現代の情報システムにおいて、一意識別子は欠かせない基盤技術の一つです。データベースの主キーから、Webサービスのセッション管理、分散システムでのオブジェクト識別まで、あらゆる場面で一意識別子が活用されています。応用情報技術者試験においても、データベース設計やシステム設計の分野で頻出する重要なトピックであり、システム開発者にとって必須の知識です。
一意識別子とは、システム内またはシステム間において、特定のエンティティ(データ、オブジェクト、リソースなど)を他と区別して特定するための値です。この識別子は、その名前が示すとおり「一意」である必要があり、同じ識別子が複数の異なるエンティティに割り当てられることは許されません。
一意識別子の基本概念と重要性
一意識別子の概念は情報システムの根幹に関わるものです。データの整合性、システムの信頼性、そして効率的なデータ処理を実現するために、適切な一意識別子の設計と実装が不可欠です。特に、大規模なシステムや分散システムでは、一意識別子の設計が全体のアーキテクチャに大きな影響を与えます。
一意識別子が満たすべき基本的な要件には、一意性、不変性、可読性、効率性があります。一意性は最も重要な要件で、システム内で同じ識別子が重複してはなりません。不変性は、一度割り当てられた識別子が変更されないことを意味し、データの整合性を保つために重要です。可読性は人間が理解しやすい形式であることを指し、デバッグや運用の効率を向上させます。効率性は、処理速度やストレージ使用量の観点から重要な要素です。
システム設計において一意識別子を検討する際には、データベース設計の専門書を参考にして、適切な設計原則を学ぶことが重要です。また、実装時にはデータベース管理システムの特性を理解し、最適な識別子戦略を選択する必要があります。
UUID(Universally Unique Identifier)の詳細分析
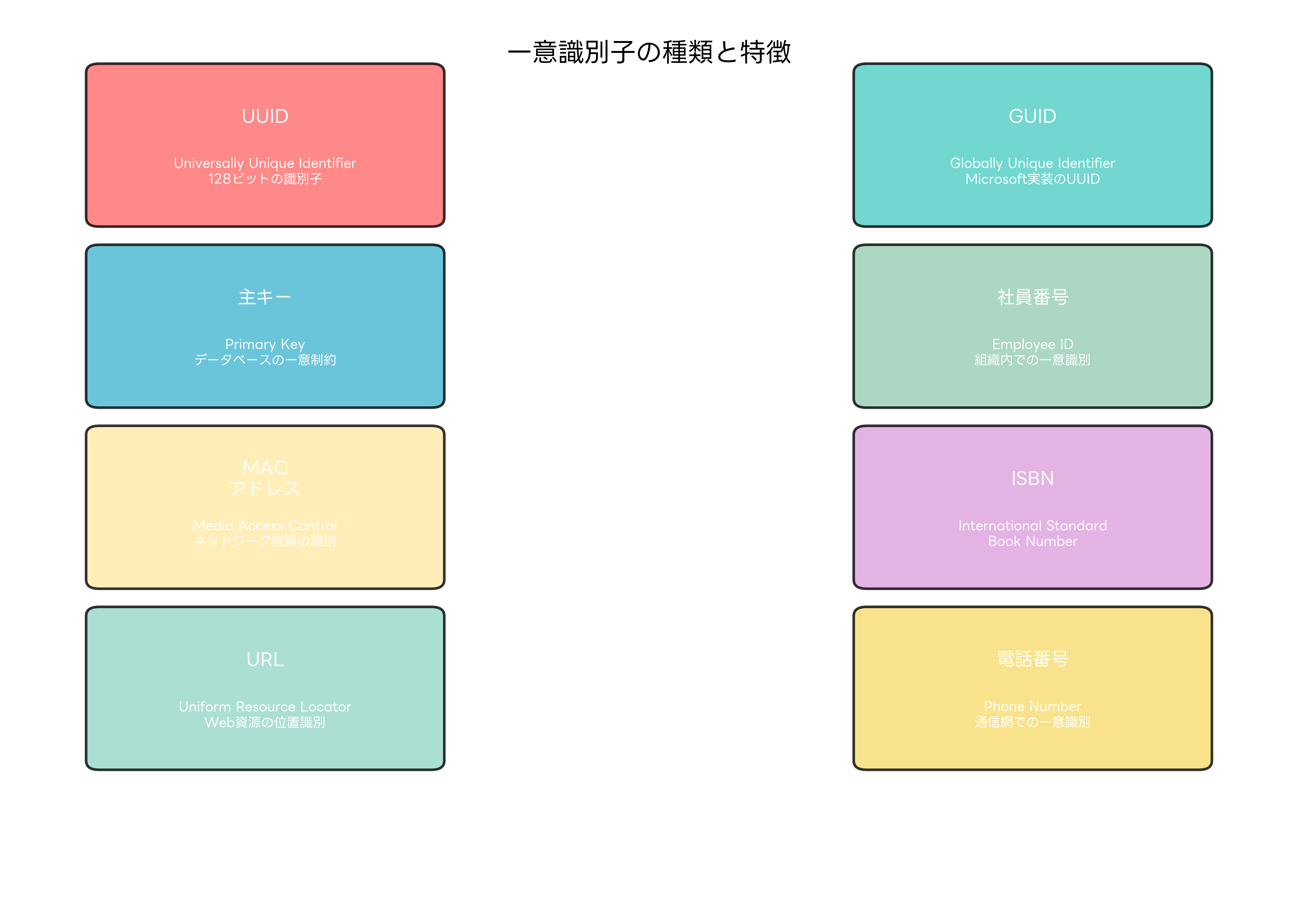
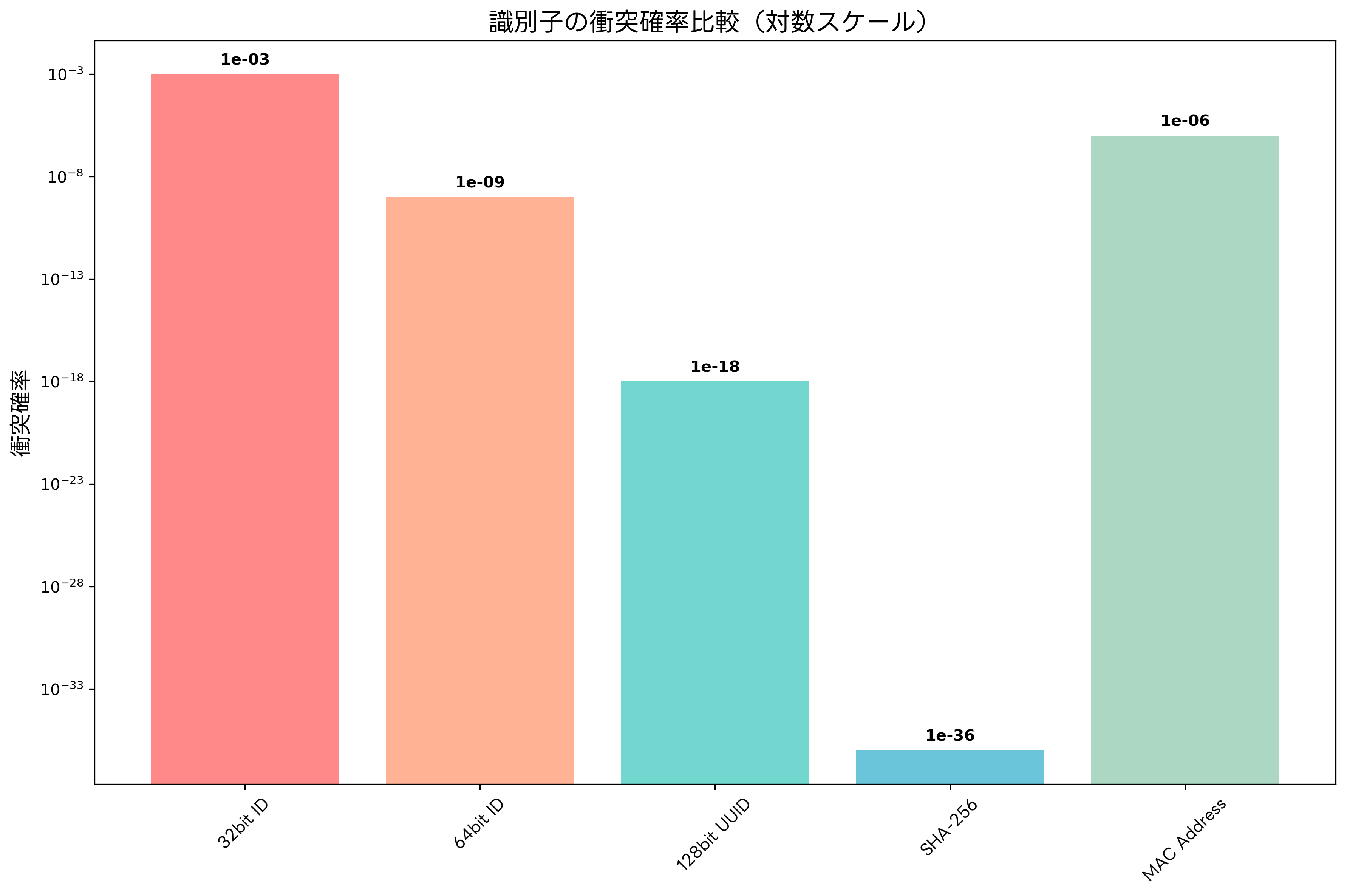
UUIDは、分散システムにおいて最も広く使用される一意識別子の形式の一つです。128ビットの長さを持ち、理論上は地球上のすべてのコンピューターが同時に生成しても衝突する可能性が極めて低い設計になっています。UUIDの形式は「xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx」で表現され、各xは16進数の数字、MはUUIDのバージョン、Nはバリアント情報を示します。
UUIDには5つの主要なバージョンが存在します。Version 1は、MAC アドレスと現在時刻を基に生成され、一意性は保証されますが、MAC アドレスからマシンが特定される可能性があります。Version 2は、DCE Security用に設計されましたが、実際にはあまり使用されません。Version 3は、名前空間識別子と名前をMD5ハッシュして生成し、同じ入力からは常に同じUUIDが生成されます。
Version 4は最も一般的に使用され、ランダムまたは疑似ランダムな値から生成されます。セキュリティが高く、実装が簡単であるため、多くのシステムで採用されています。Version 5は、Version 3と同様の仕組みですが、より安全なSHA-1ハッシュを使用します。
現代のアプリケーション開発では、UUID生成ライブラリを使用することが一般的です。多くのプログラミング言語で標準ライブラリとして提供されており、適切な実装を利用することで、確実にユニークなIDを生成できます。
データベースにおける主キー設計戦略
データベース設計において、主キーの選択は システム全体の性能と保守性に大きな影響を与える重要な決定です。主キーには自然キー、代理キー、複合キーなどの設計パターンがあり、それぞれに特徴があります。
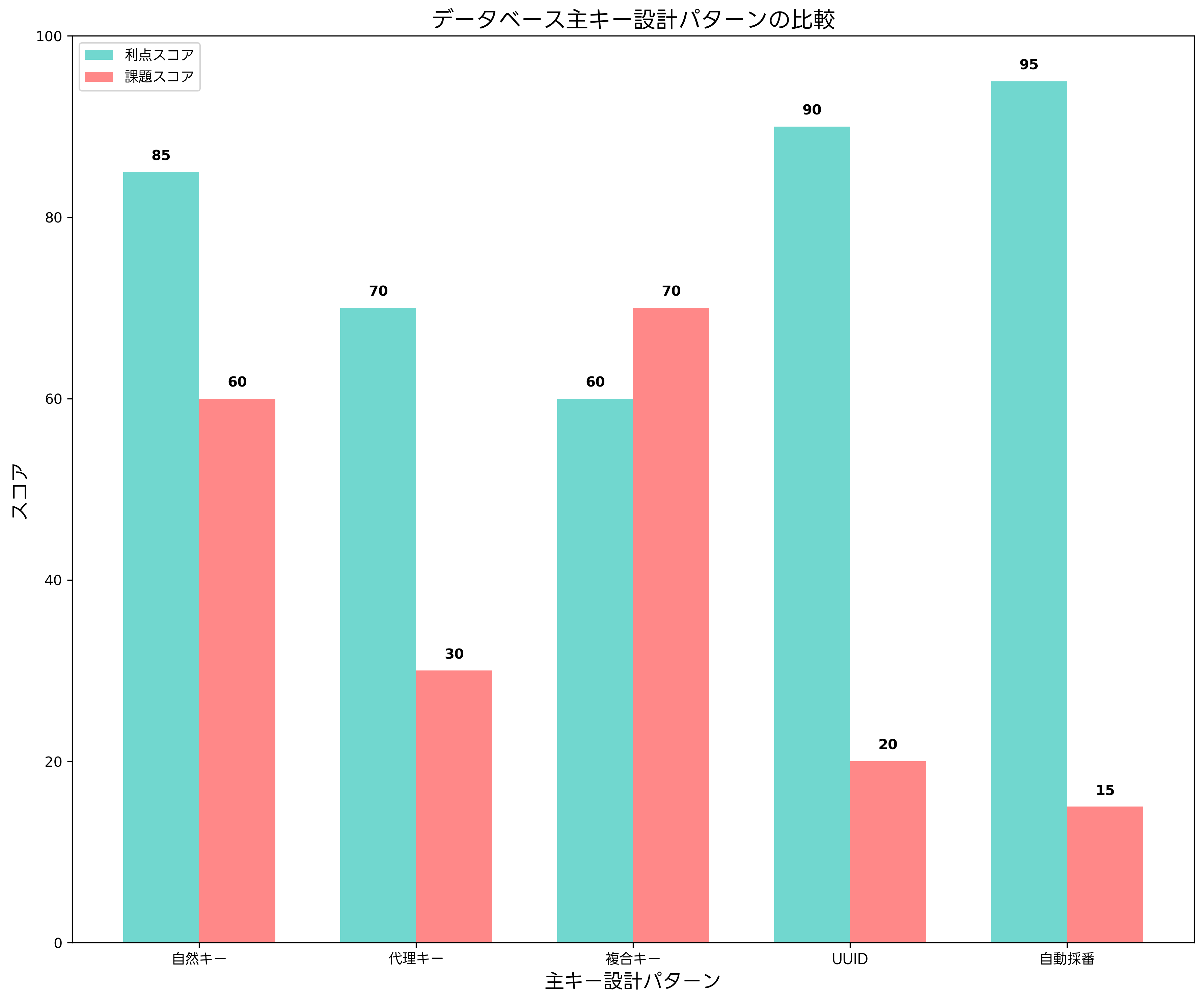
自然キーは、ビジネス上の意味を持つ値を主キーとして使用する方法です。例えば、商品マスターテーブルで商品コードを主キーとする場合などです。自然キーの利点は、ビジネス上の意味が明確で、結合操作時に直感的に理解しやすいことです。しかし、ビジネス要件の変更により値が変更される可能性があり、外部キー制約のあるテーブルに影響を与える可能性があります。
代理キーは、システムが自動的に生成する意味のない値を主キーとして使用する方法です。多くの場合、自動採番機能やUUIDが使用されます。代理キーの利点は、ビジネス要件の変更に影響されず、性能面でも優れていることです。一方で、デバッグ時に直感的に理解しにくく、開発効率が低下する場合があります。
複合キーは、複数の列を組み合わせて主キーとする方法です。多対多の関係を表現する中間テーブルなどでよく使用されます。複合キーは、ビジネス上の制約を自然に表現できる利点がありますが、外部キーとして参照する際に複雑になりがちです。
現代のシステム開発では、高性能データベースサーバーを使用することで、大量のデータに対しても効率的な主キー処理が可能になります。また、データベース最適化ツールを活用することで、主キーのパフォーマンスを継続的に監視し、改善することができます。
分散システムにおける一意識別子の挑戦
分散システムでは、複数のノードが独立して動作しながら、全体として一貫したデータを維持する必要があります。この環境での一意識別子生成は、従来の単一システムとは異なる課題があります。最も大きな課題は、中央集権的な採番機構を持たずに、各ノードが独立して一意な識別子を生成する必要があることです。
分散システムでの一意識別子生成手法には、いくつかのアプローチがあります。UUID Version 4のようなランダム生成方式は、統計的に衝突確率が極めて低く、各ノードが独立して生成できる利点があります。Twitter社が開発したSnowflakeアルゴリズムは、タイムスタンプ、データセンターID、ワーカーID、シーケンス番号を組み合わせて64ビットの識別子を生成し、時系列順序も保持できる特徴があります。
分散システムでの一意識別子管理には、分散システム監視ツールを使用して、各ノードでの識別子生成状況を監視し、異常を早期に検出することが重要です。また、分散データベースシステムを導入することで、複数のデータセンター間でも一貫した識別子管理が可能になります。
Vector Clocksやマシーハッシュなどの分散システム特有の技術を活用することで、より効率的な識別子管理が実現できます。これらの技術の実装には、分散システム開発フレームワークを活用することで、複雑な実装を簡素化できます。
セキュリティとプライバシーの考慮事項
一意識別子の設計において、セキュリティとプライバシーの観点は重要な考慮事項です。特に、Webアプリケーションやモバイルアプリケーションなど、外部からアクセス可能なシステムでは、識別子自体が攻撃対象になる可能性があります。
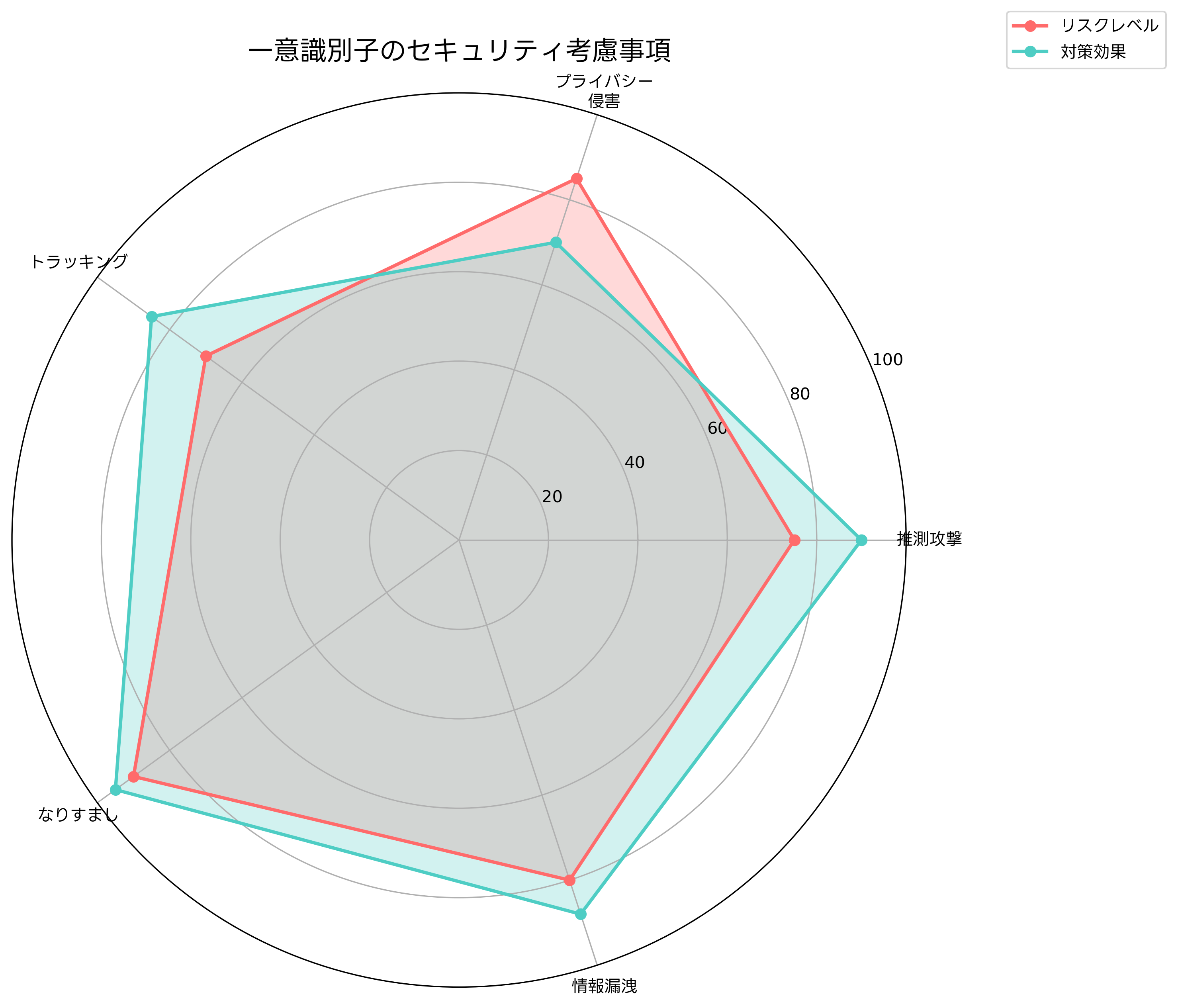
順次採番による識別子は、推測攻撃の対象になりやすい問題があります。例えば、ユーザーIDが1, 2, 3…のように順次採番されている場合、攻撃者は他のユーザーのIDを推測して不正アクセスを試みる可能性があります。この問題を防ぐため、外部に公開される識別子にはランダムな値やハッシュ値を使用することが推奨されます。
プライバシーの観点では、識別子からユーザーの行動パターンや個人情報が推測される可能性があります。UUID Version 1のようにMAC アドレスを含む識別子は、特定のデバイスを追跡する手段として悪用される可能性があります。GDPR(一般データ保護規則)などの個人情報保護法制においても、個人を特定可能な識別子の取り扱いには注意が必要です。
セキュリティ強化のためには、暗号化ソフトウェアを使用して、識別子自体を暗号化して保存することも有効です。また、セキュリティ監査ツールを定期的に実行し、識別子の使用状況やアクセスパターンを監視することで、不正な使用を早期に発見できます。
一意識別子のライフサイクル管理
一意識別子の管理は、単に生成するだけでなく、そのライフサイクル全体を通じて適切に管理する必要があります。識別子の生成、割り当て、使用、更新、廃止の各段階で、異なる管理要件があります。
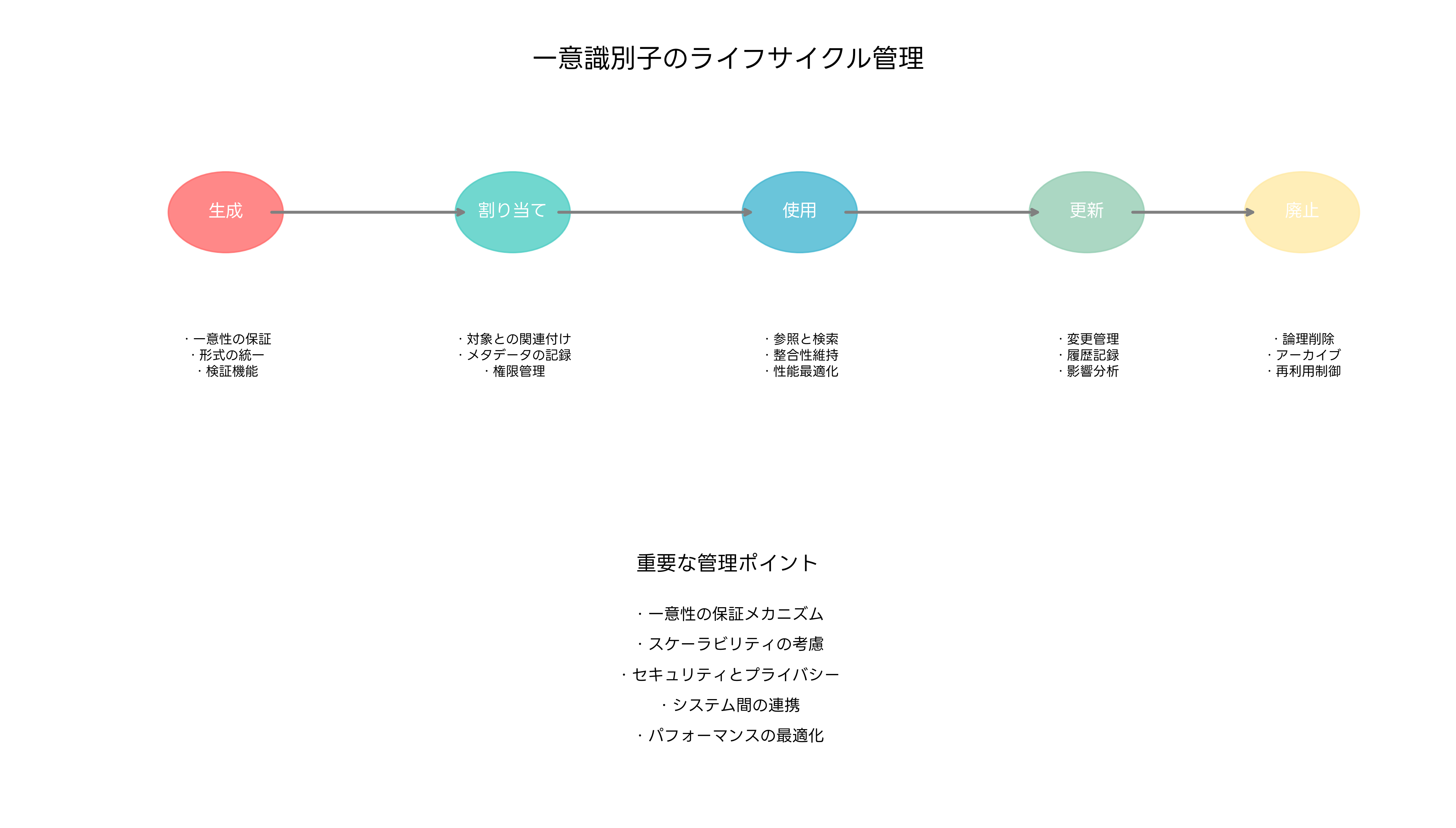
生成段階では、一意性の保証が最も重要です。システム全体で重複のない識別子を生成するため、適切なアルゴリズムの選択と実装が必要です。また、生成される識別子の形式や長さを統一し、システム全体での一貫性を保つことも重要です。この段階では、ID生成管理システムを導入することで、効率的で確実な識別子生成が可能になります。
割り当て段階では、生成された識別子を適切なエンティティに関連付けます。この時点で、識別子とエンティティの関係を正確に記録し、必要に応じてメタデータも併せて管理します。権限管理の観点から、どのユーザーまたはシステムが識別子を割り当てたかの記録も重要です。
使用段階では、識別子を使用したデータの参照、検索、更新などの操作が行われます。この段階では、パフォーマンスの最適化が重要で、適切なインデックスの設定やキャッシュ戦略の実装が必要です。データベース性能監視ツールを使用して、識別子を使用したクエリの性能を継続的に監視することが推奨されます。
更新段階では、識別子自体は通常変更されませんが、識別子に関連するメタデータの更新が行われます。変更履歴の記録と影響範囲の分析が重要で、変更管理システムを活用することで、適切な変更管理が実現できます。
廃止段階では、不要になった識別子の処理を行います。物理的な削除ではなく論理削除を行い、履歴データとして保持することが一般的です。また、廃止された識別子の再利用についても慎重な検討が必要で、データの整合性と歴史的なトレーサビリティを保つため、通常は再利用を避けることが推奨されます。
標準化された識別子システム
現実世界では、業界や用途に応じて標準化された識別子システムが数多く存在します。これらの標準化された識別子は、異なる組織やシステム間でのデータ交換を可能にし、相互運用性を向上させる重要な役割を果たしています。
ISBN(International Standard Book Number)は、書籍を世界的に一意に識別するための標準システムです。13桁の数字で構成され、国別コード、出版社コード、書籍コード、チェックディジットから構成されています。この標準により、世界中の書店や図書館で書籍を効率的に管理できています。書籍管理システムの構築には、書籍管理ソフトウェアを活用することで、ISBN に対応した効率的な管理が可能です。
DOI(Digital Object Identifier)は、デジタルコンテンツの永続的な識別を目的とした標準システムです。学術論文、データセット、ソフトウェアなどのデジタルオブジェクトに付与され、URLが変更されてもコンテンツにアクセスできる仕組みを提供します。研究機関や学術出版社では、DOI管理システムを導入して、研究成果物を適切に管理しています。
ORCID(Open Researcher and Contributor ID)は、研究者を一意に識別するための標準システムです。研究者の名前変更、所属変更、共通の名前による混同などの問題を解決し、研究成果と研究者を正確に関連付けることができます。学術機関では、研究者管理システムにORCIDを統合することで、効率的な研究者管理が実現されています。
プログラミング言語別の実装手法
一意識別子の実装は、使用するプログラミング言語や開発環境によって異なるアプローチが取られます。各言語の特性を理解し、適切な実装手法を選択することが重要です。
Java では、java.util.UUID クラスが標準ライブラリとして提供され、簡単にUUIDを生成できます。randomUUID() メソッドはVersion 4のUUIDを生成し、nameUUIDFromBytes() メソッドはVersion 3のUUIDを生成します。エンタープライズアプリケーションでは、Java開発環境を整備し、適切なライブラリ管理を行うことが重要です。
Python では、uuid モジュールが標準ライブラリとして提供されています。uuid.uuid4() でランダムなUUIDを、uuid.uuid1() でMACアドレスベースのUUIDを生成できます。Python での大規模システム開発には、Python開発ツールを活用することで、効率的な開発が可能です。
JavaScript(Node.js)では、crypto モジュールやサードパーティライブラリを使用してUUIDを生成できます。フロントエンドとバックエンドで一貫した識別子管理を行うため、JavaScript開発フレームワークの選択が重要です。
C# では、System.Guid 構造体が提供され、Guid.NewGuid() メソッドで新しいGUIDを生成できます。.NET Frameworkの豊富な機能を活用するため、.NET開発環境の整備が推奨されます。
パフォーマンスと最適化戦略
一意識別子の設計は、システム全体のパフォーマンスに大きな影響を与えます。特に、大量のデータを扱う現代のシステムでは、識別子の選択がボトルネックになる可能性があります。
データベースにおける識別子のパフォーマンスは、主にインデックスの効率性とストレージの使用量に依存します。整数型の自動採番IDは、コンパクトで高速な処理が可能ですが、分散システムでは生成が困難です。一方、UUIDは分散生成が容易ですが、サイズが大きく、ランダムな値のため、Bツリーインデックスでの挿入性能が低下する可能性があります。
このような性能問題を解決するため、高性能データベースエンジンの採用や、SSDストレージシステムの導入により、I/O性能を向上させることが効果的です。
キャッシュ戦略も重要な最適化手法です。頻繁にアクセスされる識別子とその関連データをメモリ上にキャッシュすることで、データベースへのアクセス回数を削減できます。高性能キャッシュシステムを導入することで、大幅な性能向上が期待できます。
パーティショニング戦略により、大量のデータを複数のパーティションに分散することで、並列処理による性能向上が可能です。識別子の特性を考慮したパーティショニング設計により、効率的なデータアクセスが実現できます。
応用情報技術者試験での出題傾向と対策
応用情報技術者試験において、一意識別子に関する問題は主にデータベース設計、システム設計、セキュリティの分野で出題されます。特に、主キーの設計原則、正規化との関係、インデックス設計、分散システムでの課題などが重要なトピックです。
午前問題では、一意識別子の基本概念や設計原則に関する知識問題が出題されます。例えば、「主キーとして適切でない項目はどれか」といった選択問題や、「UUIDの特徴として正しいものはどれか」といった問題が典型的です。これらの問題に対応するため、応用情報技術者試験対策書で基礎知識を固めることが重要です。
午後問題では、実際のシステム設計において一意識別子をどのように活用するかが問われます。データベース設計の問題では、与えられた業務要件から適切な主キーを選択し、その理由を説明する問題が頻出します。また、システムの性能要件や可用性要件を満たすための識別子設計についても出題されます。
試験対策としては、理論的な知識だけでなく、実際のシステム開発での経験も重要です。データベース実習環境を構築し、様々な識別子設計を実際に試してみることで、理解が深まります。また、システム設計演習書を活用して、実践的な設計スキルを身につけることが推奨されます。
過去問題の分析では、一意識別子に関する問題の多くが、実際の業務システムでの適用を想定した実践的な内容になっています。単純な暗記ではなく、システム全体の文脈での理解が求められるため、過去問題集を繰り返し解き、解説を通じて背景知識を深めることが重要です。
新技術とのマッピングと今後の展望
現代の技術トレンドは、一意識別子の設計と実装に新たな要件と可能性をもたらしています。ブロックチェーン技術では、分散台帳上での一意識別子管理が重要な課題となっており、従来の中央集権的な管理手法とは異なるアプローチが必要です。
マイクロサービスアーキテクチャでは、サービス間での一意識別子の共有と管理が複雑な課題となります。各サービスが独立してデプロイされる環境では、識別子の生成と管理も分散化する必要があります。マイクロサービス開発プラットフォームを活用することで、この複雑さを効率的に管理できます。
IoT(物のインターネット)環境では、膨大な数のデバイスが一意の識別子を必要とします。デバイス間通信、データ収集、リモート管理など、様々な用途で識別子が使用されます。IoTデバイス管理システムでは、スケーラブルな識別子管理機能が不可欠です。
人工知能と機械学習の分野では、学習データや学習済みモデルの管理に一意識別子が活用されています。データの出典管理、モデルのバージョン管理、実験の再現性確保など、研究開発の効率化に貢献しています。[AI/ML管理プラットフォーム](https://www.amazon.co.jp/s?k=AI ML管理プラットフォーム&tag=amazon-product-items-22)では、これらの要件を満たす高度な識別子管理が求められます。
まとめ
一意識別子は、現代の情報システムの基盤を支える重要な技術要素です。単純な概念に見えますが、実際のシステムでの実装では、性能、セキュリティ、拡張性、運用性など、多くの要素を総合的に考慮する必要があります。応用情報技術者試験においても、単なる知識の暗記ではなく、システム設計の文脈での理解が求められます。
技術の進歩とともに、一意識別子の要件も変化し続けています。クラウドコンピューティング、分散システム、IoT、AIなどの新しい技術領域では、従来の手法では対応できない課題が生まれています。これらの変化に対応するため、継続的な学習と実践的な経験の蓄積が重要です。
システム開発者として成功するためには、一意識別子の基本原理を深く理解し、適切な設計判断ができる能力を身につけることが必要です。理論と実践の両面から一意識別子に取り組み、変化する技術環境に適応できる柔軟性を持つことで、より良いシステムの構築に貢献できるでしょう。