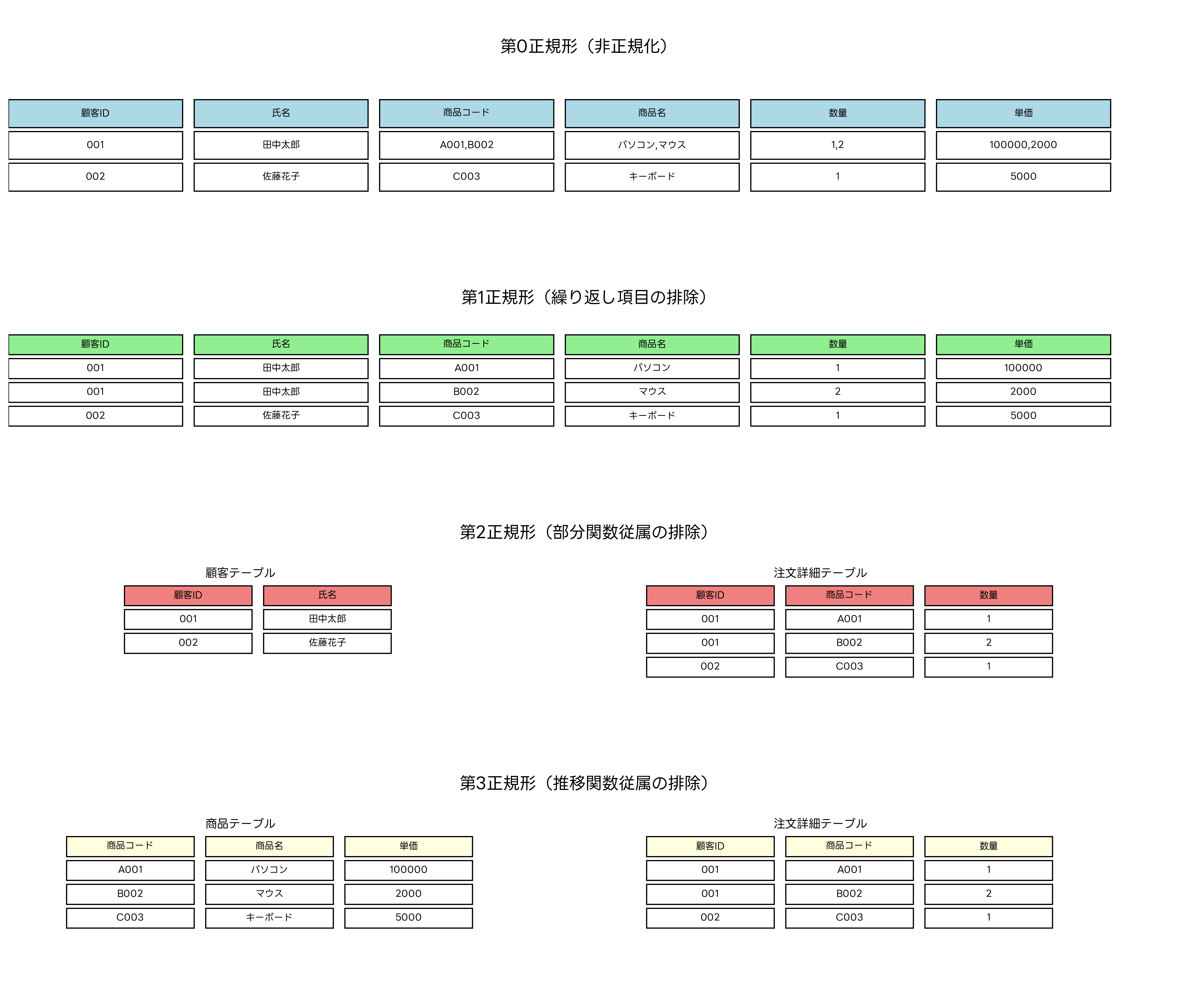
第1正規形では、繰り返し項目を排除し、各属性が原子値(分割不可能な値)を持つようにします。第2正規形では、部分関数従属を排除し、主キーの一部の属性に従属する非キー属性を別テーブルに分離します。第3正規形では、推移関数従属を排除し、非キー属性間の従属関係を解消します。
正規化の実践では、理論的な理解に加えて、実際のビジネス要件との兼ね合いを考慮することが重要です。過度な正規化は、クエリの複雑化やパフォーマンスの低下を招く場合があります。そのため、データベースパフォーマンスチューニング書を参考にして、正規化と非正規化のバランスを適切に判断する必要があります。
現代のシステム設計では、OLTP(Online Transaction Processing)とOLAP(Online Analytical Processing)の要件の違いを理解することが重要です。OLTPシステムでは高度な正規化が適しており、OLAPシステムでは意図的な非正規化(次元モデリング)が効果的です。このような使い分けについては、データウェアハウス設計書で詳しく学習できます。
正規化の過程で発生する設計上の判断を文書化し、将来のメンテナンスに備えることも重要です。データベース設計ドキュメント作成ツールを活用することで、設計の根拠と変更履歴を適切に管理できます。
データ統合とマスターデータ管理
現代の企業では、複数のシステムから生成される多様なデータを統合し、一元的に管理する必要があります。データ統合は、異なるデータソースからの情報を組み合わせて、統一された視点でのデータ活用を可能にする重要なプロセスです。
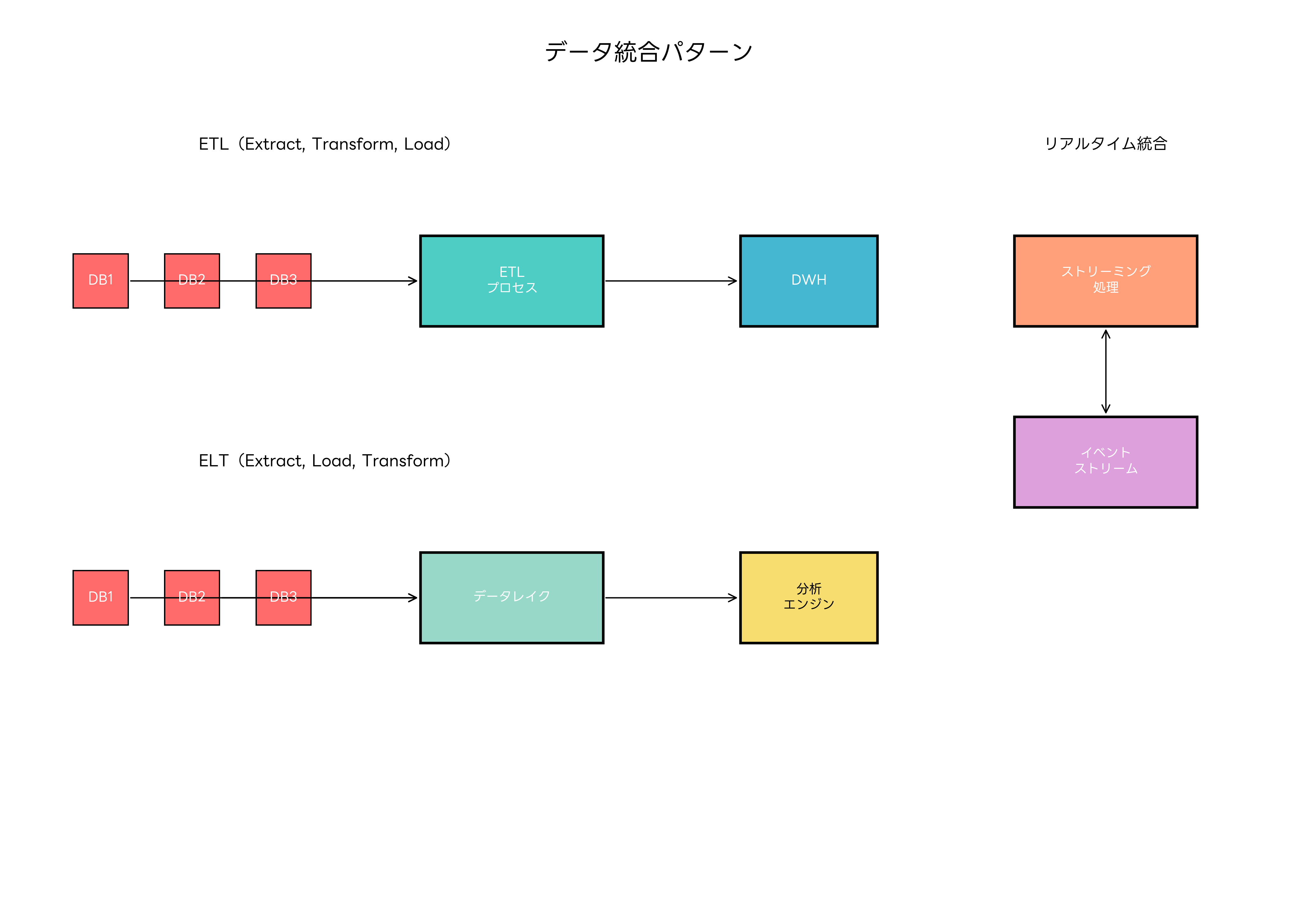
データ統合のアプローチには、ETL(Extract, Transform, Load)とELT(Extract, Load, Transform)の2つの主要なパターンがあります。ETLは従来型のデータウェアハウス構築で使用され、データの抽出、変換、格納を順次実行します。ELTは、ビッグデータ時代に適したアプローチで、まずデータを格納してから必要に応じて変換を行います。
実際のデータ統合プロジェクトでは、ETLツールやデータ統合プラットフォームの選択が重要になります。これらのツールは、複雑な変換ロジックを視覚的に設計し、大量データの処理を効率的に実行する機能を提供します。
マスターデータ管理(MDM:Master Data Management)は、組織内の重要な基準データを一元管理し、データの整合性と品質を確保するための仕組みです。顧客マスター、商品マスター、組織マスターなどの基幹データを統一的に管理することで、システム間でのデータの不整合を防ぎます。
MDMの実装では、データガバナンスの確立が不可欠です。データの所有者、品質責任者、利用者の役割を明確にし、データライフサイクル全体を通じた管理プロセスを定義します。この分野では、マスターデータ管理書やデータガバナンス実践書による学習が効果的です。
リアルタイムデータ統合の需要が高まる現在では、ストリーミング処理技術も重要になっています。Apache Kafka、Apache Storm、Apache Flinkなどの技術について、ストリーミング処理技術書で学習することで、最新のデータ統合要件に対応できます。
データ品質管理とデータプロファイリング
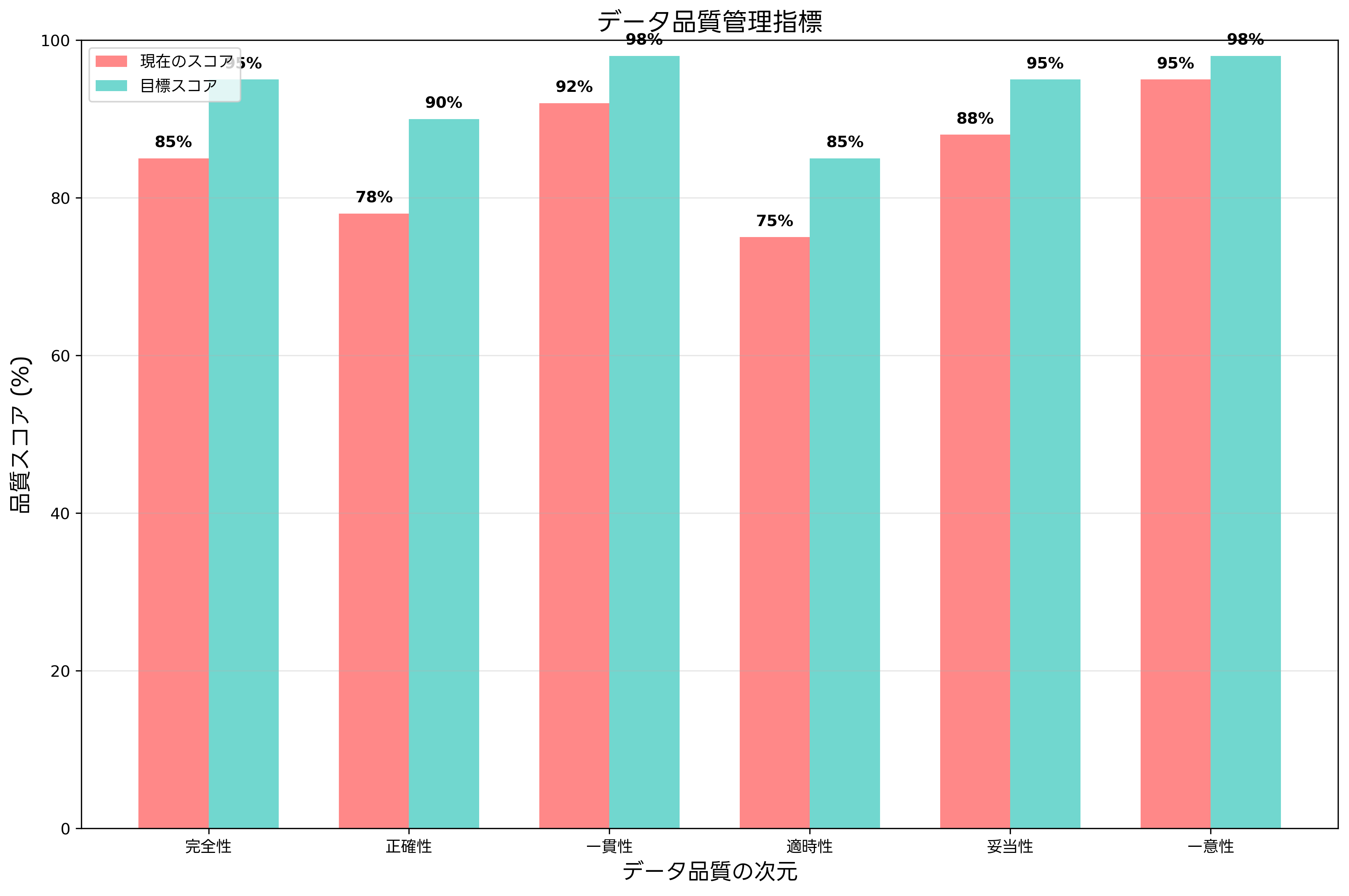
データ品質は、データモデリングの成果を実際のビジネス価値に変換するための重要な要素です。高品質なデータは、正確な分析結果と信頼性の高い意思決定を支える基盤となります。データ品質管理では、完全性、正確性、一貫性、適時性、妥当性、一意性という6つの次元から品質を評価します。
データプロファイリングは、既存データの内容、構造、品質を体系的に分析するプロセスです。データの分布、欠損値の割合、重複レコードの識別、参照整合性の検証などを通じて、データの現状を定量的に把握します。この作業には、データプロファイリングツールが有効であり、大量データの分析を自動化できます。
データクレンジングは、発見された品質問題を修正するプロセスです。標準化、正規化、重複排除、欠損値補完などの技術を適用して、データの品質を向上させます。効果的なクレンジングには、データクレンジングソフトウェアの活用が重要であり、ルールベースの自動修正機能により作業効率を大幅に向上させることができます。
データ品質の継続的な監視も重要な要素です。データ品質メトリクスを定義し、定期的に測定することで、品質の劣化を早期に検出できます。データ品質監視ツールを導入することで、自動的な品質チェックとアラート機能を実現できます。
データ品質管理の組織的な取り組みでは、データスチュワードの役割が重要になります。各業務領域の専門知識を持つデータスチュワードが、データの意味や品質基準を定義し、日常的な品質管理活動を推進します。この分野の知識向上には、データスチュワードシップ書が参考になります。
次元モデリングとデータウェアハウス設計
次元モデリングは、データウェアハウスやデータマートの設計で使用される特殊なモデリング手法です。分析業務に特化した設計により、複雑な集計クエリを効率的に実行できるデータ構造を実現します。
次元モデリングの中核概念は、ファクトテーブルとディメンションテーブルです。ファクトテーブルには測定可能な業績指標(売上高、数量など)を格納し、ディメンションテーブルには分析の切り口となる属性情報(時間、地域、商品など)を格納します。このスタースキーマ構造により、直感的で高速な分析クエリが可能になります。
実際の次元モデリングでは、緩やかに変化するディメンション(SCD:Slowly Changing Dimension)の処理が重要な設計課題となります。Type 1からType 6まで定義されたSCDタイプを適切に選択し、履歴データの管理方法を決定します。この分野では、データウェアハウス専門書による深い理解が必要です。
現代のデータウェアハウス設計では、従来のバッチ処理に加えて、リアルタイム分析の要件も考慮する必要があります。Lambda アーキテクチャやKappa アーキテクチャなどの最新パターンについて、リアルタイム分析アーキテクチャ書で学習することが有効です。
クラウド環境でのデータウェアハウス構築が主流となっている現在では、Amazon Redshift、Google BigQuery、Microsoft Azure Synapse Analyticsなどのマネージドサービスの特性を理解することも重要です。クラウドデータウェアハウス設計書により、これらのサービスを効果的に活用する方法を学習できます。
データガバナンスとメタデータ管理
データガバナンスは、組織のデータ資産を戦略的に管理するための包括的なフレームワークです。データの価値を最大化し、リスクを最小化するために、ポリシー、プロセス、組織構造を定義します。
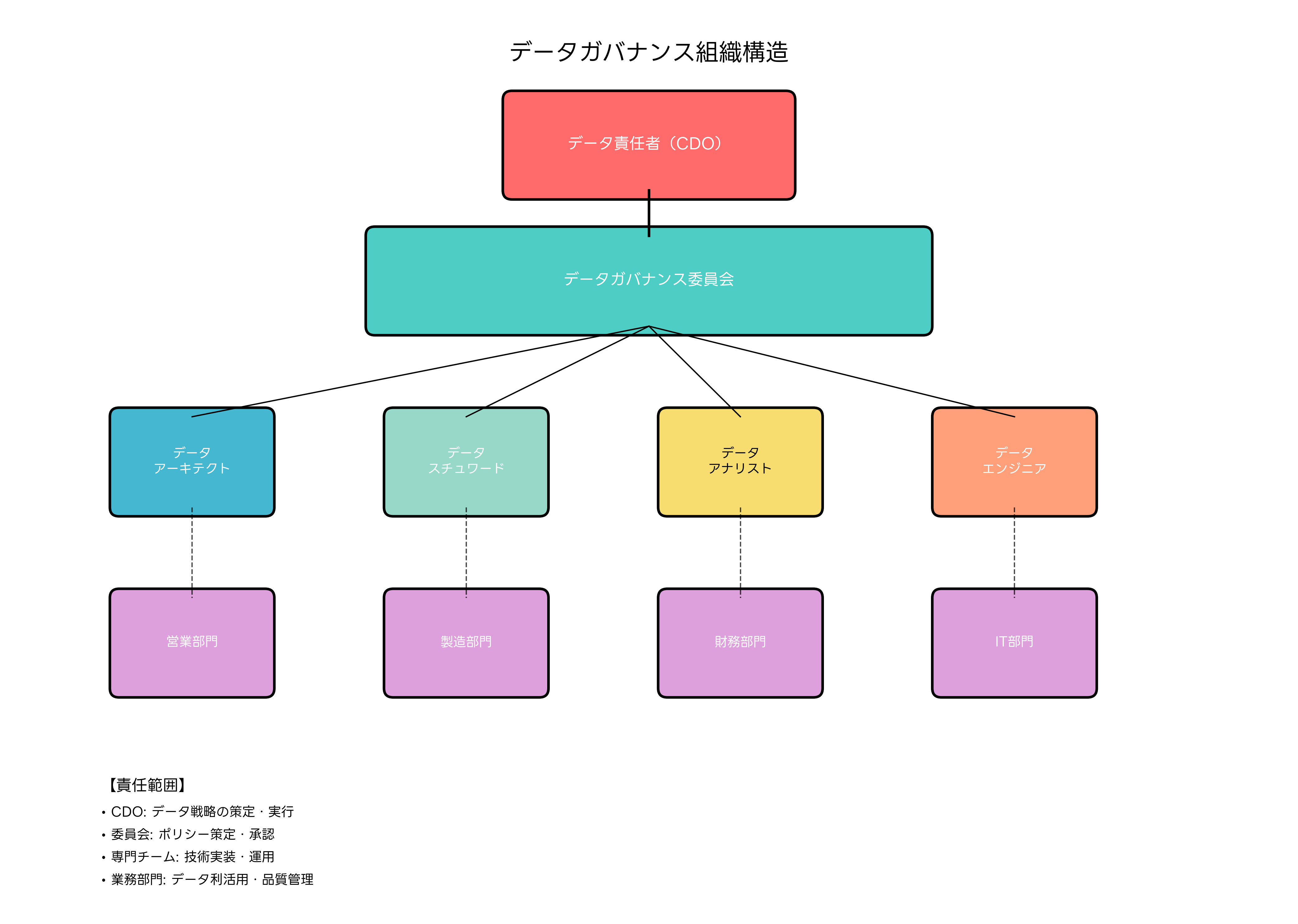
効果的なデータガバナンスには、明確な組織構造の確立が不可欠です。データ責任者(CDO:Chief Data Officer)を頂点として、データガバナンス委員会、データスチュワード、データアーキテクト、データエンジニアなどの役割を明確に定義します。各役割の責任範囲と権限を明文化することで、組織全体でのデータ管理が効果的に機能します。
メタデータ管理は、データガバナンスの中核的な活動の一つです。技術メタデータ、ビジネスメタデータ、運用メタデータを体系的に管理することで、データの理解可能性と利用効率を向上させます。メタデータ管理ツールを導入することで、大規模なデータ環境でも効率的なメタデータ管理が可能になります。
データリネージュ(系譜)の追跡も重要な要素です。データがどこから来て、どのような変換を経て、どこで利用されているかを可視化することで、データの信頼性向上と影響分析が可能になります。データリネージュツールにより、複雑なデータフローの自動追跡が実現できます。
データプライバシーとセキュリティの管理も、現代のデータガバナンスで重要な側面です。GDPR、個人情報保護法などの法規制への対応や、データアクセス制御、暗号化、匿名化などの技術的対策を統合的に管理します。この分野では、データプライバシー管理書による学習が効果的です。
応用情報技術者試験での出題傾向と対策
応用情報技術者試験におけるデータモデリング分野は、午前問題と午後問題の両方で出題される重要な領域です。午前問題では、ERモデルの基本概念、正規化理論、データベース設計の原則などが問われます。
午前問題の対策では、ERモデルの表記法や多重度の解釈、正規化の各段階における変換ルール、関数従属性の理解などが重要です。特に、実際のビジネス要件からERモデルを作成する問題や、正規化前後のテーブル構造を比較する問題が頻出します。応用情報技術者試験データベース分野問題集を活用して、出題パターンを把握することが効果的です。
午後問題では、より実践的な設計問題が出題されます。与えられた業務要件からデータモデルを設計し、適切なテーブル構造やSQLクエリを考える能力が求められます。このような問題では、要件の読み取り能力、設計の論理的思考、最適化の観点が評価されます。
試験対策としては、理論的な知識に加えて、実際のデータベース設計経験を積むことが重要です。データベース実習環境構築書を参考にして、実際にデータベースを設計・構築する練習を行うことで、理論と実践の両方を身につけることができます。
最新の技術動向も試験範囲に含まれることがあります。NoSQLデータベース、ビッグデータ処理、クラウドデータベースなどの概念について、最新データベース技術動向書で学習しておくことが有効です。
実践的なデータモデリング手法とベストプラクティス
実際のプロジェクトでデータモデリングを成功させるためには、理論的な知識に加えて、実践的な手法とベストプラクティスの理解が重要です。まず、ステークホルダーとの効果的なコミュニケーションが設計品質を左右します。
要件定義段階では、業務担当者へのインタビュー技法が重要になります。適切な質問設計により、暗黙知となっている業務ルールや例外処理を明確にします。要件定義実践書を参考にして、効果的なヒアリング手法を身につけることが有効です。
プロトタイピングアプローチも有効な手法です。初期段階で簡単なデータモデルを作成し、サンプルデータを投入してステークホルダーと検証を行います。この反復的なアプローチにより、要件の理解不足や設計上の問題を早期に発見できます。アジャイル開発手法書で、反復的な設計手法について学習できます。
データモデリングの成果物は、技術者だけでなく業務担当者にも理解できる形で文書化することが重要です。ERモデルの表記法を統一し、説明文書を充実させることで、長期的なメンテナンス性を確保します。システム設計文書作成書により、効果的な文書化手法を学習できます。
パフォーマンス考慮も実践的な設計では重要な要素です。理論的に正しい正規化だけでなく、実際のアクセスパターンや処理性能を考慮した設計判断が必要です。データベースパフォーマンス設計書で、実践的な最適化手法を学習することが効果的です。
まとめ
データモデリングは、情報システム設計の基盤となる重要な技術領域です。ERモデルによる概念設計から正規化による論理設計、物理設計に至るまでの一連のプロセスを理解し、実践することで、高品質なシステムを構築できます。
応用情報技術者試験においても重要な出題分野であり、理論的な理解と実践的な応用能力の両方が求められます。継続的な学習と実践により、変化するビジネス要件や技術環境に対応できる設計能力を身につけることが重要です。
現代のデータ環境では、従来の構造化データに加えて、多様なデータ形式やリアルタイム処理への対応も求められています。データガバナンスとデータ品質管理を含めた包括的なアプローチにより、組織のデータ資産を価値あるものに変換し、競争優位性の確保に貢献できるデータモデリング専門家を目指しましょう。
技術の進歩とともに、データモデリングの手法や適用範囲も拡大し続けています。新しい技術動向を継続的に学習し、実践的なスキルを磨くことで、デジタル変革の時代において重要な役割を果たすことができます。