データサイエンスは、現代社会において最も注目される技術分野の一つです。膨大なデータから価値ある洞察を抽出し、ビジネスの意思決定を支援する手法として、あらゆる業界で活用が進んでいます。応用情報技術者試験においても、データサイエンスの基本概念や手法は重要な出題範囲となっており、IT技術者にとって必須の知識となっています。
データサイエンスとは、統計学、数学、コンピューターサイエンス、そしてドメイン知識を組み合わせて、データから意味のある情報やパターンを抽出する学際的な分野です。この分野は、機械学習、統計分析、データマイニング、ビッグデータ処理などの技術を駆使して、複雑な問題解決とビジネス価値の創出を目指しています。
データサイエンスの基本概念と重要性
データサイエンスの本質は、データドリブンな意思決定を可能にすることです。従来の経験や直感に基づく判断から脱却し、客観的なデータに基づいた合理的な意思決定を実現します。この変革により、企業は競争優位を獲得し、新たなビジネス機会を発見することができます。
現代の企業が生成するデータ量は爆発的に増加しており、IDC(International Data Corporation)の予測によると、世界のデータ生成量は2025年までに175ゼタバイトに達すると見込まれています。このような大量のデータを効果的に活用するためには、高性能なデータ処理システムや専門的な分析ツールの導入が必要不可欠です。
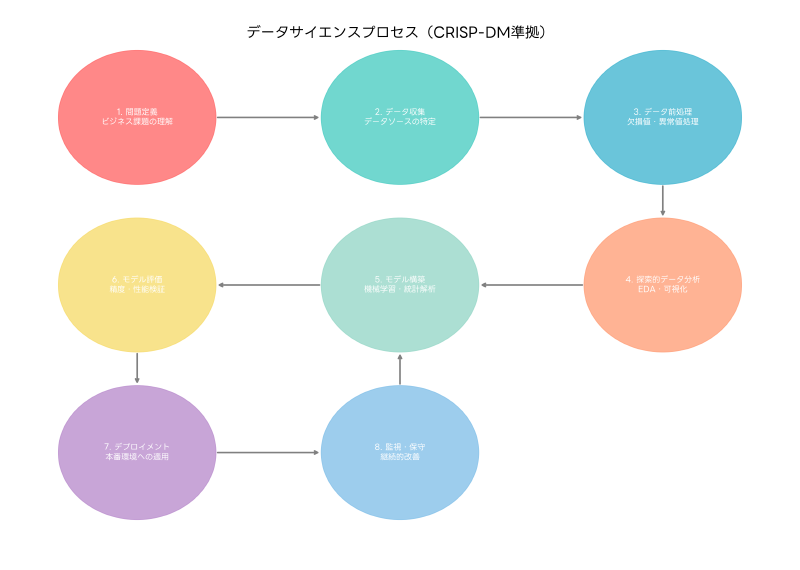
データサイエンスのプロセスは、一般的にCRISP-DM(Cross Industry Standard Process for Data Mining)モデルに従って進行します。このプロセスには、ビジネス理解、データ理解、データ準備、モデリング、評価、展開の6つのフェーズが含まれます。各フェーズは相互に関連しており、反復的に実行されることで、より精度の高い分析結果を得ることができます。
ビジネス理解フェーズでは、解決すべき問題の明確化とプロジェクトの目標設定を行います。この段階では、ステークホルダーとの密接な協力により、ビジネス要件を技術的な問題に変換します。効果的なプロジェクト管理には、プロジェクト管理ソフトウェアの活用が推奨されます。
データ収集と前処理技術
データ収集は、データサイエンスプロジェクトの基盤となる重要なプロセスです。データソースは多岐にわたり、構造化データ(データベース、スプレッドシート)、半構造化データ(JSON、XML)、非構造化データ(テキスト、画像、音声)などがあります。これらの多様なデータソースから効率的にデータを収集するためには、データ統合プラットフォームやETLツールの活用が有効です。
データの品質は分析結果に直接的な影響を与えるため、データクレンジングとデータ前処理は極めて重要です。現実のデータには、欠損値、重複データ、異常値、不整合などの問題が頻繁に発生します。これらの問題を解決するため、統計的手法やドメイン知識を用いた適切な前処理を実施する必要があります。
欠損値の処理には、削除、補完、推定などの手法があります。補完手法には、平均値補完、中央値補完、最頻値補完、回帰補完、機械学習を用いた高度な補完などがあります。異常値の検出と処理には、統計的手法(標準偏差、四分位範囲)や機械学習手法(孤立森林、LOF)を活用します。
データの統合と変換も重要なプロセスです。異なるソースから収集されたデータを統一的な形式に変換し、分析に適した構造に整備します。この過程では、データの正規化、標準化、カテゴリ変数のエンコーディング、特徴量エンジニアリングなどの技術を駆使します。効率的な前処理作業には、データ前処理専用ソフトウェアの導入が効果的です。
統計分析と機械学習手法
統計分析は、データサイエンスの根幹を成す技術です。記述統計により、データの分布、中心傾向、散らばりを把握し、推測統計により、サンプルから母集団の特性を推定します。仮説検定により、データから得られた知見の統計的有意性を検証し、信頼性の高い結論を導き出します。
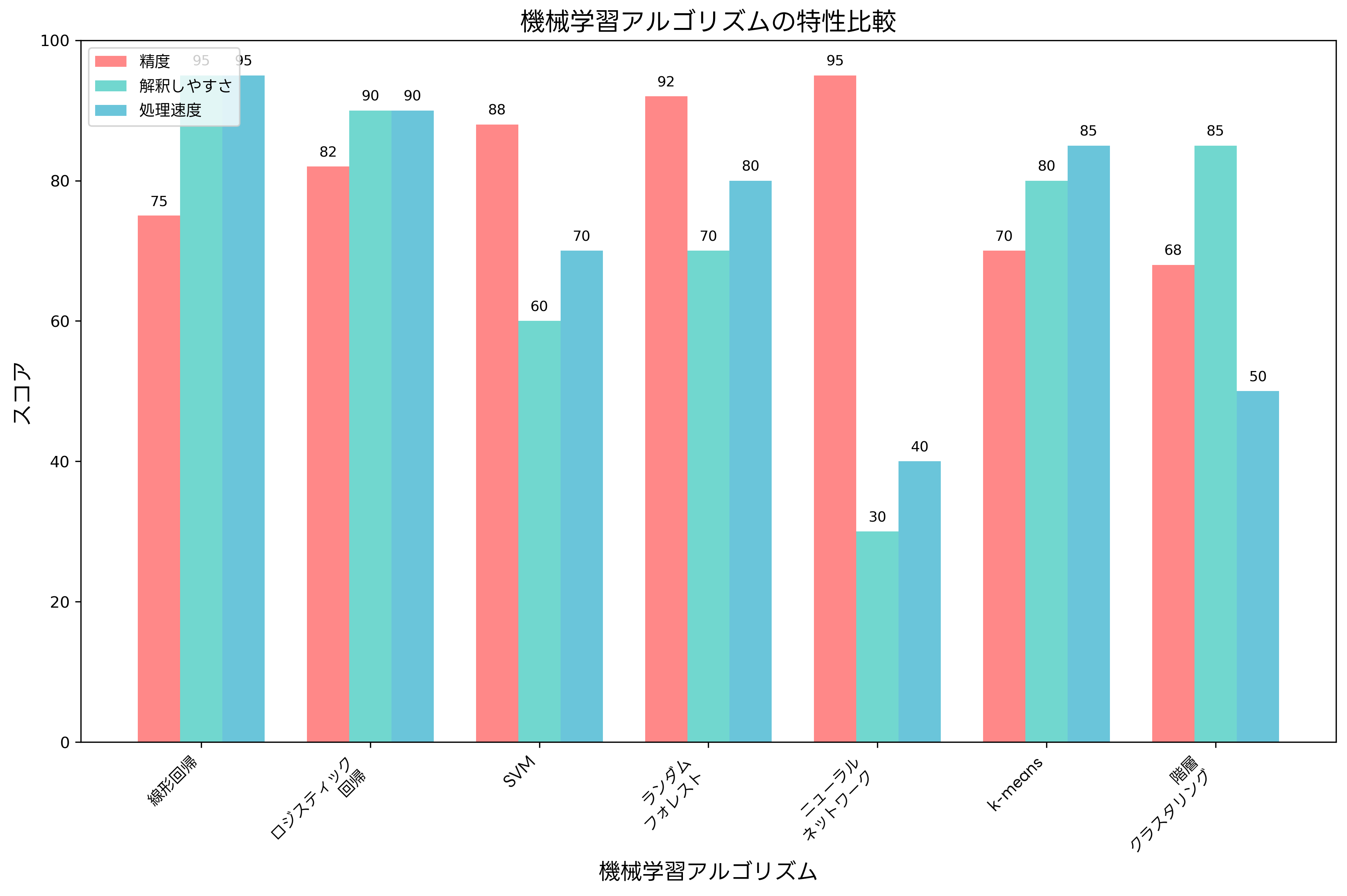
機械学習は、データからパターンを学習し、予測や分類を行う技術です。教師あり学習では、正解ラベル付きのデータを用いて予測モデルを構築します。回帰問題では連続値を、分類問題では離散的なカテゴリを予測します。代表的なアルゴリズムには、線形回帰、ロジスティック回帰、決定木、ランダムフォレスト、サポートベクターマシン、ニューラルネットワークなどがあります。
教師なし学習では、正解ラベルなしのデータからパターンを発見します。クラスタリングにより、類似したデータを群に分類し、次元削減により、高次元データを低次元空間に投影してデータの可視化や計算効率化を実現します。代表的な手法には、k-means、階層クラスタリング、主成分分析、t-SNEなどがあります。
深層学習(ディープラーニング)は、多層ニューラルネットワークを用いた機械学習手法です。画像認識、自然言語処理、音声認識などの分野で画期的な成果を上げています。深層学習の実装には、高性能GPUワークステーションや専用の開発環境が必要です。
アンサンブル学習は、複数のモデルを組み合わせて予測精度を向上させる手法です。バギング、ブースティング、スタッキングなどの手法により、単一モデルでは実現できない高い予測性能を達成できます。実際の運用では、アンサンブル学習フレームワークの活用により、効率的なモデル構築が可能になります。
ビッグデータ技術とクラウドコンピューティング
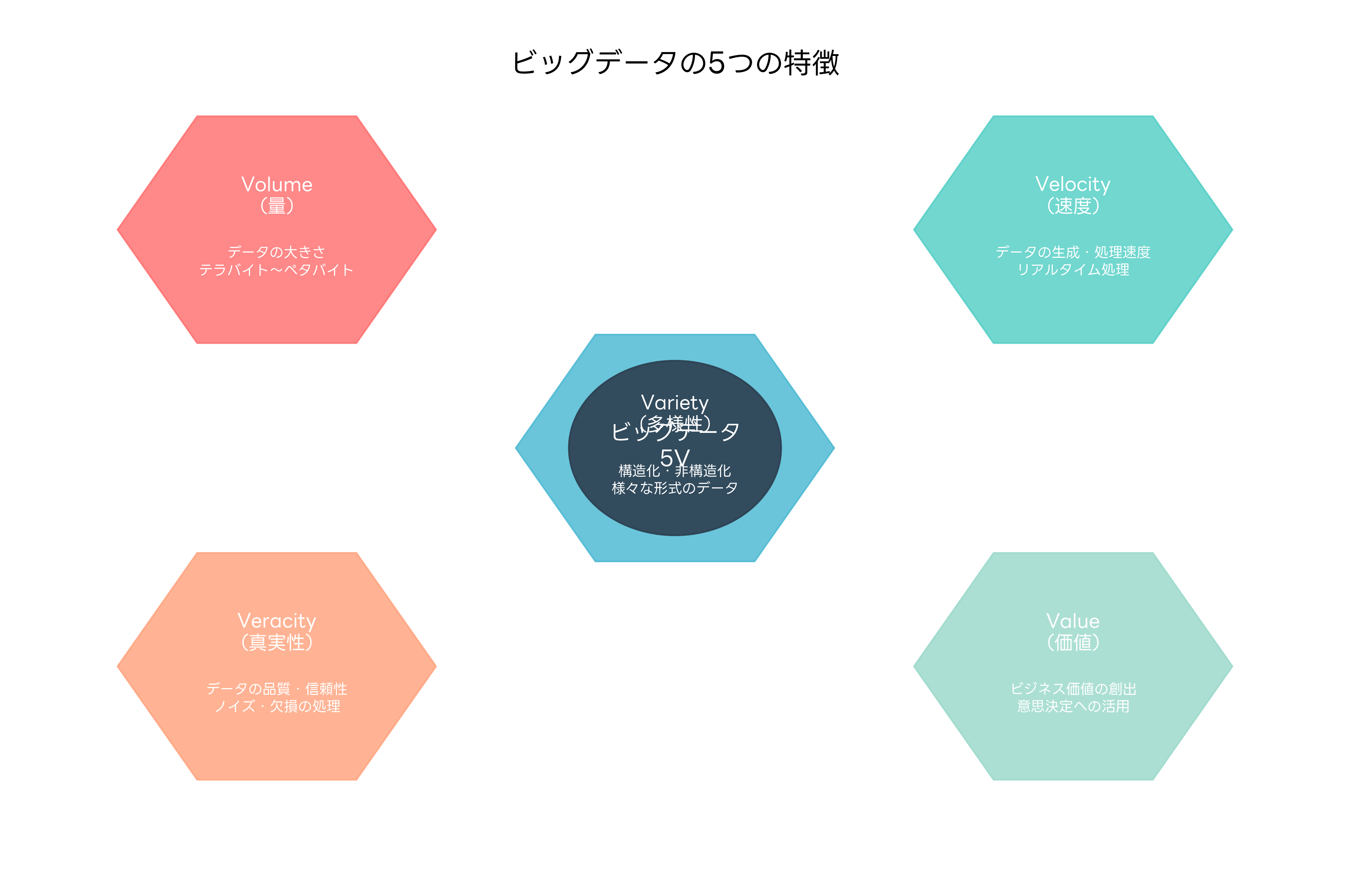
ビッグデータは、従来のデータ処理技術では扱いきれない大量、高速、多様なデータを指します。ビッグデータの特徴は、5つのV(Volume、Velocity、Variety、Veracity、Value)で表現されます。これらの特徴を持つデータを効果的に処理するためには、分散処理技術とスケーラブルなインフラストラクチャが必要です。
Apache Hadoopは、分散ストレージ(HDFS)と分散処理(MapReduce)を提供するオープンソースフレームワークです。大量のデータを複数のサーバーに分散保存し、並列処理により高速な分析を実現します。Hadoop生態系には、Hive、Pig、HBase、Sparkなどの多様なツールが含まれており、様々な用途に対応できます。
Apache Sparkは、インメモリ処理により高速なデータ処理を実現するフレームワークです。MapReduceと比較して、反復処理において大幅な性能向上を実現します。Sparkは、バッチ処理、ストリーミング処理、機械学習、グラフ処理など、統一されたAPIで多様なワークロードに対応します。
クラウドコンピューティングは、データサイエンスプロジェクトの効率化とコスト削減に大きく貢献します。Amazon Web Services、Microsoft Azure、Google Cloud Platformなどの主要クラウドプロバイダーは、データサイエンス向けのマネージドサービスを提供しています。これらのサービスには、クラウドデータ分析プラットフォームやクラウドMLサービスが含まれます。
ストリーミング処理は、リアルタイムでデータを処理する技術です。Apache Kafka、Apache Storm、Apache Flinkなどのツールにより、連続的に生成されるデータをリアルタイムで分析し、即座に洞察を得ることができます。IoTデバイスからのセンサーデータ、Webサイトのクリックストリーム、金融取引データなどの処理に活用されます。
データサイエンスツールとプラットフォーム
データサイエンスプロジェクトを効率的に実行するためには、適切なツールとプラットフォームの選択が重要です。プログラミング言語では、PythonとRが最も広く使用されており、それぞれ豊富なライブラリとフレームワークを提供します。
Pythonは、その汎用性と豊富なライブラリにより、データサイエンスの事実上の標準となっています。NumPy、Pandas、Matplotlib、Scikit-learn、TensorFlow、PyTorchなどの強力なライブラリにより、データ処理から機械学習まで一貫した開発が可能です。Python開発環境の構築には、Python統合開発環境やJupyter Notebook環境の活用が推奨されます。
Rは、統計解析に特化した言語として、学術分野や統計解析を重視する分野で広く使用されています。CRAN(Comprehensive R Archive Network)には、10,000を超えるパッケージが登録されており、高度な統計解析機能を提供します。R言語による分析では、R専用開発環境の導入が効果的です。
Jupyter Notebookは、インタラクティブな分析環境として広く採用されています。コード、可視化結果、説明文書を単一の文書にまとめることで、再現可能で共有しやすい分析レポートを作成できます。JupyterLabは、Jupyter Notebookの進化版として、より統合された開発環境を提供します。
データ可視化は、分析結果を効果的に伝達するための重要な技術です。Matplotlib、Seaborn、Plotly(Python)、ggplot2、Plotly(R)などのライブラリにより、静的および動的な可視化を実現できます。ビジネスインテリジェンス(BI)ツールとしては、Tableau、Power BI、QlikViewなどが広く使用されており、技術者以外のユーザーでも直感的にデータを探索できます。これらのツールには、ビジネスインテリジェンスソフトウェアとして統合されたソリューションも提供されています。
データサイエンス職種とキャリアパス
データサイエンス分野は、多様な職種と専門性を持つ人材が協働する学際的な領域です。データサイエンティスト、データアナリスト、機械学習エンジニア、データエンジニア、ビジネスアナリストなど、それぞれ異なる役割と責任を担います。
データサイエンティストは、統計学、機械学習、プログラミング、ビジネス理解のバランスの取れたスキルを持つ専門家です。複雑なビジネス問題を技術的な問題に変換し、データを用いて解決策を提供します。この職種には、データサイエンス専門書による継続的な学習と、実践的なデータセットを用いた実習が重要です。
データアナリストは、データの収集、整理、分析を通じて、ビジネスの意思決定を支援します。SQLによるデータ抽出、Excelやタブローによる可視化、基本的な統計分析が主な業務内容です。データアナリストのスキル向上には、データ分析実践ガイドやSQL学習教材の活用が効果的です。
機械学習エンジニアは、機械学習モデルの開発、実装、運用に特化した専門家です。モデルの性能最適化、スケーラブルなシステムの構築、MLOps(Machine Learning Operations)の実装が主な責任範囲です。この分野の専門性向上には、機械学習エンジニアリング書籍やMLOps実践ガイドが有用です。
データエンジニアは、データパイプラインの設計、構築、保守を担当します。大量のデータを効率的に処理するためのインフラストラクチャの構築と運用が主な業務です。クラウドプラットフォーム、分散処理技術、データベース管理システムの深い知識が求められます。データエンジニアのスキル向上には、データエンジニアリング実践書や分散システム設計書が推奨されます。
ビジネスアナリストは、ビジネス要件の定義、ステークホルダーとの調整、分析結果のビジネス価値への変換を担当します。技術的な専門性よりも、ビジネス理解とコミュニケーション能力が重視される職種です。この分野では、ビジネス分析手法書やデータドリブン意思決定ガイドの学習が有効です。
プロジェクト成功要因と失敗回避
データサイエンスプロジェクトの成功率を向上させるためには、技術的な要素だけでなく、組織的な要素も重要です。明確な問題設定、データ品質の確保、適切な手法選択、ステークホルダーとの継続的な連携が成功の鍵となります。
問題設定の明確化は、プロジェクトの方向性を決定する最も重要な要素です。ビジネス課題を技術的に解決可能な問題に変換し、成功指標と制約条件を明確に定義する必要があります。この段階では、ステークホルダーとの密接な協力により、期待値の調整と合意形成を行います。効果的な要件定義には、要件定義手法書の活用が推奨されます。
データ品質の確保は、分析結果の信頼性に直結する重要な要素です。データの完全性、一貫性、正確性、鮮度を継続的に監視し、品質問題を早期に発見・修正する仕組みが必要です。データ品質管理には、データ品質管理ツールやデータプロファイリングソフトウェアの導入が効果的です。
適切な手法選択は、問題の性質とデータの特性に基づいて決定されます。シンプルな手法から始めて段階的に複雑な手法を適用するアプローチにより、解釈しやすく実用的なモデルを構築できます。過度に複雑なモデルは、オーバーフィッティングや解釈困難性の問題を引き起こす可能性があります。
チームのスキル開発と継続的な学習も重要な成功要因です。データサイエンス分野は急速に進歩しており、最新の技術動向と手法を継続的に学習する必要があります。社内勉強会、外部研修、オンライン学習プラットフォームの活用により、チーム全体のスキル向上を図ります。効果的な学習には、データサイエンス学習プラットフォームや技術書籍セットの活用が有効です。
プロジェクト管理の観点では、アジャイル開発手法の適用により、変化する要求に柔軟に対応できます。短期間でのプロトタイプ開発と検証を繰り返すことで、リスクを最小化し、価値の高いソリューションを効率的に開発できます。
応用情報技術者試験での出題傾向
応用情報技術者試験におけるデータサイエンス関連の出題は、近年増加傾向にあります。午前問題では、統計学の基礎、機械学習アルゴリズムの特性、ビッグデータ技術、データベース管理などが頻出テーマです。午後問題では、具体的なビジネスシナリオにおけるデータ分析手法の選択、分析結果の解釈、システム設計などが問われます。
統計学の基礎では、平均、分散、標準偏差、相関係数などの記述統計量の計算と解釈、確率分布、仮説検定の概念が重要です。これらの知識は、データの特性理解とモデルの評価に直結するため、確実に習得する必要があります。統計学の学習には、統計学基礎教材や統計解析ソフトウェアの活用が効果的です。
機械学習アルゴリズムでは、各手法の適用場面、長所・短所、パラメータの意味などの理解が求められます。教師あり学習と教師なし学習の違い、回帰と分類の使い分け、モデルの評価指標(精度、再現率、F1スコアなど)の理解が重要です。
ビッグデータ技術では、分散処理の概念、Hadoop生態系、NoSQLデータベースの特性などが出題されます。スケーラビリティ、可用性、一貫性のトレードオフ関係、CAP定理の理解が重要です。これらの技術習得には、ビッグデータ技術書や分散システム実践ガイドが有用です。
試験対策としては、応用情報技術者試験対策書による体系的な学習と、過去問題集による実践的な演習が効果的です。また、実際のデータを用いた分析経験により、理論と実践の橋渡しを行うことが重要です。
実践的なプロジェクト事例
データサイエンスの理解を深めるため、具体的なプロジェクト事例を通じて実践的な適用方法を学習することが重要です。顧客セグメンテーション、需要予測、異常検知、推薦システムなど、様々な業界で活用されている代表的な事例を詳しく解説します。
顧客セグメンテーションでは、顧客の行動データや属性データを用いて、類似した特性を持つ顧客グループを識別します。k-meansクラスタリングや階層クラスタリングなどの教師なし学習手法を適用し、各セグメントの特性を分析します。この分析により、ターゲットマーケティング、商品開発、価格戦略の最適化が可能になります。実践的な顧客分析には、顧客分析実践書やマーケティング分析ツールの活用が効果的です。
需要予測では、時系列データを用いて将来の販売量や需要量を予測します。ARIMA、季節分解、指数平滑法などの古典的な時系列解析手法に加えて、機械学習手法(ランダムフォレスト、LSTMなど)も活用されています。正確な需要予測により、在庫最適化、生産計画、人員配置などの効率化が実現できます。
異常検知では、正常なパターンから逸脱したデータポイントを識別します。統計的手法(Z-score、四分位範囲)、機械学習手法(孤立森林、One-Class SVM)、深層学習手法(オートエンコーダー)などを適用します。製造業での品質管理、金融業での不正検知、ITシステムの監視などで広く活用されています。
推薦システムでは、協調フィルタリング、コンテンツベースフィルタリング、行列因子分解などの手法を用いて、ユーザーの嗜好に基づいた商品やコンテンツの推薦を行います。Eコマース、動画配信、音楽ストリーミングなどのサービスで中核的な役割を果たしています。
これらの事例に共通する成功要因は、ビジネス目標の明確化、適切なデータの収集と前処理、手法の選択と調整、継続的な改善プロセスの確立です。また、技術的な精度だけでなく、ビジネス価値の創出と運用の実現可能性も重要な考慮事項です。
倫理とプライバシーの考慮事項
データサイエンスの実践において、倫理とプライバシーの配慮は不可欠な要素です。個人情報保護法、GDPR(一般データ保護規則)、CCPA(カリフォルニア州消費者プライバシー法)などの法規制への対応だけでなく、社会的責任としての倫理的な配慮が求められています。
データ収集時には、インフォームドコンセントの取得、目的の明示、最小限の原則(必要最小限のデータのみ収集)の遵守が重要です。個人を特定可能な情報の匿名化・仮名化処理により、プライバシーリスクを最小化します。技術的対策としては、差分プライバシー、同型暗号、セキュアマルチパーティ計算などの技術が注目されています。プライバシー保護技術の実装には、プライバシー保護技術書やデータ匿名化ソフトウェアの活用が推奨されます。
アルゴリズムの公平性も重要な課題です。機械学習モデルは、訓練データに含まれるバイアスを学習し、差別的な判定を行う可能性があります。性別、人種、年齢などの属性による不公平な扱いを防ぐため、バイアス検出手法と公平性制約を組み込んだモデル開発が必要です。
透明性と説明可能性も重要な要素です。特に、人事評価、与信審査、医療診断などの重要な意思決定に AI が関与する場合、その判定根拠を説明できることが求められます。LIME、SHAP、Grad-CAMなどの説明可能AI技術により、モデルの判定根拠を可視化・解釈することが可能です。
最新技術動向と将来展望
データサイエンス分野は急速に進歩しており、新しい技術と手法が継続的に開発されています。AutoML(自動機械学習)により、機械学習モデルの構築プロセスが自動化され、専門知識を持たないユーザーでも高品質なモデルを構築できるようになりました。AutoML技術の活用には、AutoML実践ガイドや自動機械学習ツールが有用です。
MLOps(Machine Learning Operations)は、機械学習モデルの開発、デプロイ、運用を効率化する手法です。継続的インテグレーション、継続的デプロイ、モデルの監視とメンテナンスを自動化することで、本番環境での安定したモデル運用を実現します。MLOpsの実践には、MLOps実装ガイドや MLOpsプラットフォームの導入が効果的です。
エッジAIは、クラウドではなくデバイス上で機械学習の推論を実行する技術です。レスポンス時間の短縮、プライバシーの保護、通信コストの削減などの利点があります。IoTデバイス、スマートフォン、自動運転車などで広く活用されています。
量子機械学習は、量子コンピューターの計算能力を機械学習に活用する新しい分野です。従来のコンピューターでは解決困難な最適化問題や組合せ問題の解決に期待が寄せられています。まだ実用段階ではありませんが、将来的には革新的な進歩をもたらす可能性があります。
フェデレーテッドラーニングは、データを中央に集約することなく、分散した環境で機械学習モデルを訓練する手法です。プライバシー保護と通信効率の向上を実現し、医療、金融、IoTなどの分野での活用が期待されています。
これらの先進技術は、データサイエンスの可能性を大幅に拡大し、新しいビジネス機会と社会的価値を創出することが期待されています。継続的な技術動向のキャッチアップと実践的な経験の蓄積により、これらの技術を効果的に活用できる人材の育成が重要です。
まとめ
データサイエンスは、現代のデジタル社会において不可欠な技術分野として確立されています。統計学、機械学習、ビッグデータ技術、プログラミングスキルを統合し、ビジネス価値の創出と社会課題の解決に貢献しています。応用情報技術者試験においても重要な出題分野となっており、IT技術者にとって必須の知識となっています。
成功するデータサイエンスプロジェクトには、技術的な専門性だけでなく、ビジネス理解、コミュニケーション能力、倫理的配慮が必要です。継続的な学習と実践により、変化する技術環境に対応できる能力を身につけることが重要です。
データサイエンスの将来は明るく、AutoML、MLOps、エッジAI、量子機械学習などの新技術により、さらなる発展が期待されています。これらの技術を効果的に活用し、持続可能で倫理的なデータサイエンスの実践により、より良い社会の実現に貢献することが私たちの使命です。