文字エンコーディングは、コンピュータが文字を処理するための基盤技術として、現代のデジタル社会を支える重要な概念です。応用情報技術者試験においても頻繁に出題される分野であり、Webアプリケーション開発、データベース設計、国際化対応など、様々な場面で正確な理解が求められます。文字化けやデータ破損といった問題を回避し、グローバルなシステム開発を行うためには、エンコーディングの仕組みを深く理解することが不可欠です。
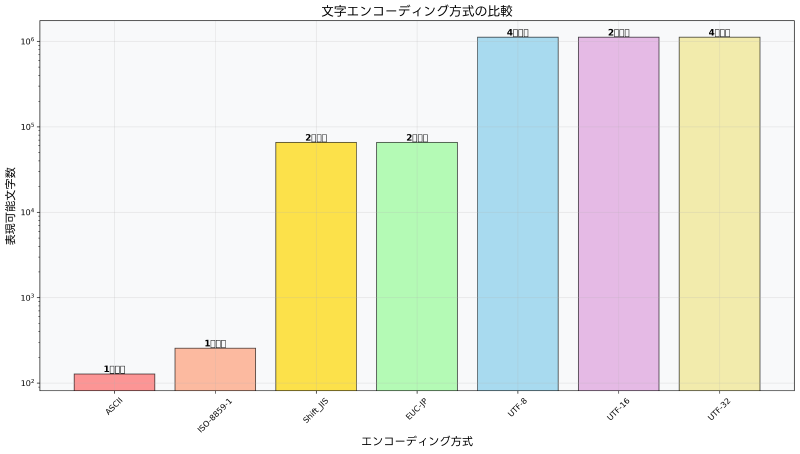
エンコーディングとは、人間が理解できる文字や記号を、コンピュータが処理できるデジタルデータ(バイト列)に変換する規則や方式のことです。この変換プロセスにより、世界中の多様な言語や文字体系をコンピュータ上で統一的に扱うことが可能になります。現代では、ASCII、ISO-8859、Shift_JIS、UTF-8、UTF-16など、様々なエンコーディング方式が存在し、それぞれ異なる特徴と用途を持っています。
エンコーディングの歴史的発展
文字エンコーディングの歴史は、コンピュータ技術の発展と密接に関連しています。初期のコンピュータシステムでは、英語のアルファベットと基本的な記号のみを扱うASCII(American Standard Code for Information Interchange)が標準として使用されていました。ASCIIは7ビット(128文字)の文字セットで、英語圏での文字処理には十分でしたが、他の言語への対応は困難でした。
その後、ヨーロッパ言語への対応としてISO-8859シリーズが開発され、8ビット(256文字)の文字セットにより、西欧言語の特殊文字を含む文字表現が可能になりました。しかし、これらの方式では、アジア言語のような数千から数万の文字を持つ言語系統には対応できませんでした。
日本語の文字エンコーディングとしては、Shift_JIS、EUC-JP、ISO-2022-JPなどが開発されました。Shift_JISは、日本語対応の業務システムで広く使用され、特にWindowsプラットフォームでの標準エンコーディングとして普及しました。しかし、これらの方式は特定の言語や地域に特化していたため、国際的なデータ交換には限界がありました。
この問題を解決するために、1991年にUnicodeコンソーシアムによってUnicode標準が策定されました。Unicodeは、世界中のすべての文字を統一的に表現することを目的とした文字コード標準であり、現在では100万文字以上の文字を収録しています。Unicode標準に基づくUTF-8、UTF-16、UTF-32などのエンコーディング方式により、言語や地域を超えたグローバルな文字処理が実現されています。
UTF-8エンコーディングの詳細構造
UTF-8(8-bit Unicode Transformation Format)は、現在最も広く使用されているUnicodeエンコーディング方式です。可変長エンコーディングという特徴を持ち、文字によって1バイトから4バイトまで異なる長さで表現されます。この設計により、ASCII文字との完全な互換性を保ちながら、世界中のすべての文字を表現できる効率的なシステムを実現しています。
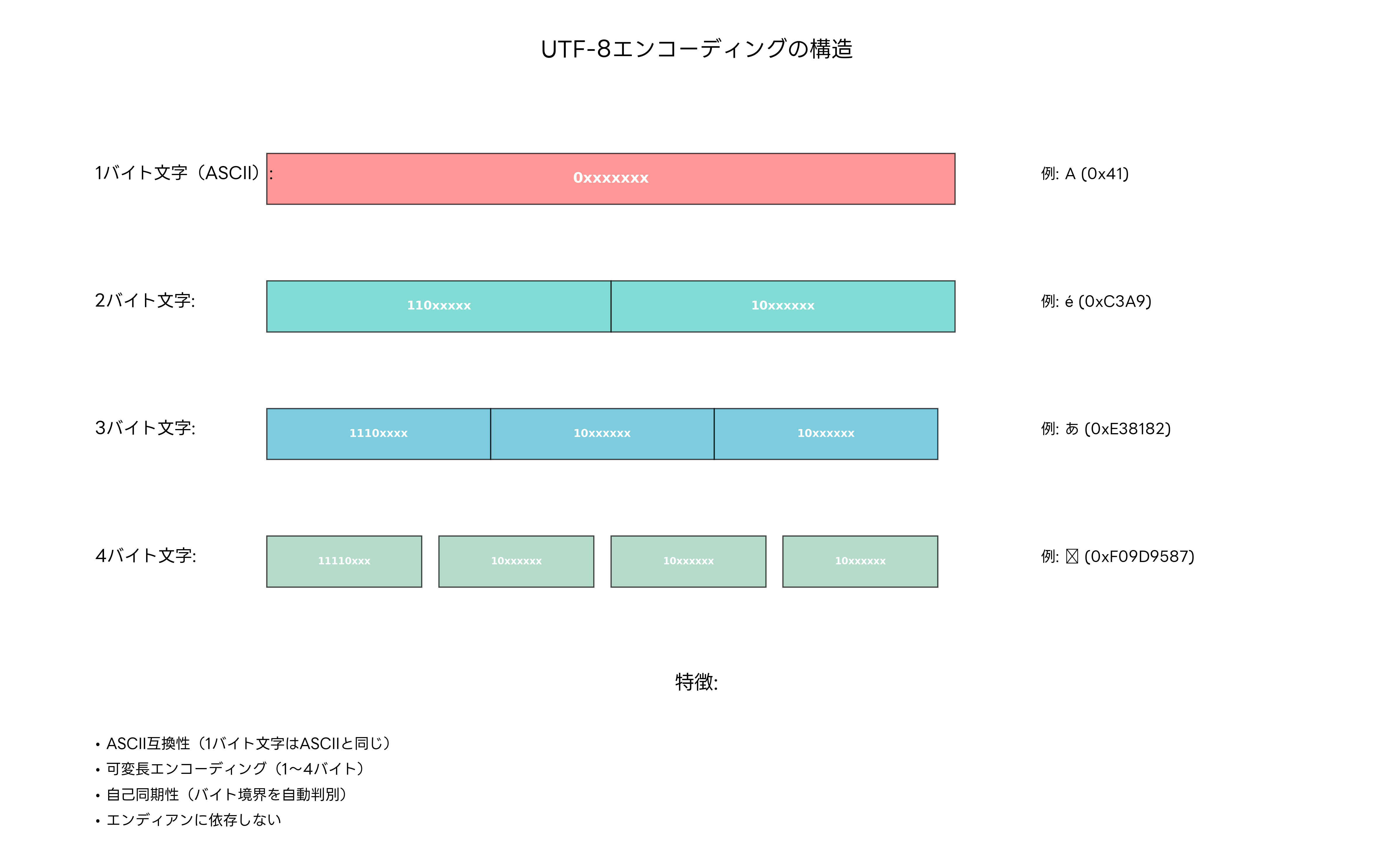
UTF-8の最大の特徴は、自己同期性にあります。バイト列の任意の位置から読み始めても、文字境界を自動的に判別できる設計になっています。これにより、データの一部が破損した場合でも、影響を最小限に抑えることができます。また、エンディアン(バイト順序)に依存しない設計のため、異なるアーキテクチャのシステム間でのデータ交換が容易です。
UTF-8エンコーディングでは、1バイト文字(ASCII文字)は0で始まり、複数バイト文字の先頭バイトは連続する1の数で文字の長さを示します。例えば、110xxxxxで始まる場合は2バイト文字、1110xxxxで始まる場合は3バイト文字を表します。続くバイト(継続バイト)は必ず10xxxxxxの形式で始まり、これにより文字境界の判別が可能になります。
現代のWeb開発において、UTF-8は事実上の標準となっています。HTML5仕様では、UTF-8がデフォルトの文字エンコーディングとして推奨され、主要なプログラミング言語やデータベースシステムもUTF-8を標準サポートしています。UTF-8対応の開発ツールを使用することで、国際化対応のアプリケーション開発が効率的に行えます。
エンコーディング変換の処理プロセス
文字エンコーディングの変換プロセスは、複数の段階を経て実行されます。まず、入力された文字列を解析し、各文字をUnicodeコードポイント(文字に割り当てられた一意の数値)に変換します。次に、指定されたエンコーディング方式に従って、Unicodeコードポイントをバイト列に変換します。この過程で、文字の正確性と完全性を保つため、様々な検証処理が行われます。
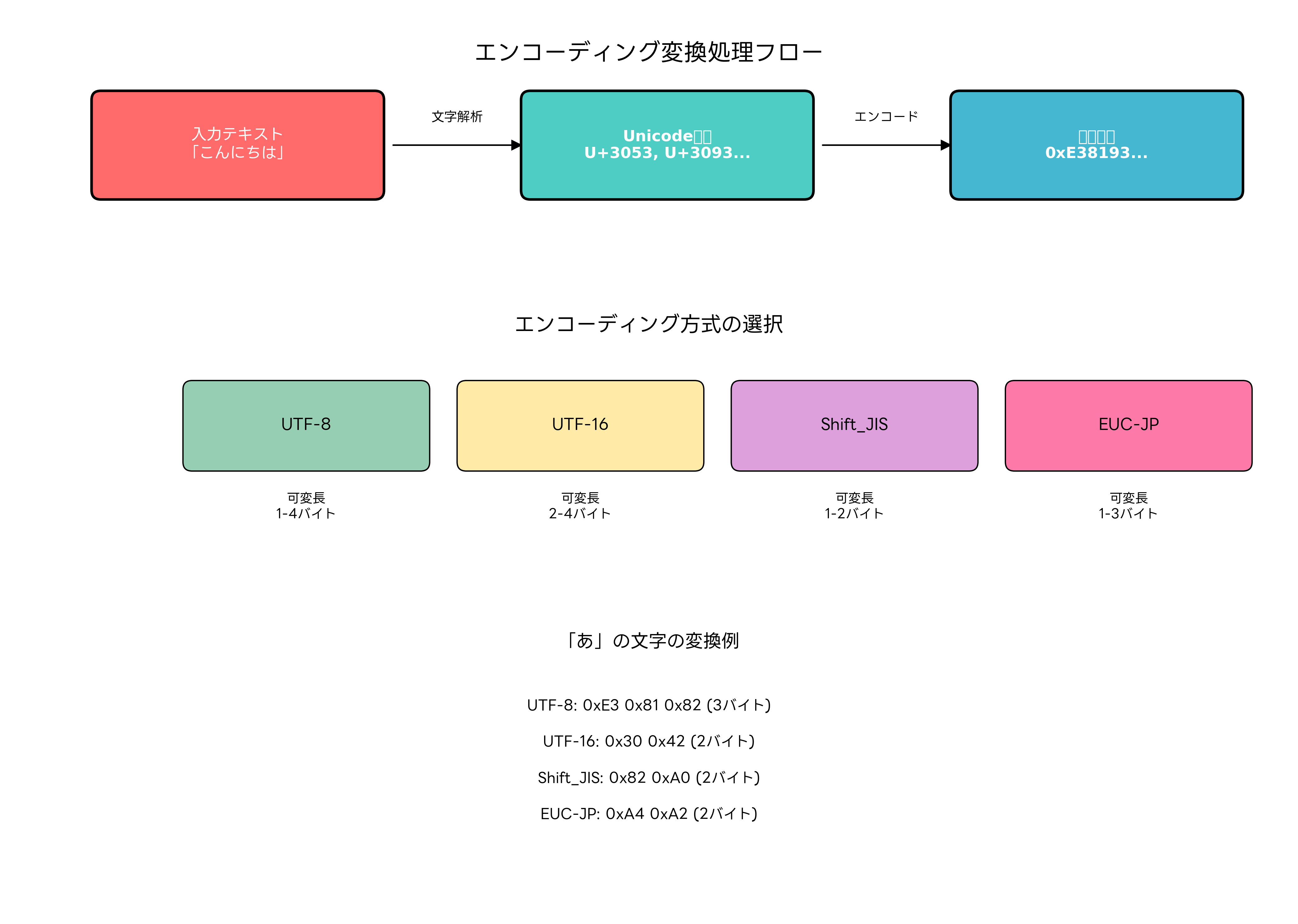
エンコーディング変換の実装では、文字境界の判定、無効なバイト列の処理、サロゲートペアの扱い、BOM(Byte Order Mark)の処理など、多くの技術的課題があります。特に、異なるエンコーディング間での変換では、一部の文字が表現できない場合があるため、適切なエラーハンドリングやフォールバック機能の実装が重要です。
現代の開発環境では、文字エンコーディング変換ライブラリや統合開発環境のエンコーディングツールを活用することで、複雑な変換処理を効率的に実装できます。これらのツールは、エンコーディングの自動検出、一括変換、品質検証などの機能を提供し、開発生産性の向上に寄与します。
プログラミング言語レベルでは、Python、Java、C#、JavaScriptなどの主要言語が標準ライブラリでUnicodeとUTF-8を完全サポートしています。これらの言語では、文字列リテラルが内部的にUnicodeで表現され、I/O操作時に適切なエンコーディング変換が自動的に行われます。
エンコーディング関連の問題と対策
文字エンコーディングに関する問題は、システム開発において頻繁に発生する課題の一つです。最も一般的な問題である文字化けは、エンコーディングの不一致や不適切な変換処理によって発生します。例えば、UTF-8でエンコードされたデータをShift_JISとして解釈した場合、正しい文字が表示されない現象が起こります。
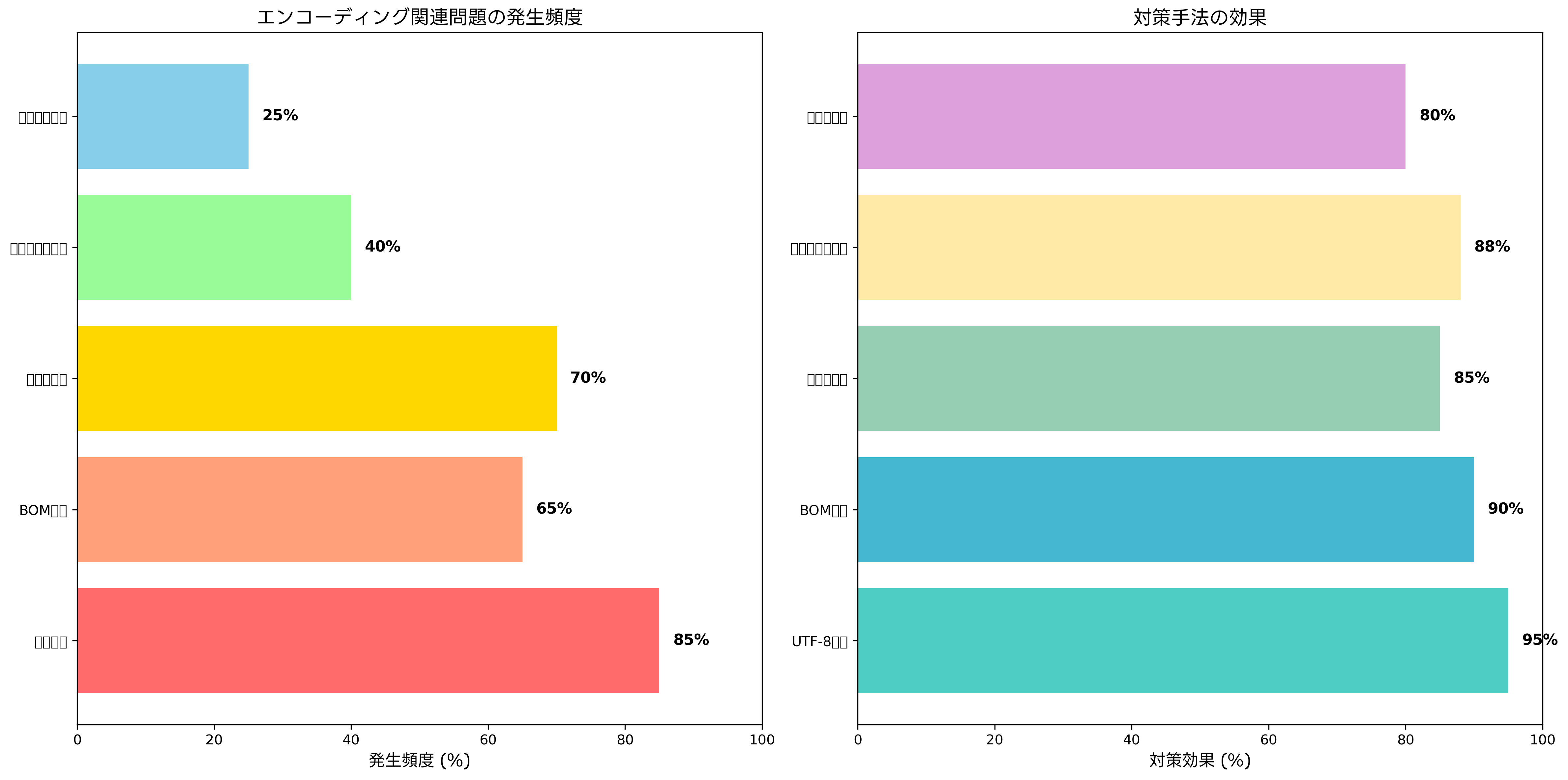
BOM(Byte Order Mark)問題も重要な課題です。BOMは、テキストファイルの先頭に付加される特殊なバイト列で、エンコーディング方式やバイト順序を示すために使用されます。しかし、BOMの存在により、プログラムの構文解析エラーやデータ処理エラーが発生する場合があります。特に、UTF-8のBOMは必須ではないため、BOM検出・除去ツールを使用した適切な処理が必要です。
改行コードの違いも、エンコーディング関連の問題として挙げられます。Windows(CRLF)、Unix/Linux(LF)、古いMac(CR)では異なる改行コードが使用されており、異なるプラットフォーム間でのファイル交換時に問題が発生します。統合的なテキスト処理ツールを使用することで、改行コードの正規化と統一が効率的に行えます。
サロゲートペア問題は、UTF-16エンコーディングに固有の課題です。Unicode文字の一部(基本多言語面を超える文字)は、UTF-16では2つの16ビット値(サロゲートペア)で表現されます。この仕組みを適切に処理しないと、文字の分割や不正な文字列操作が発生する可能性があります。
対策としては、システム全体でのエンコーディング標準化、適切な開発ツールの選択、包括的なテスト実施、エラーハンドリングの充実などが重要です。特に、多言語対応テストツールを使用したテストにより、様々な言語環境での動作確認を行うことが推奨されます。
Web開発におけるエンコーディング実践
現代のWeb開発では、UTF-8が標準エンコーディングとして確立されています。HTML5仕様では、文書のエンコーディングを明示的に指定することが推奨されており、meta要素のcharset属性でUTF-8を指定するのが一般的です。また、HTTP ヘッダーでもContent-Typeにcharset=UTF-8を指定することで、ブラウザとサーバー間での文字エンコーディングの統一が図られます。
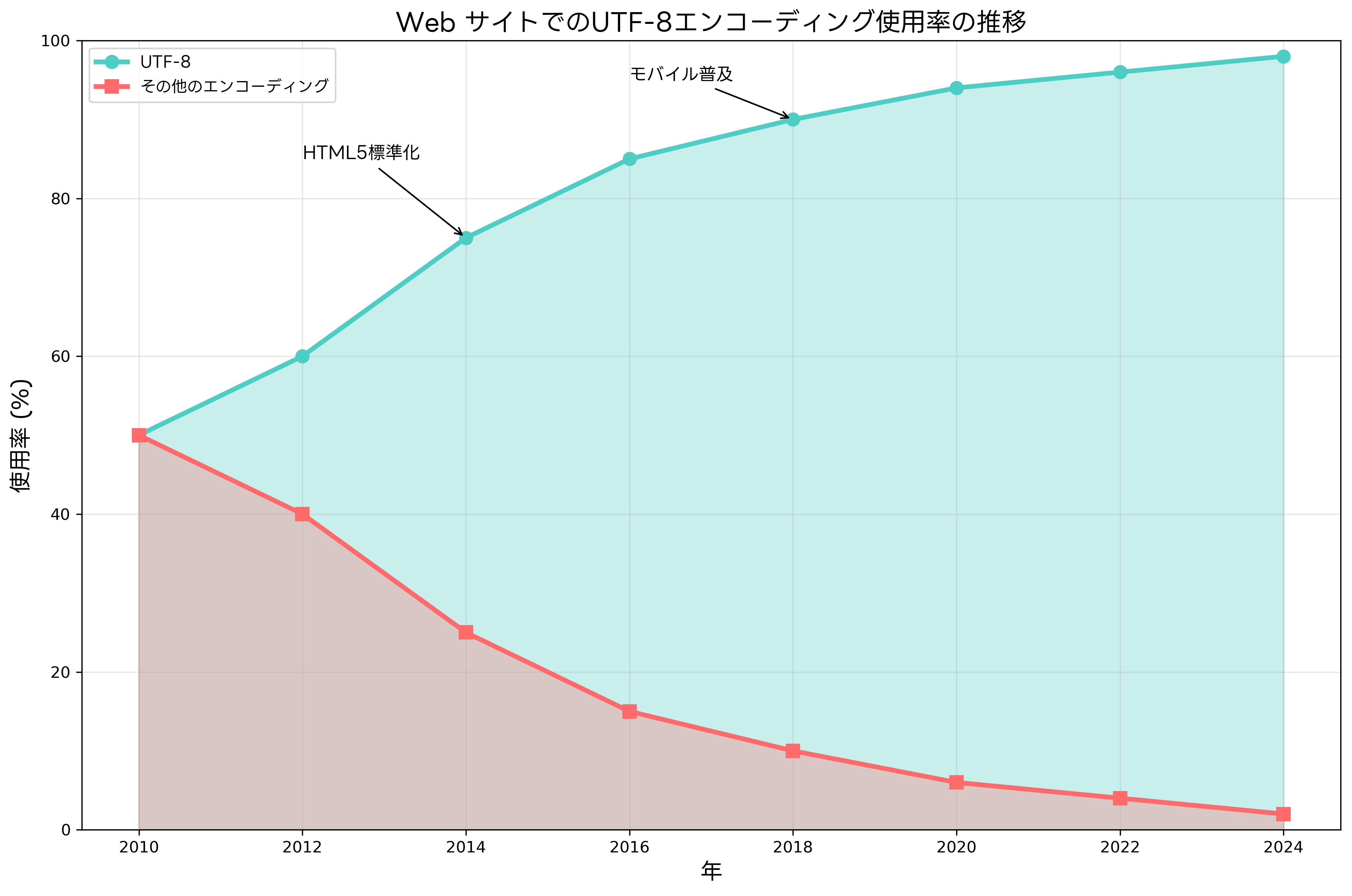
Webアプリケーションのアーキテクチャにおいて、エンコーディングの一貫性は極めて重要です。フロントエンド、バックエンド、データベース、外部API連携のすべての層でUTF-8を統一使用することで、文字化けやデータ破損のリスクを大幅に軽減できます。Web開発統合環境やクロスプラットフォーム開発ツールを活用することで、一貫したエンコーディング管理が実現できます。
データベース設計では、文字セット(character set)と照合順序(collation)の適切な設定が重要です。MySQLやPostgreSQLなどの主要なデータベースシステムでは、UTF-8(MySQL 8.0以降はutf8mb4)をデフォルトの文字セットとして設定することが推奨されます。データベース管理ツールを使用することで、文字セットの一括設定や移行作業を効率的に実行できます。
フォーム入力の処理では、ユーザーからの多様な入力データを適切に処理する必要があります。特に、絵文字や特殊文字の入力に対応するため、4バイトUTF-8(utf8mb4)のサポートが重要です。また、入力値の検証とサニタイゼーション処理において、文字エンコーディングを考慮したセキュリティ対策が必要です。
プログラミング言語でのエンコーディング処理
各プログラミング言語は、文字エンコーディングに対して独自のアプローチを採用しています。Pythonでは、Python 3系から文字列がデフォルトでUnicodeとして扱われ、バイト列との明確な区別が行われています。文字列とバイト列の変換には、encode()とdecode()メソッドを使用し、エンコーディングを明示的に指定します。
Javaでは、文字列が内部的にUTF-16で表現され、InputStreamReaderやOutputStreamWriterクラスでエンコーディング変換を行います。文字列処理では、CharsetクラスやStandardCharsetsクラスを使用して、標準的なエンコーディングへの変換を効率的に実行できます。Java開発環境構築ガイドでは、国際化対応の詳細な実装方法が解説されています。
JavaScriptでは、文字列が内部的にUTF-16で表現され、TextEncoder/TextDecoderAPIを使用してUTF-8との変換を行います。Node.jsではBufferクラスにより、バイナリデータと文字列の変換処理を効率的に実行できます。
C#では、.NET FrameworkのEncodingクラスファミリーにより、多様なエンコーディング間の変換をサポートしています。UTF8Encoding、UnicodeEncoding、ASCIIEncodingなどの専用クラスを使用することで、高性能な文字処理が実現できます。.NET開発リファレンスでは、エンコーディング処理のベストプラクティスが詳しく説明されています。
データベースシステムでのエンコーディング管理
データベースシステムにおける文字エンコーディングの管理は、システム全体の国際化対応の基盤となります。現代の主要なデータベース管理システムでは、UTF-8を標準文字セットとしてサポートし、多言語データの効率的な格納と処理を実現しています。
MySQLでは、文字セット(character set)と照合順序(collation)の概念により、文字の格納方式と比較・ソート規則を制御します。MySQL 8.0以降では、utf8mb4が推奨される文字セットとなり、4バイトUTF-8文字(絵文字など)の complete サポートが提供されています。MySQL管理者ガイドでは、文字セット設定の詳細な手順が説明されています。
PostgreSQLでは、データベースレベルでの文字エンコーディング設定により、統一的な文字処理が行われます。UTF-8(PostgreSQLではUTF8と表記)を使用することで、世界中の文字を効率的に格納でき、テキスト検索や文字列操作の性能も向上します。特に、全文検索機能やパターンマッチング機能において、適切なエンコーディング設定が重要な役割を果たします。
Oracle Databaseでは、国家言語サポート(NLS: National Language Support)により、多言語環境での文字処理を実現しています。AL32UTF8文字セットを使用することで、完全なUnicodeサポートが提供され、グローバルなアプリケーション開発が可能になります。
SQL Serverでは、照合順序(collation)の設定により、文字の格納と比較処理を制御します。UTF-8サポートは比較的新しい機能ですが、SQL Server 2019以降では本格的なUTF-8サポートが提供され、ストレージ効率と国際化対応の両立が実現されています。SQL Server国際化対応ガイドでは、実践的な設定方法が解説されています。
応用情報技術者試験での出題傾向
応用情報技術者試験において、文字エンコーディングは午前問題・午後問題ともに重要な出題分野です。特に、システム開発技術、データベース技術、ネットワーク技術の各分野において、エンコーディングに関する知識が問われます。
午前問題では、UTF-8の構造、Unicodeコードポイント、文字セットと文字エンコーディングの違い、BOMの役割、各エンコーディング方式の特徴などが頻出トピックです。例えば、「UTF-8で日本語文字『あ』をエンコードした場合のバイト数は?」といった具体的な計算問題や、「ASCII互換性を持つエンコーディング方式はどれか?」といった特徴に関する問題が出題されます。
午後問題では、システム設計や国際化対応の文脈で、エンコーディングの選択理由や変換処理の実装方法が問われます。Webアプリケーション開発、データベース設計、ファイル処理システムなどの実践的な場面で、適切なエンコーディング戦略を立案する能力が評価されます。
試験対策としては、応用情報技術者試験対策書での理論学習に加えて、実際のプログラミング環境でエンコーディング変換を体験することが効果的です。プログラミング学習環境を構築し、様々なエンコーディング間での変換処理を実装することで、理論と実践の両面からの理解が深まります。
特に重要なのは、文字化け現象の原因と対策、BOM処理、サロゲートペア、エンディアン問題など、実際の開発現場で頻繁に遭遇する課題の理解です。文字エンコーディング専門書を参考に、深い技術的理解を構築することが推奨されます。
国際化とローカライゼーション
文字エンコーディングは、国際化(i18n: Internationalization)とローカライゼーション(l10n: Localization)の基盤技術として位置づけられます。国際化とは、ソフトウェアやシステムを複数の言語や地域に対応できるよう設計することであり、ローカライゼーションとは、特定の言語や地域向けにカスタマイズすることです。
グローバルなWebサービスやアプリケーションの開発では、多言語サポートが必須要件となっています。この場合、UTF-8を基盤とした統一的な文字処理アーキテクチャの構築が重要です。フロントエンド、バックエンド、データベース、CDN、キャッシュシステムのすべての層でUTF-8を標準化することで、言語間でのデータ一貫性が保たれます。
国際化対応フレームワークや多言語管理システムを活用することで、翻訳管理、言語切り替え、地域固有の文字処理などを効率的に実装できます。これらのツールは、エンコーディング処理を抽象化し、開発者が言語固有の技術的詳細を意識せずに国際化対応を進められるようサポートします。
地域固有の文字処理要件も重要な考慮事項です。例えば、アラビア語やヘブライ語の右から左への記述(RTL: Right-to-Left)、中国語の繁体字と簡体字の使い分け、インド系言語の複合文字処理などがあります。これらの要件に対応するため、多言語テキスト処理ライブラリを活用した specialized な実装が必要になります。
セキュリティ観点でのエンコーディング考慮事項
文字エンコーディングは、情報セキュリティの観点からも重要な考慮事項です。不適切なエンコーディング処理は、セキュリティ脆弱性の原因となる可能性があります。特に、Webアプリケーションにおけるクロスサイトスクリプティング(XSS)攻撃、SQLインジェクション攻撃、ディレクトリトラバーサル攻撃などで、エンコーディングの特性が悪用される場合があります。
入力値検証とサニタイゼーション処理では、文字エンコーディングを考慮した適切な実装が必要です。例えば、UTF-8の可変長特性を悪用した攻撃では、無効なバイト列や overlong encoding を利用してセキュリティフィルターを回避しようとします。Webアプリケーションセキュリティツールを使用して、エンコーディング関連の脆弱性を検出・防止することが重要です。
文字正規化(Unicode Normalization)も、セキュリティ上の重要な処理です。Unicodeでは、同じ文字を複数の方法で表現できる場合があり(合成文字と分解文字など)、これを悪用したセキュリティ攻撃が存在します。NFC(Canonical Decomposition followed by Canonical Composition)やNFKC(Compatibility Decomposition followed by Canonical Composition)などの正規化処理により、一意な文字表現を確保できます。
パスワードやトークンなどのセンシティブな情報を扱う場合、エンコーディング処理がセキュリティに与える影響を慎重に評価する必要があります。セキュリティ監査ツールを使用して、エンコーディング関連のセキュリティリスクを定期的に評価することが推奨されます。
今後の技術トレンドと展望
文字エンコーディング技術は、新しい文字の追加、絵文字の普及、多言語AI処理などの要求により、継続的に発展しています。Unicode標準は年次更新により新しい文字を追加し続けており、最新のUnicode 15.1では約15万文字が収録されています。
絵文字(emoji)は、現代のデジタルコミュニケーションにおいて重要な役割を果たしており、その技術的実装にも注目が集まっています。絵文字は基本的に4バイトUTF-8でエンコードされ、合成絵文字(複数の絵文字を組み合わせて新しい表現を作る)などの高度な機能も実装されています。絵文字処理ライブラリを活用することで、現代的なユーザーインターフェースを効率的に実装できます。
人工知能と機械学習の分野では、多言語自然言語処理において文字エンコーディングが重要な役割を果たしています。特に、大規模言語モデル(LLM)のトレーニングや推論処理では、効率的な文字表現とエンコーディング処理が性能に直接影響します。AI開発プラットフォームでは、多言語対応のテキスト処理機能が標準的に提供されています。
エッジコンピューティングやIoTデバイスでは、リソース制約のある環境での効率的な文字処理が求められています。軽量なエンコーディング処理ライブラリや、特定用途向けの最適化されたエンコーディング方式の開発が進んでいます。
量子コンピューティングの発展により、将来的には量子耐性を持つ文字エンコーディングや暗号化技術の統合も検討されています。次世代コンピューティング技術書では、これらの最新動向が詳しく解説されています。
まとめ
文字エンコーディングは、現代のデジタル社会における基盤技術として、システム開発のあらゆる側面に影響を与える重要な概念です。UTF-8の標準化により、グローバルな文字処理の基盤が確立されましたが、実装においては依然として多くの技術的課題と考慮事項が存在します。
応用情報技術者試験での頻出分野であると同時に、実際の開発現場で直面する実践的な問題でもあります。理論的な理解と実装経験の両方を通じて、適切なエンコーディング戦略を立案し、国際化対応やセキュリティ要件を満たすシステムを構築する能力が求められます。
技術の進歩とともに、新しい文字体系や処理要件が継続的に登場しているため、最新の動向を把握し、適応していく姿勢が重要です。技術動向調査レポートや技術カンファレンス参加を通じて、継続的な学習と知識更新を行うことで、変化する技術環境に対応できる専門性を維持できます。