
現代のITシステムにおいて、異常監視は業務継続性とサービス品質を確保するための不可欠な技術です。企業のデジタル化が進む中で、システム障害による事業への影響は年々深刻化しており、適切な異常監視システムの構築が企業の競争力を左右する重要な要因となっています。応用情報技術者試験においても、システム運用管理の分野で頻出する重要なトピックであり、実務での活用価値も非常に高い技術領域です。

異常監視とは、ITシステムの各種メトリクス(指標)を継続的に測定・分析し、正常な動作範囲を逸脱した際に迅速に検知・通知する仕組みです。この技術により、システム障害の予防的検知、迅速な復旧対応、サービス品質の維持が可能となり、企業の事業継続性を支える基盤技術として機能します。
異常監視の基本概念と重要性
異常監視システムは、複数の階層にわたってシステムの状態を監視します。最下層のハードウェア層から最上層の業務アプリケーション層まで、各層において特有の監視項目が存在し、それぞれが相互に関連しながらシステム全体の健全性を表現します。
ハードウェア層では、CPU使用率、メモリ使用率、ディスク容量、ネットワーク帯域使用率などの基本的なシステムリソースを監視します。これらの指標は、システムの物理的な制約を示すものであり、しきい値を超過した場合には即座にパフォーマンス劣化やシステム停止につながる可能性があります。現代の企業では、高性能サーバー監視ツールを導入して、これらの基本的なメトリクスを24時間365日監視しています。
ミドルウェア層では、データベース管理システム、Webサーバー、アプリケーションサーバーなどの各種ミドルウェアの動作状況を監視します。データベースの接続数、クエリ応答時間、ロック待機時間、Webサーバーのアクセス数、エラーレート、セッション数などが主要な監視項目となります。これらの監視には、データベース専用監視ソリューションやWebサーバー監視システムの導入が効果的です。
アプリケーション層では、業務アプリケーション固有の指標を監視します。ユーザーの操作レスポンス時間、トランザクション成功率、業務処理の完了数、エラー発生頻度などが重要な監視項目です。また、業務KPI(重要業績評価指標)に直結する指標の監視も行い、ITシステムの稼働状況が事業成果に与える影響を可視化します。
異常検知の手法と技術
異常検知には複数のアプローチが存在し、それぞれに特徴と適用場面があります。最も基本的な手法であるしきい値ベースの監視は、実装が容易で理解しやすいという利点がありますが、複雑な異常パターンの検知には限界があります。
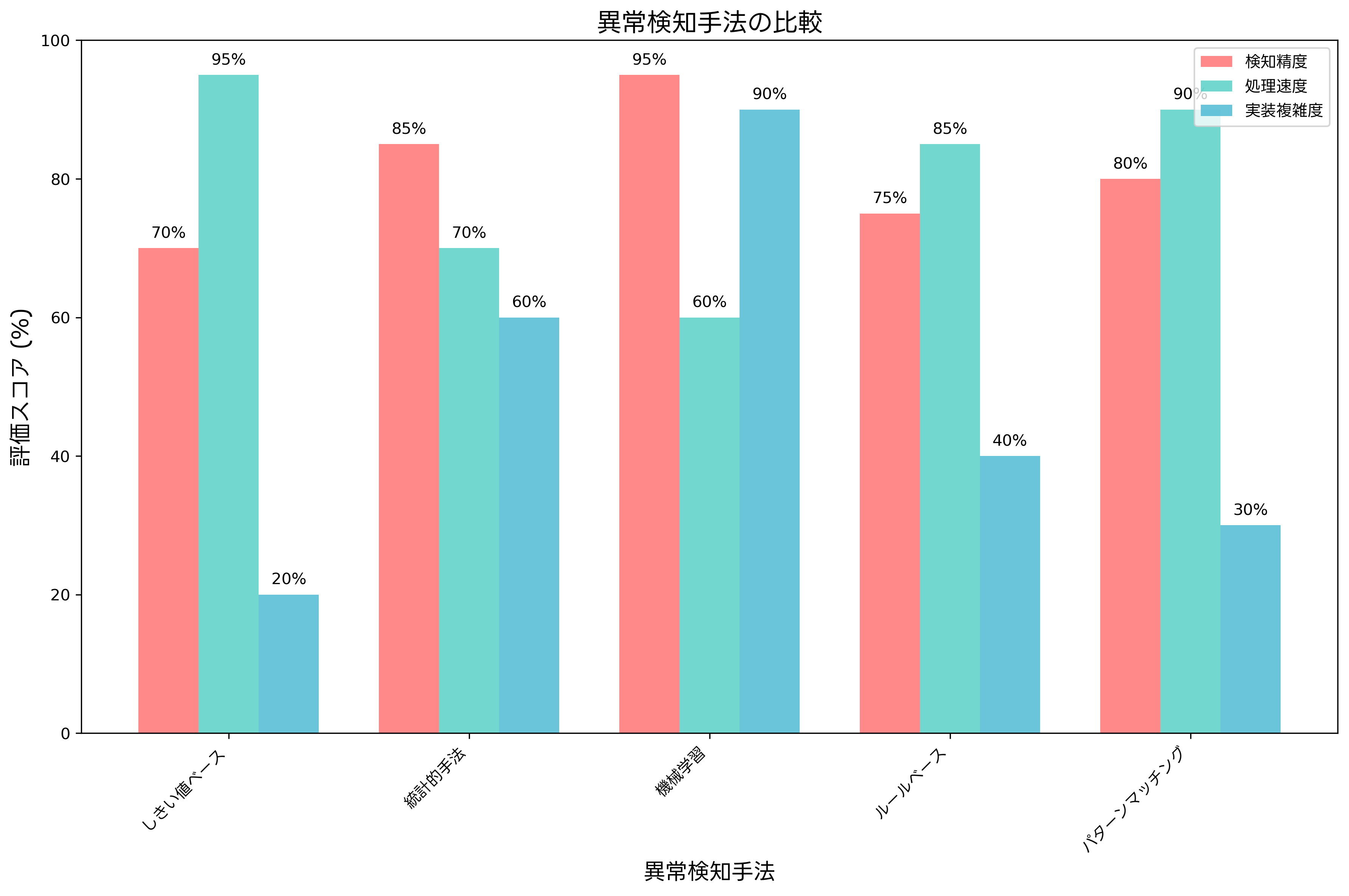
しきい値ベースの監視では、各メトリクスに対して警告レベルと危険レベルの二段階のしきい値を設定し、これらの値を超過した際にアラートを発生させます。例えば、CPU使用率が80%を超えた場合に警告アラート、90%を超えた場合に危険アラートを発生させるような設定が一般的です。この手法は実装が簡単で処理速度も高速ですが、季節性やトレンドを考慮できないという制約があります。
統計的手法による異常検知は、過去のデータの統計的特性を基準として異常を判定します。移動平均、標準偏差、季節調整などの統計手法を用いて、正常な変動範囲を動的に計算し、この範囲を逸脱した値を異常として検知します。統計解析ソフトウェアを活用することで、より精密な統計的異常検知が可能になります。
機械学習による異常検知は、最も高度で精度の高い手法です。教師なし学習アルゴリズム(クラスタリング、異常検知アルゴリズム、オートエンコーダーなど)を用いて、正常パターンを学習し、そこから逸脱するパターンを異常として検知します。深層学習技術の発展により、複雑な多次元データからも高精度で異常を検知できるようになりました。機械学習プラットフォームやAIベース監視ソリューションの導入により、企業でも高度な異常検知が実現可能です。
ルールベースの異常検知は、専門家の知識やベストプラクティスに基づいて定義されたルールによって異常を判定します。例えば、「CPUが90%以上かつメモリが85%以上の状態が5分間継続した場合」のような複合条件による異常判定が可能です。このアプローチは、ドメイン知識を活用できる利点がありますが、ルールの保守が課題となります。
システムメトリクスの監視と分析
実際のシステム監視では、複数のメトリクスを同時に監視し、それらの相関関係を分析することが重要です。単一のメトリクスだけでは見えない異常パターンも、複数のメトリクスを組み合わせることで検知できる場合があります。
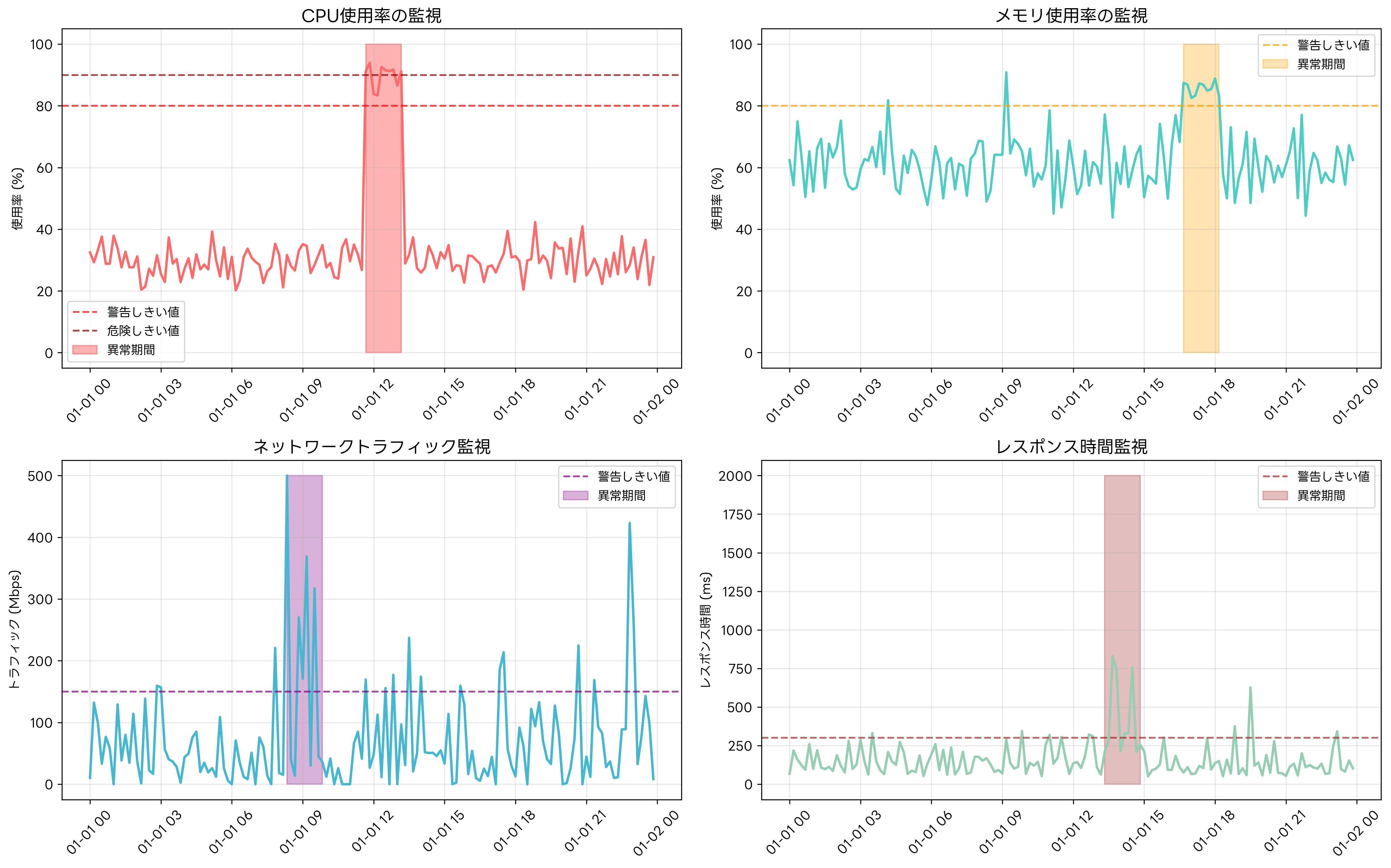
CPU使用率の監視では、瞬間的な高負荷と持続的な高負荷を区別することが重要です。瞬間的な高負荷は正常な処理の範囲内である場合が多いですが、持続的な高負荷はシステムリソースの不足や無限ループなどの異常を示している可能性があります。CPU監視専用ツールを使用することで、詳細なCPU使用パターンの分析が可能になります。
メモリ使用率の監視では、物理メモリの使用量だけでなく、仮想メモリの使用量、メモリリーク、ガベージコレクションの頻度なども重要な指標となります。メモリ不足は段階的に性能劣化を引き起こし、最終的にはシステムクラッシュの原因となるため、早期の検知と対応が必要です。
ネットワークトラフィックの監視では、帯域使用率、パケットロス率、レイテンシ、接続数などを総合的に監視します。DDoS攻撃や異常なデータ転送、ネットワーク機器の障害などは、これらの指標の異常な変動として現れます。ネットワーク監視装置の導入により、詳細なネットワーク分析が可能になります。
アプリケーションレスポンス時間の監視は、エンドユーザーの体感品質に直結する重要な指標です。データベースクエリの応答時間、Webページの読み込み時間、APIの応答時間などを監視し、ユーザー体験の劣化を早期に検知します。アプリケーション性能監視ツールにより、アプリケーション層の詳細な性能分析が実現できます。
アラート管理とエスカレーション体制
効果的な異常監視システムには、適切なアラート管理とエスカレーション体制が不可欠です。単に異常を検知するだけでなく、その重要度に応じて適切な担当者に迅速に通知し、対応を促すメカニズムが重要です。
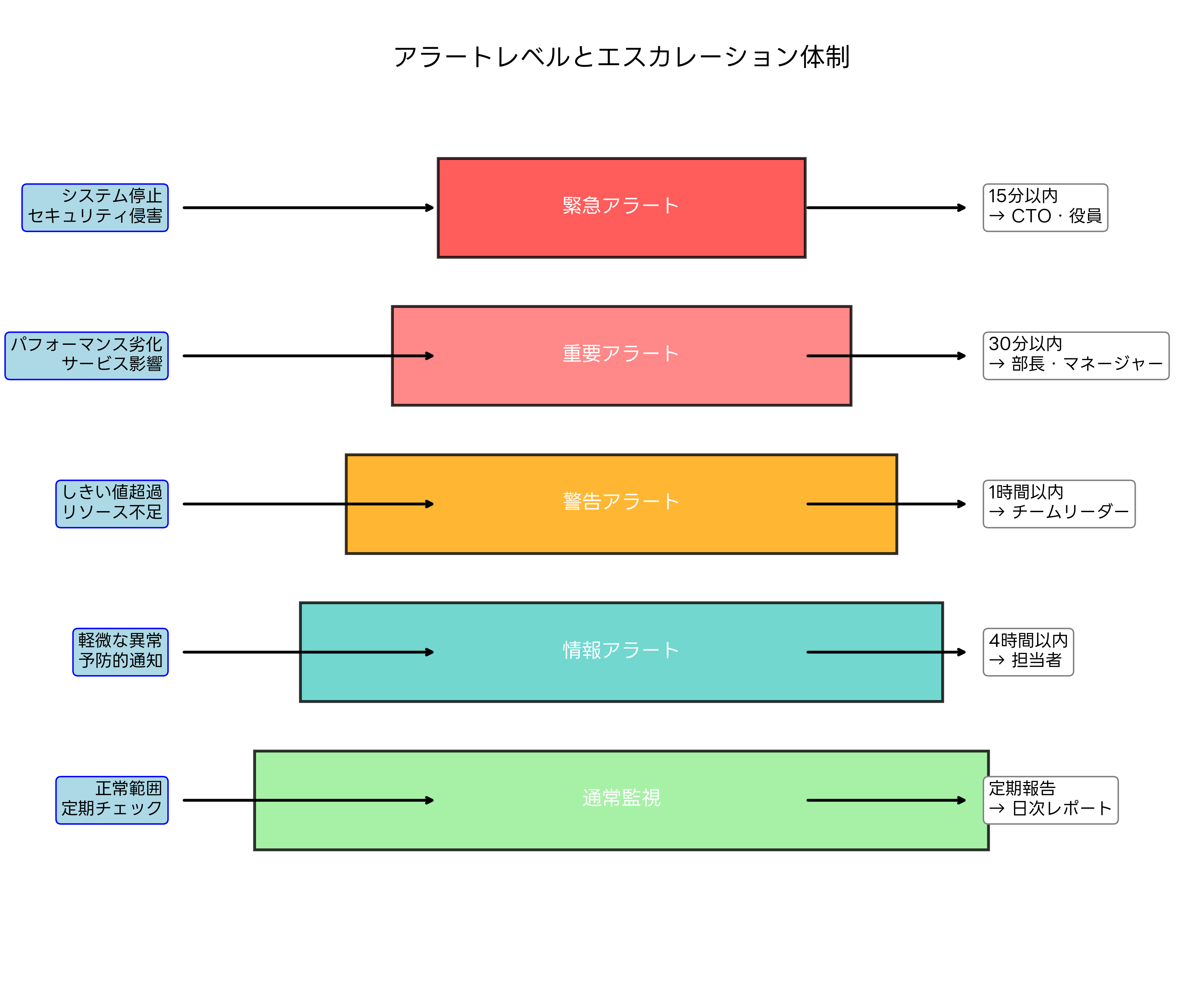
アラートの重要度分類では、システムへの影響度と緊急度に基づいて、通常は4から5段階のレベルに分類します。緊急アラートは、システム停止やセキュリティ侵害など、事業に直接的な影響を与える重大な異常に対して発生し、15分以内に経営層への連絡が必要です。重要アラートは、パフォーマンス劣化やサービス品質低下など、事業への影響が予想される異常に対して発生し、30分以内に管理職への連絡が求められます。
エスカレーション体制では、アラートレベルに応じて自動的に適切な担当者に通知が送られる仕組みを構築します。統合監視プラットフォームを使用することで、メール、SMS、チャットツール、電話などの多様な通知手段を組み合わせた効果的なエスカレーション体制を構築できます。
アラートの誤報対策も重要な要素です。過度に敏感な設定では誤報が多発し、重要なアラートが見過ごされるリスクがあります。逆に、鈍感すぎる設定では重要な異常を見逃す可能性があります。適切なしきい値の調整、複数条件による判定、時間窓による平滑化などの技術を用いて、誤報率を最小化する必要があります。
24時間365日の監視体制では、運用チームのシフト管理と引き継ぎも重要です。運用管理システムを導入することで、シフトスケジュール管理、インシデント引き継ぎ、対応履歴管理などを効率化できます。
主要な監視ツールと選択基準
市場には多数の監視ツールが存在し、それぞれに特徴と適用領域があります。適切なツール選択は、監視要件、システム規模、予算、技術スキルなどを総合的に考慮して決定する必要があります。
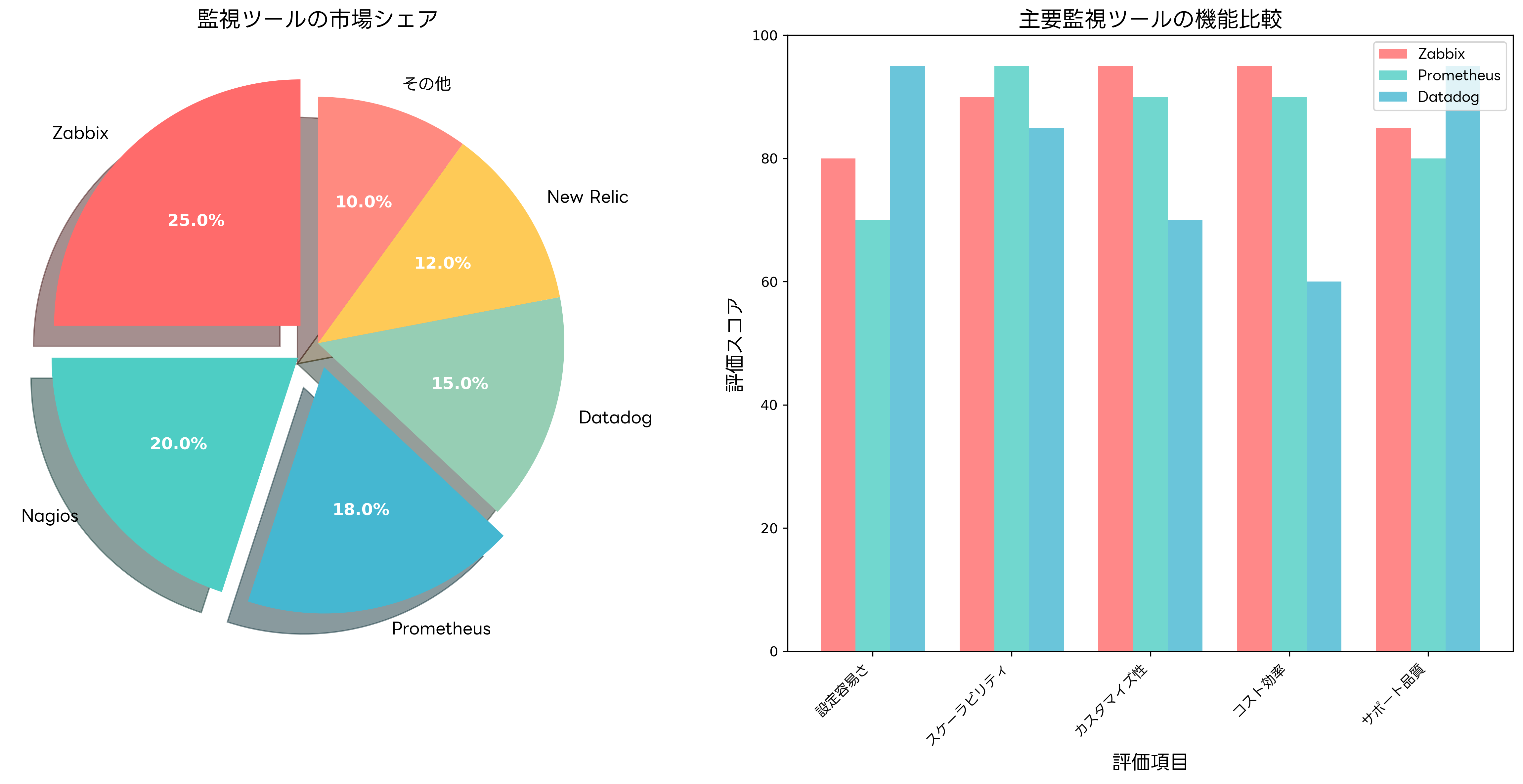
オープンソース系の監視ツールとして、ZabbixとNagiosは長い歴史を持ち、高い信頼性と豊富な機能を提供します。Zabbixは包括的な監視機能とスケーラビリティに優れ、大規模環境での利用に適しています。設定の自由度が高く、Zabbix専門書や構築支援ツールも豊富に提供されています。
Prometheusは、マイクロサービスアーキテクチャやコンテナ環境に特化した現代的な監視ツールです。時系列データベースと強力なクエリ言語を内蔵し、Kubernetesとの統合も容易です。Grafanaとの組み合わせにより、美しい可視化ダッシュボードの作成も可能です。Prometheus監視システムの導入により、モダンなインフラストラクチャ監視が実現できます。
商用ツールでは、DatadogやNew Relicがクラウドネイティブな監視ソリューションとして人気を集めています。これらのサービスは、設定の簡単さ、豊富な事前定義済みダッシュボード、AIベースの異常検知機能などが特徴です。初期設定の手間を大幅に削減でき、クラウド監視ソリューションとして高い評価を得ています。
ツール選択の際には、監視対象の技術スタック、チームの技術スキル、運用体制、予算制約などを考慮する必要があります。また、将来的な拡張性や他システムとの連携も重要な考慮要素です。監視ツール比較ガイドを参考にして、組織に最適なツールを選択することが重要です。
異常監視の投資対効果と経営価値
異常監視システムの導入は、単なるIT運用の効率化を超えて、企業の経営価値向上に直接的に貢献します。適切な投資対効果(ROI)の測定と評価により、経営層への効果的な説明と継続的な投資確保が可能になります。
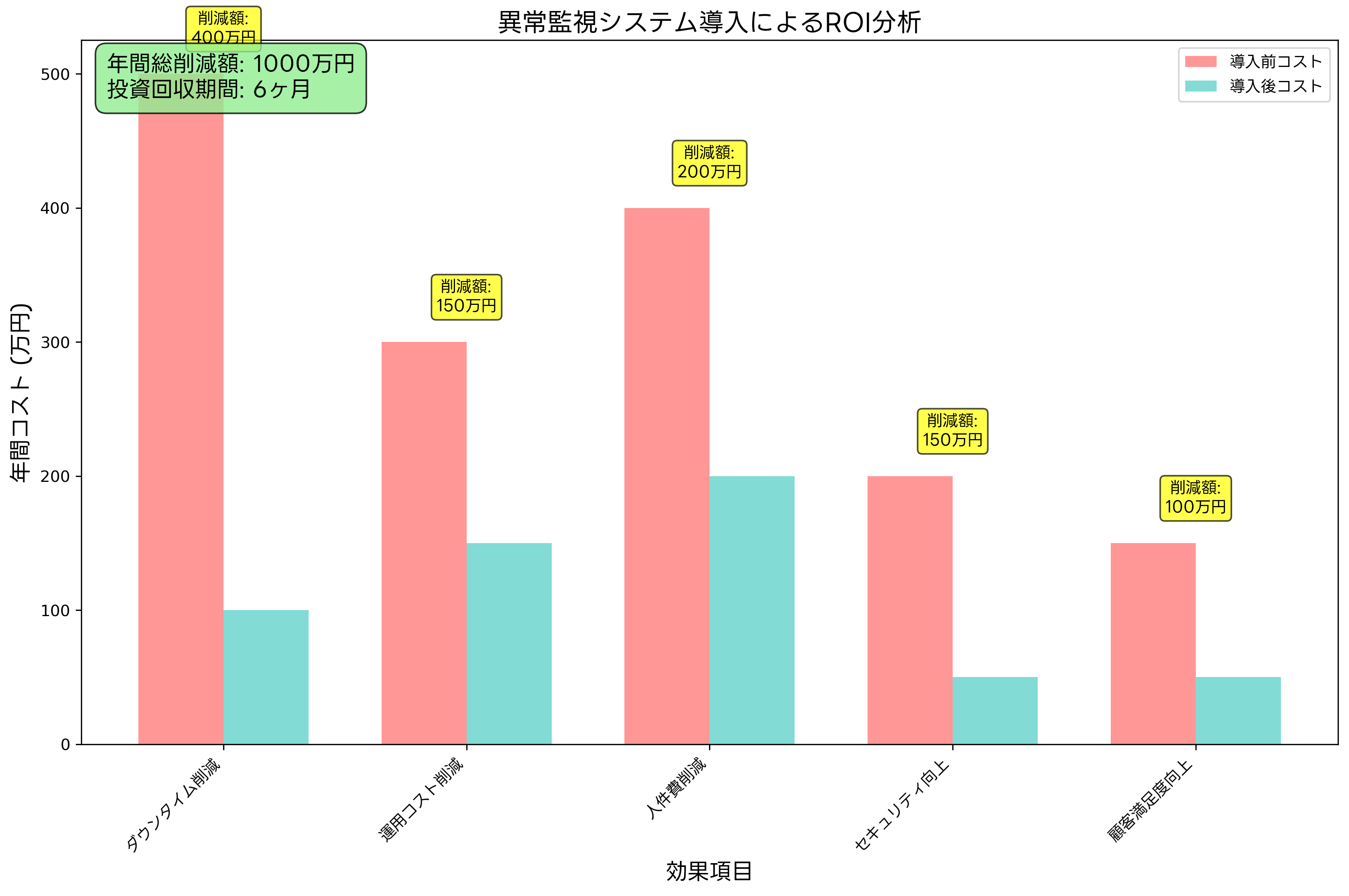
ダウンタイム削減効果は、最も直接的で測定しやすい効果です。システム障害による事業停止は、売上機会の逸失、顧客満足度の低下、復旧作業コストなど、多面的な損失をもたらします。異常監視システムの導入により、障害の早期検知と迅速な対応が可能になり、ダウンタイムを大幅に削減できます。一般的に、1時間のダウンタイムは企業規模に応じて数百万円から数千万円の損失に相当するため、監視システムの投資効果は非常に高くなります。
運用コストの削減も重要な効果です。手動監視から自動監視への移行により、運用担当者の作業負荷が軽減され、より高付加価値な業務に集中できるようになります。また、問題の早期発見により、大規模な障害に発展する前の軽微な段階で修正でき、復旧コストを大幅に削減できます。運用自動化ツールとの組み合わせにより、さらなる効率化が実現できます。
セキュリティ向上効果も見逃せません。異常監視システムは、サイバー攻撃や不正アクセスの早期検知にも有効です。異常なネットワークトラフィック、不正なログイン試行、システムファイルの改ざんなどを迅速に検知し、セキュリティインシデントの拡大を防止できます。セキュリティ監視システムと連携することで、総合的なセキュリティ対策が実現できます。
顧客満足度向上は、長期的な企業価値に大きく貢献します。システムの安定稼働により、顧客は中断されることなくサービスを利用でき、満足度の向上とロイヤルティの強化につながります。また、プロアクティブなシステム管理により、問題が顧客に影響する前に解決でき、信頼性の高いサービス提供が可能になります。
応用情報技術者試験での出題傾向と対策
応用情報技術者試験において、異常監視は主にシステム運用管理の分野で出題されます。試験では、監視技術の理論的理解に加えて、実務での適用方法や問題解決能力が問われます。
午前問題では、監視項目の種類、異常検知手法の特徴、アラート管理の方法、監視ツールの機能比較などが出題されます。例えば、「CPU使用率が継続的に高い状態の原因として最も適切なものはどれか」といった問題や、「統計的異常検知手法の特徴として正しいものはどれか」といった選択問題が典型的です。
午後問題では、より実践的なシナリオでの問題解決が求められます。企業のシステム監視体制の構築、障害対応計画の策定、監視ツールの選定と導入計画などの文脈で、異常監視の知識を活用する能力が評価されます。応用情報技術者試験対策書で基礎知識を固めた上で、システム運用管理の実践書で実務的な理解を深めることが効果的です。
試験対策としては、監視の基本概念だけでなく、各種監視手法の適用場面、メリット・デメリット、実装上の考慮点なども理解しておく必要があります。また、最新の技術動向(AI/ML活用、クラウド監視、コンテナ監視など)についても基本的な理解を持っておくことが望ましいです。
クラウド時代の異常監視
クラウドコンピューティングの普及により、異常監視の対象と手法も大きく変化しています。従来のオンプレミス環境では、物理的なハードウェアから上位のアプリケーションまでを一元的に管理できましたが、クラウド環境では管理責任が分散し、新たな監視戦略が必要になります。
Infrastructure as a Service(IaaS)環境では、仮想マシンやネットワーク、ストレージなどのクラウドリソースの監視が重要です。クラウドプロバイダーが提供する監視サービス(AWS CloudWatch、Azure Monitor、Google Cloud Monitoringなど)を活用し、クラウド特有のメトリクスを監視します。クラウド監視ソリューションにより、マルチクラウド環境での統合監視も実現できます。
Platform as a Service(PaaS)環境では、アプリケーションレベルの監視に重点が置かれます。コンテナオーケストレーション(Kubernetes)環境での監視、サーバーレスアーキテクチャでの監視、マイクロサービス間の分散トレーシングなど、新しい監視技術の習得が必要です。
ハイブリッドクラウド環境では、オンプレミスとクラウドを横断した統合監視が課題となります。ハイブリッドクラウド監視プラットフォームを導入することで、一元的な監視体制の構築が可能になります。
人工知能・機械学習の活用
近年、人工知能(AI)と機械学習(ML)技術の異常監視への応用が急速に進んでいます。従来のルールベースや統計ベースの手法では検知が困難だった複雑な異常パターンも、AI/ML技術により高精度で検知できるようになりました。
教師なし学習による異常検知では、正常時のデータパターンを学習し、そこから逸脱するパターンを異常として検知します。オートエンコーダー、One-Class SVM、Isolation Forestなどのアルゴリズムが広く使用されています。機械学習異常検知ツールの導入により、高度な異常検知が実現できます。
時系列異常検知では、LSTM(Long Short-Term Memory)やTransformerなどの深層学習モデルを用いて、時系列データの複雑なパターンを学習し、未来の値を予測します。予測値と実測値の乖離が大きい場合に異常として検知する仕組みです。
マルチモーダル異常検知では、複数種類のデータ(数値データ、ログデータ、画像データなど)を統合的に分析し、単一データでは検知できない異常も発見できます。AI統合監視プラットフォームにより、包括的な異常検知が可能になります。
組織的な取り組みと人材育成
効果的な異常監視体制の構築には、技術的な要素だけでなく、組織的な取り組みと人材育成が不可欠です。監視業務は24時間365日継続される重要な業務であり、適切な体制整備と継続的なスキル向上が必要です。
監視センター(NOC: Network Operations Center)の設置は、大規模な組織では一般的な取り組みです。専門的な監視要員を配置し、標準化された手順に基づいて監視業務を実施します。NOC構築ガイドを参考にして、効率的な監視センターの設計が可能です。
運用手順書(SOP: Standard Operating Procedure)の整備も重要です。異常検知時の対応手順、エスカレーション基準、復旧作業手順などを文書化し、誰でも一定品質の対応ができる体制を構築します。IT運用手順書作成ガイドにより、効果的な手順書作成が可能です。
継続的な教育訓練により、監視要員のスキル向上を図ります。新しい監視技術の習得、障害対応演習、ベンダー認定資格の取得などを通じて、専門性を高めます。システム監視技術者向け研修や監視ツール認定コースの活用が効果的です。
将来展望と新技術動向
異常監視技術は、IT技術の発展とともに継続的に進化しています。今後の技術動向を理解し、将来に向けた戦略的な投資を行うことが、競争優位の維持に重要です。
エッジコンピューティングの普及により、監視処理の分散化が進んでいます。クラウドだけでなくエッジデバイスでもリアルタイム監視が可能になり、ネットワーク遅延の削減とプライバシー保護の両立が実現できます。エッジ監視ソリューションの導入により、新しい監視アーキテクチャが構築できます。
5G通信技術の普及により、IoTデバイスの大規模監視が可能になります。製造現場、交通インフラ、スマートシティなど、様々な分野でリアルタイム監視が実現され、新しいビジネス価値の創出が期待されます。
量子コンピューティング技術の発展により、将来的には超大規模データの並列処理による高速異常検知が可能になると予想されます。また、ブロックチェーン技術を活用した監視ログの改ざん防止、信頼性の確保なども研究が進んでいます。
まとめ
異常監視は、現代のITシステム運用において不可欠な技術であり、企業の事業継続性と競争力を支える重要な基盤です。技術的な理解だけでなく、組織的な取り組み、投資対効果の測定、将来動向の把握など、多面的なアプローチが必要です。
応用情報技術者試験においても重要なトピックであり、理論的な知識と実践的な応用能力の両方が求められます。継続的な学習と実践を通じて、変化する技術環境に対応できる専門性を身につけることが重要です。
適切な異常監視システムの構築と運用により、企業はシステム障害のリスクを最小化し、安定したサービス提供を実現できます。これにより、顧客満足度の向上、事業機会の拡大、競争優位の確立が可能になり、持続的な成長を支える基盤となります。