現代の情報化社会において、膨大なデータの中から異常な状態やパターンを自動的に検出する異常検知技術は、セキュリティ分野の革新をもたらしています。従来の人手による監視では発見困難な微細な異常や、大規模なデータ群に潜む隠れた脅威を、機械学習とAI技術によって効率的に検出することが可能になりました。応用情報技術者試験においても、この技術の理解は現代のIT専門家として必須の知識となっています。
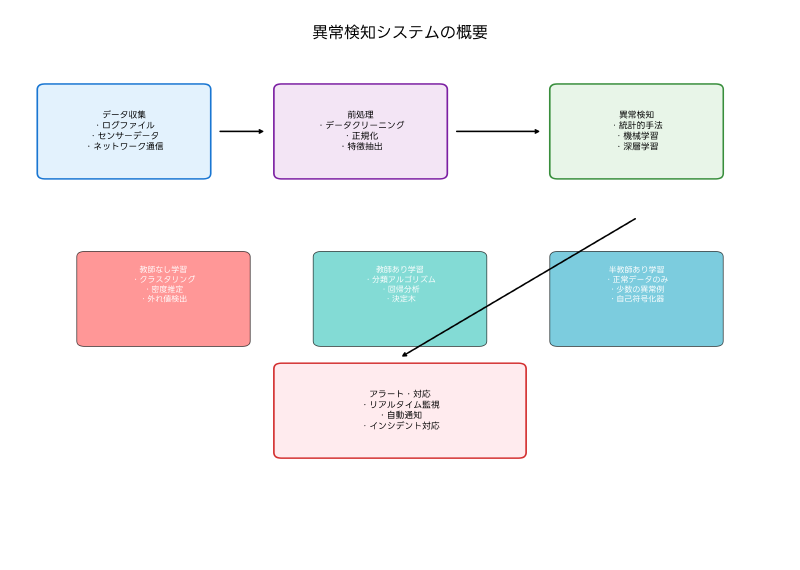
異常検知とは、通常のパターンや基準から大きく逸脱したデータやイベントを自動的に識別する技術です。この技術は、ネットワークセキュリティ、製造業の品質管理、金融取引の不正検知、ヘルスケアシステムの監視など、幅広い分野で活用されています。特に、サイバーセキュリティの領域では、未知の攻撃手法や内部脅威の検出において、従来のシグネチャベースの検知手法を大幅に上回る性能を発揮しています。
異常検知の基本概念と理論的背景
異常検知の基本的な考え方は、正常なデータのパターンを学習し、そのパターンから逸脱したデータを異常として識別することです。この技術の核心は、正常性の定義と異常度の定量化にあります。統計学的アプローチでは、データの分布や確率密度を基にして異常度を計算し、機械学習アプローチでは、アルゴリズムがデータから自動的にパターンを学習します。
正常データの特徴を効果的に捉えるためには、高性能なデータ前処理ツールが重要な役割を果たします。データのクリーニング、正規化、特徴抽出などの前処理により、異常検知アルゴリズムの精度を大幅に向上させることができます。
異常検知手法は、学習方法によって大きく三つのカテゴリに分類されます。教師なし学習では、正常データのみを使用してモデルを構築し、教師あり学習では正常と異常の両方のラベル付きデータを使用します。半教師あり学習は、大量の正常データと少量の異常データを組み合わせて学習を行います。
統計的手法による異常検知では、データの分布を仮定し、その分布からの逸脱度を測定します。正規分布を仮定した場合、平均から標準偏差の2倍以上離れたデータを異常とする方法が一般的です。統計解析ソフトウェアを使用することで、複雑な統計的計算を効率的に実行できます。
距離ベースの手法では、各データポイントが他のデータポイントからどの程度離れているかを測定し、孤立したデータを異常として検出します。この手法は、クラスタリングアルゴリズムと組み合わせることで、より高精度な異常検知が実現できます。
密度ベースの手法は、データの密度が低い領域にあるポイントを異常として識別します。この手法は、複雑な形状のデータ分布にも対応できるため、実際のビジネスデータに適用する際に有効です。
機械学習を活用した高度な異常検知技術
現代の異常検知技術の中核を成すのが、機械学習アルゴリズムです。サポートベクターマシン(SVM)による異常検知では、正常データの境界を学習し、その境界から外れたデータを異常として識別します。One-Class SVMは、正常データのみで学習が可能であり、実際の運用環境で威力を発揮します。
機械学習開発環境の整備により、複雑なアルゴリズムの実装と実験が容易になりました。PythonやRなどのプログラミング言語と、scikit-learn、TensorFlowなどのライブラリを組み合わせることで、高度な異常検知システムを効率的に構築できます。
クラスタリングベースの異常検知では、k-meansやDBSCANなどのアルゴリズムを使用して、データを自然なクラスターに分割し、どのクラスターにも属さないデータを異常として検出します。この手法は、データの構造を理解しながら異常を検知できるため、解釈性の高い結果が得られます。
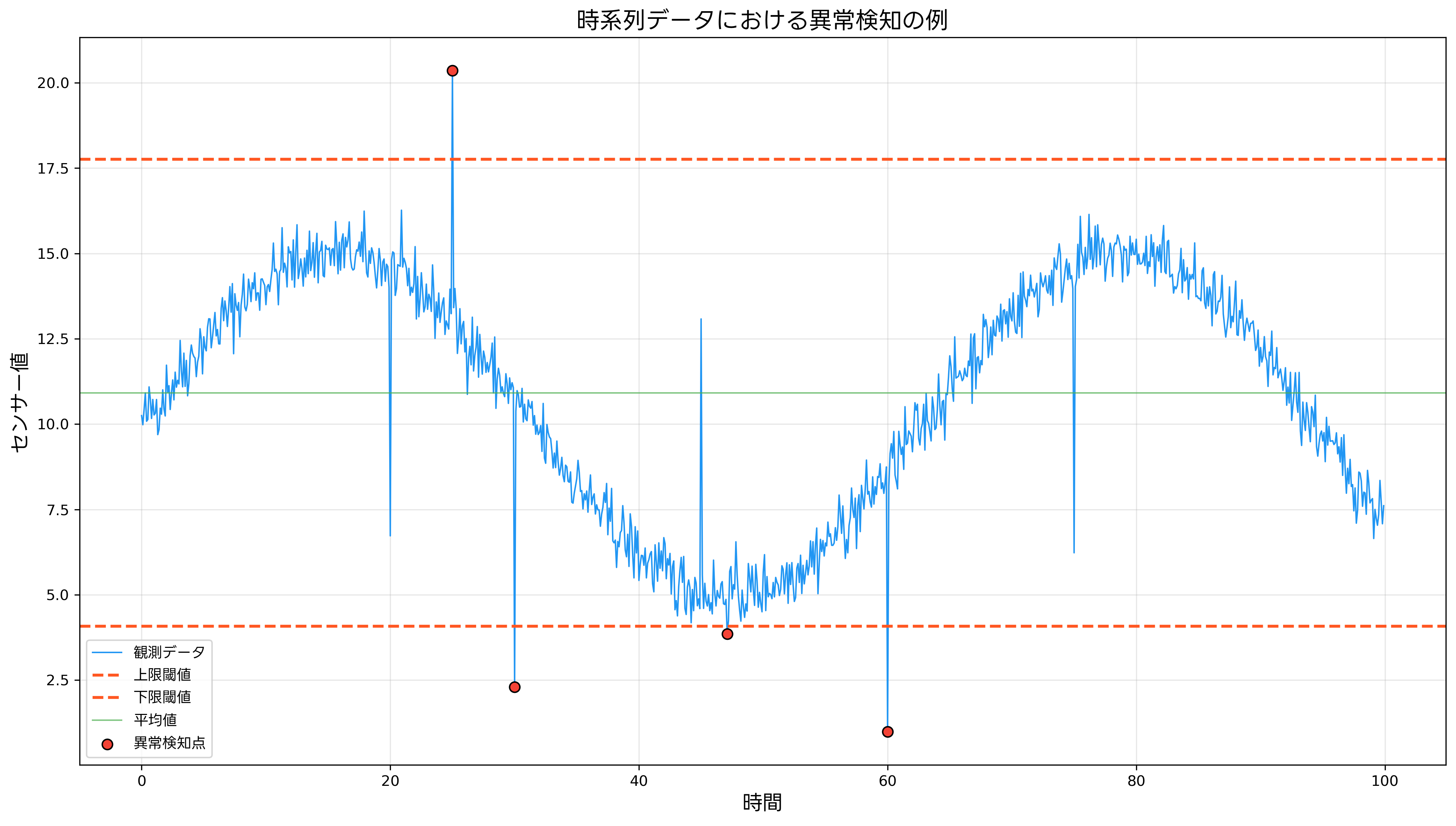
時系列データの異常検知では、過去のパターンから未来の値を予測し、実際の観測値との差異を基に異常を判定します。ARIMAモデル、LSTMネットワーク、Prophet等の手法が広く使用されており、時系列解析専用ソフトウェアによって実装が容易になっています。
アンサンブル学習による異常検知では、複数の異なるアルゴリズムの結果を統合することで、単一手法では検出困難な複雑な異常パターンを識別できます。Random ForestやIsolation Forestなどの手法は、高い精度と堅牢性を実現し、実際のセキュリティシステムで広く採用されています。
深層学習による異常検知では、自己符号化器(Autoencoder)が特に重要な役割を果たしています。正常データを学習した自己符号化器は、異常データに対して高い復元誤差を示すため、この誤差を異常度として利用できます。GPU搭載の高性能ワークステーションにより、大規模な深層学習モデルの訓練が現実的になりました。
ネットワークセキュリティにおける異常検知の実装
ネットワークセキュリティの分野では、異常検知技術が侵入検知システム(IDS)や侵入防止システム(IPS)の核心技術として活用されています。従来のシグネチャベースの検知では、既知の攻撃パターンしか検出できませんでしたが、異常検知技術により、未知の攻撃手法や標的型攻撃の検出が可能になりました。
次世代ファイアウォールには、機械学習ベースの異常検知機能が組み込まれており、リアルタイムでネットワークトラフィックを分析し、疑わしい通信パターンを検出します。これらのシステムは、大量のトラフィックデータを高速で処理し、攻撃の初期段階で脅威を識別できます。
ログ解析による異常検知では、システムログ、アプリケーションログ、ネットワークログなど、多様なログデータを統合的に分析します。統合ログ管理システムを導入することで、膨大なログデータから異常なパターンを効率的に抽出し、セキュリティインシデントの早期発見が可能になります。
ユーザー行動分析(UBA)は、内部脅威の検出において特に有効な手法です。各ユーザーの通常の行動パターンを学習し、そのパターンから逸脱した行動を検出することで、不正アクセスや情報漏洩のリスクを軽減できます。ユーザー行動分析ツールにより、細かな行動変化も検出できるようになりました。
ネットワークフロー分析では、通信パターンの異常を検出することで、マルウェアの感染拡大やデータ窃取の試みを早期に発見できます。NetFlowやsFlowなどのプロトコルによって収集されたフロー情報を機械学習アルゴリズムで分析し、正常な通信パターンから逸脱した通信を特定します。
エンドポイント検知対応(EDR)システムでは、個々の端末における異常な動作を検出します。プロセスの実行パターン、ファイルアクセスパターン、ネットワーク通信パターンなどを総合的に分析し、マルウェアの活動や不正な操作を検出します。EDRソリューションの導入により、企業の全端末を統一的に監視できます。
製造業とIoTシステムでの異常検知応用
製造業における異常検知は、設備の予知保全、品質管理、生産性向上に大きく貢献しています。センサーデータを連続的に監視し、機械の振動、温度、圧力などのパラメータから異常な状態を早期に検出することで、計画外停止の防止とメンテナンスコストの削減を実現できます。
産業用IoTセンサーの普及により、製造プロセスのあらゆる段階でリアルタイムデータ収集が可能になりました。これらのセンサーから得られる大量のデータを機械学習アルゴリズムで解析することで、人間では察知困難な微細な変化も検出できます。
予知保全では、機器の劣化パターンを学習し、故障が発生する前に適切なメンテナンス時期を予測します。これにより、計画的なメンテナンススケジュールの策定が可能になり、生産効率の向上と保全コストの最適化を同時に実現できます。予知保全システムの導入により、製造業の競争力強化が図れます。
品質管理における異常検知では、製品の寸法、重量、外観などの品質データから不良品の発生パターンを学習し、品質問題の早期発見と根本原因の特定を支援します。品質管理システムと異常検知技術の組み合わせにより、一貫した品質管理体制を構築できます。
スマートファクトリーでは、生産ライン全体の統合的な監視により、個別の機器だけでなく、プロセス全体の最適化を図ります。複数の工程間の相関関係を分析し、上流工程の変化が下流工程に与える影響を予測することで、生産計画の精密化と効率向上を実現できます。
エネルギー管理においても異常検知技術は重要な役割を果たします。電力消費パターンの分析により、設備の異常運転や無駄なエネルギー消費を検出し、省エネルギー対策の立案に活用できます。エネルギー管理システムにより、工場全体のエネルギー効率を最適化できます。
金融業界における不正検知システム
金融業界では、クレジットカード不正利用、マネーロンダリング、内部不正など、様々な金融犯罪の検出に異常検知技術が活用されています。取引パターンの分析により、通常の取引行動から大きく逸脱した不審な取引を自動的に検出し、リアルタイムでアラートを発出できます。
クレジットカード不正検知では、カード利用者の過去の取引履歴から個人の消費パターンを学習し、地理的に離れた場所での同時利用、高額取引の急増、普段利用しない店舗での取引などの異常パターンを検出します。不正検知システムにより、被害の最小化と顧客保護を実現できます。
マネーロンダリング検知では、複数の金融機関間での取引パターンを分析し、資金洗浄に使用される可能性のある複雑な取引経路を特定します。規制当局の要求に対応するため、コンプライアンス管理システムと異常検知技術を統合し、効率的な監視体制を構築できます。
保険不正検知では、保険請求の内容と過去のデータを比較し、虚偽申告や誇張された請求を検出します。医療データ、修理見積もり、事故状況などの多角的な情報を統合的に分析することで、従来の手動審査では発見困難な巧妙な不正も検出できます。
アルゴリズム取引の監視では、高頻度取引における異常なパターンを検出し、市場操作や不正取引を防止します。金融取引監視システムにより、市場の健全性維持と投資家保護を実現できます。
リスク管理においても異常検知は重要な役割を果たします。市場リスク、信用リスク、オペレーショナルリスクの各分野で、通常の変動パターンから逸脱したリスク要因を早期に発見し、適切なリスク対応策の実施を支援します。
異常検知システムの性能評価と最適化
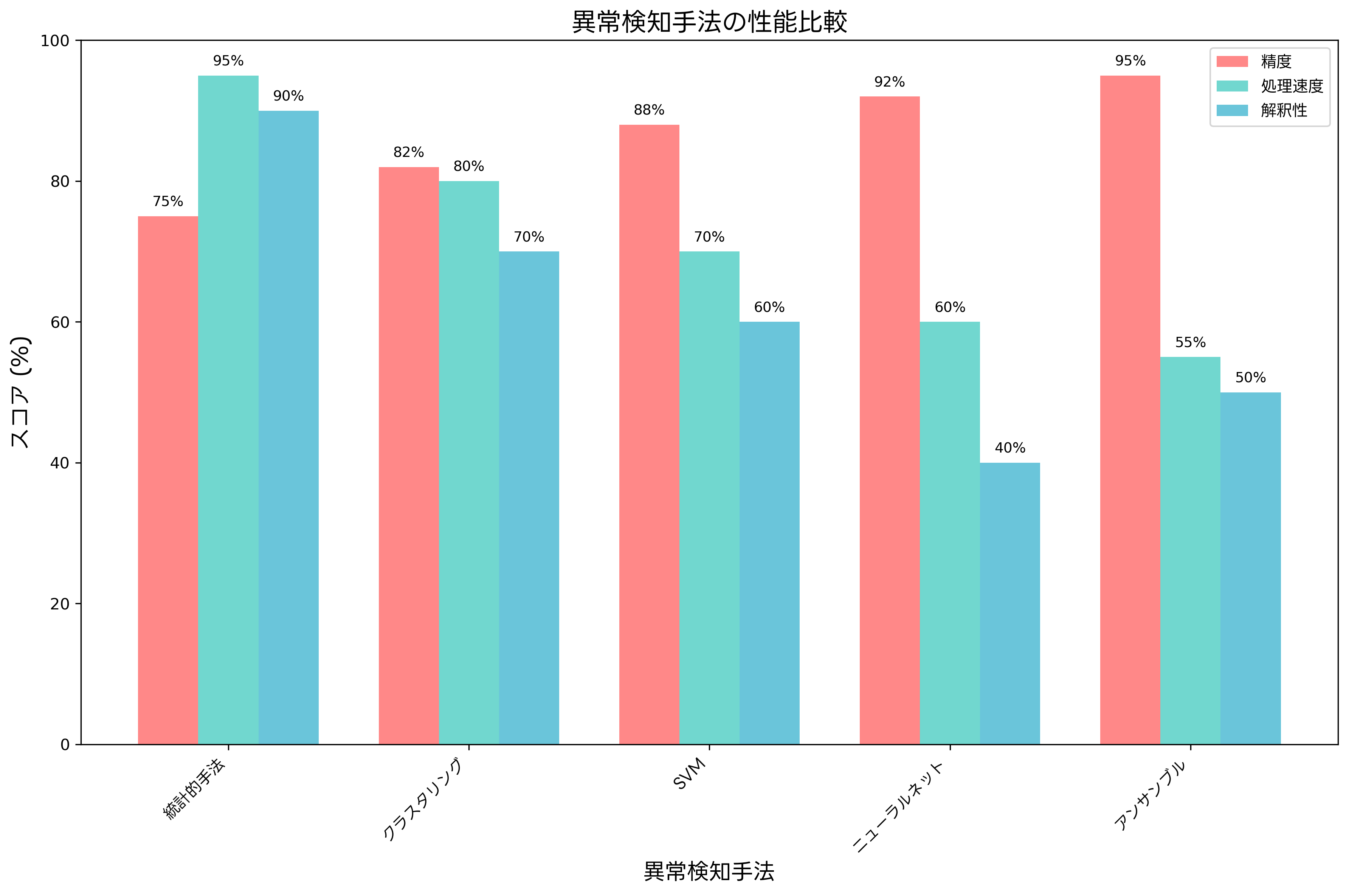
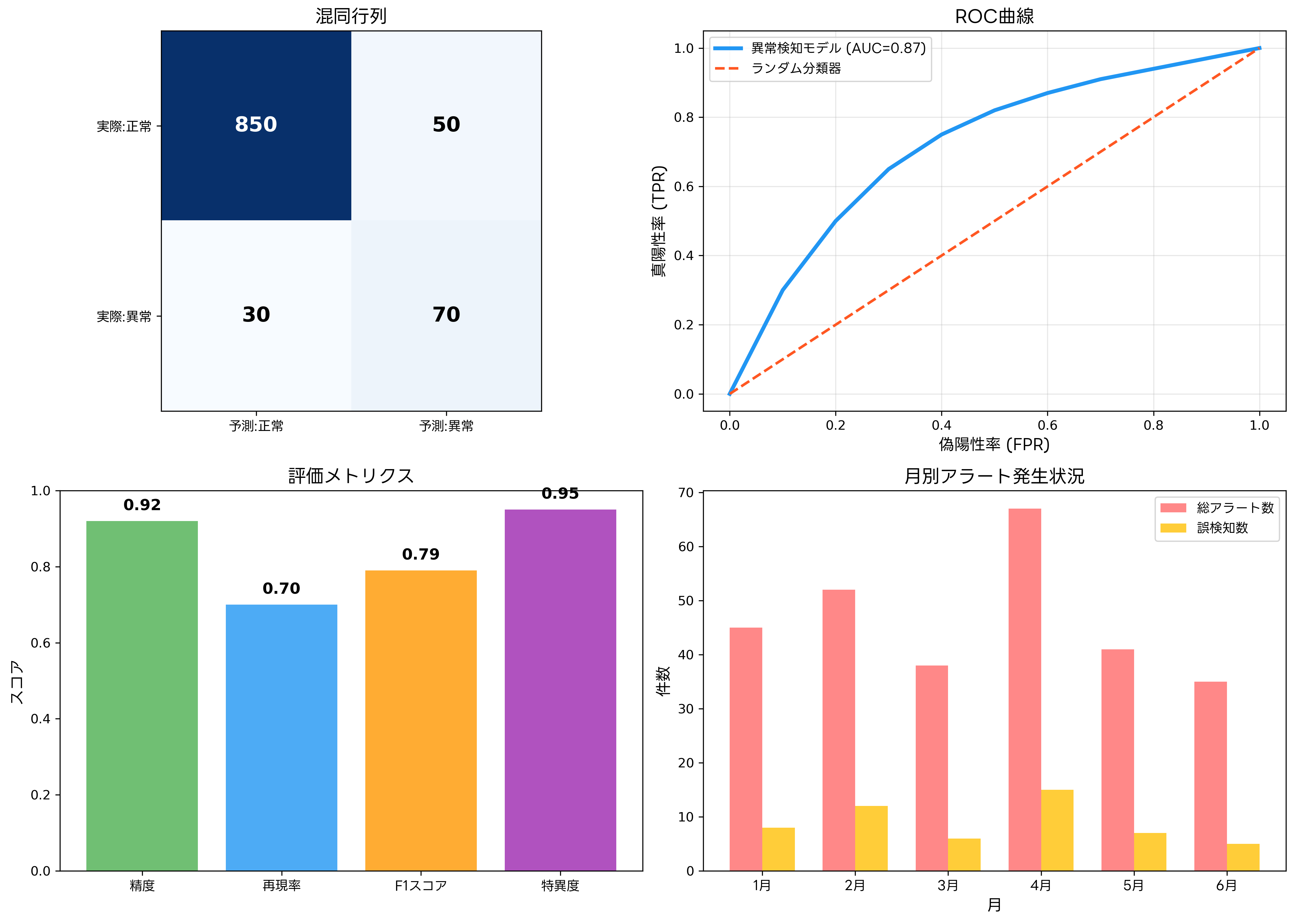
異常検知システムの性能評価には、精度、再現率、F1スコア、偽陽性率など、複数の指標を総合的に考慮する必要があります。特に、誤検知(偽陽性)の最小化は、運用負荷の軽減と実用性の確保にとって極めて重要です。
ROC曲線とAUC値は、異常検知モデルの性能を評価する標準的な手法です。真陽性率と偽陽性率の関係を可視化することで、モデルの識別能力を客観的に評価できます。機械学習評価ツールを使用することで、複数のモデルの性能を効率的に比較できます。
クロスバリデーションによるモデル検証では、限られたデータからモデルの汎化性能を適切に評価できます。特に、時系列データでは、時間的な順序を考慮した検証手法が重要になります。訓練データと検証データの適切な分割により、過学習の防止と実際の運用環境での性能予測が可能になります。
ハイパーパラメータの最適化は、異常検知モデルの性能向上において重要な要素です。グリッドサーチ、ランダムサーチ、ベイズ最適化などの手法により、最適なパラメータの組み合わせを効率的に探索できます。ハイパーパラメータ最適化ツールにより、自動化された最適化プロセスを実現できます。
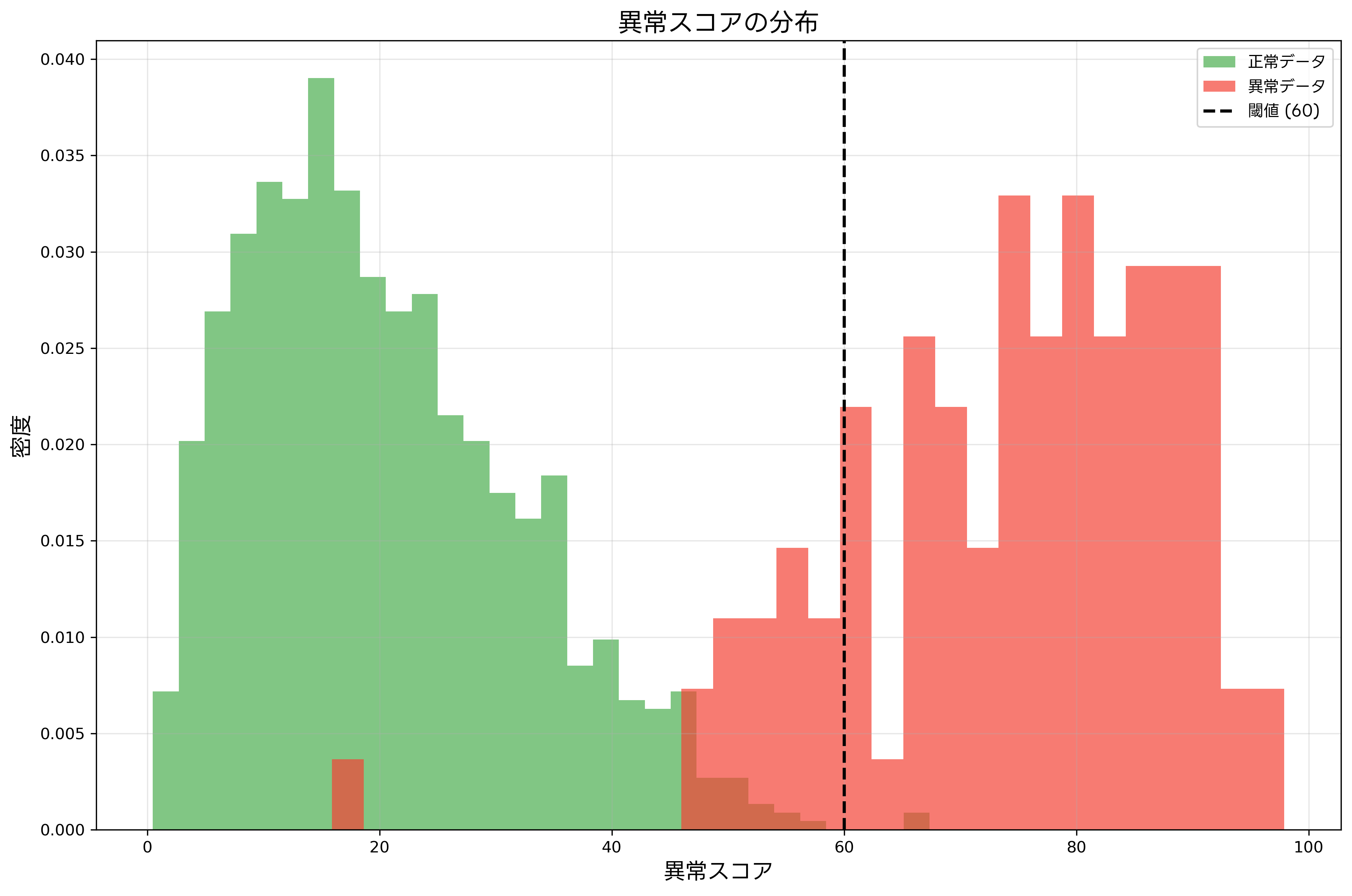
閾値の設定は、異常検知システムの実用性を左右する重要な要素です。ビジネス要件に応じて、検知感度と誤検知率のバランスを調整し、運用に適した閾値を決定する必要があります。動的閾値調整により、データの特性変化に自動的に対応できるシステムも開発されています。
アンサンブル手法による性能向上では、複数の異なるアルゴリズムの予測結果を統合することで、単一手法では達成困難な高精度を実現できます。投票法、重み付き平均、スタッキングなどの手法により、各アルゴリズムの長所を活かした統合システムを構築できます。
リアルタイム異常検知システムの構築
現代のビジネス環境では、リアルタイムでの異常検知が求められています。ストリーミングデータ処理技術により、大量のデータを低遅延で処理し、即座に異常を検出できるシステムの構築が可能になりました。
ストリーミング処理プラットフォームを活用することで、Apache Kafka、Apache Storm、Apache Flinkなどの技術を組み合わせた高性能なリアルタイム処理システムを構築できます。これらのプラットフォームにより、秒単位またはミリ秒単位での異常検知が実現できます。
エッジコンピューティングによる分散処理では、データ発生源に近い場所で処理を行うことで、通信遅延の最小化とリアルタイム性の向上を実現できます。エッジコンピューティングデバイスにより、工場やオフィスなどの現場レベルでの即座な異常検知が可能になります。
インメモリデータベースの活用により、大量のデータを高速でアクセス可能な状態で保持し、リアルタイム分析の性能を大幅に向上させることができます。Redis、MemcachedなどのInMemoryデータストアと機械学習アルゴリズムを組み合わせることで、高速な異常検知処理を実現できます。
マイクロサービスアーキテクチャによるシステム設計では、異常検知機能を独立したサービスとして実装し、他のシステムとの疎結合を実現できます。コンテナオーケストレーション技術により、スケーラブルで堅牢な異常検知システムを構築できます。
応用情報技術者試験での出題傾向と対策
応用情報技術者試験において、異常検知技術は情報セキュリティ、データベース、システム開発などの複数の分野にまたがって出題されています。特に、機械学習とAIの普及により、これらの技術に関する問題が増加傾向にあります。
午前問題では、異常検知の基本概念、主要なアルゴリズム、評価指標、実装技術などが問われます。統計的手法と機械学習手法の違い、教師あり学習と教師なし学習の特徴、精度と再現率のトレードオフなど、理論的な理解が求められます。
午後問題では、具体的なビジネスシナリオにおける異常検知システムの設計と運用に関する実践的な問題が出題されます。システム要件の分析、適切な手法の選択、性能評価の方法、運用上の課題とその対策などが主要なテーマです。
試験対策としては、応用情報技術者試験対策書で基礎知識を習得し、機械学習実践ガイドで実装技術を学習することが効果的です。また、データサイエンス関連書籍により、統計学的背景の理解を深めることも重要です。
実際のプログラミング経験も試験対策として有効です。PythonやRを使用した異常検知アルゴリズムの実装により、理論と実践の橋渡しができます。プログラミング学習環境を整備し、実際にコードを書いて動作を確認することで、深い理解が得られます。
新技術との融合と将来展望
量子コンピューティングの発展により、従来の計算では処理困難な大規模データの異常検知が可能になると期待されています。量子機械学習アルゴリズムにより、指数的に高速な異常検知処理が実現される可能性があります。
量子コンピューティング学習リソースにより、次世代技術の基礎知識を習得し、将来の技術動向に備えることができます。
フェデレーテッドラーニングにより、複数の組織間でデータを共有することなく、協調的な異常検知モデルの構築が可能になります。プライバシーを保護しながら、より豊富なデータによる高精度な異常検知が実現できます。
説明可能AI(XAI)の発展により、異常検知結果の根拠を人間が理解可能な形で提示できるようになりました。ブラックボックス化しがちな機械学習モデルの判断過程を可視化することで、運用者の信頼性向上と適切な対応判断を支援できます。
AutoMLによる自動化により、機械学習の専門知識を持たない運用者でも高精度な異常検知システムを構築できるようになります。AutoMLプラットフォームにより、民主化された機械学習環境が実現されています。
まとめ
異常検知技術は、現代のデジタル社会における重要な基盤技術として、セキュリティ、製造業、金融業など、幅広い分野で革新をもたらしています。機械学習とAI技術の進歩により、従来では検出困難だった複雑な異常パターンも効率的に識別できるようになりました。
応用情報技術者として、この技術の理論的背景と実践的な応用方法を理解することは、現代のIT専門家にとって必須の要件です。統計学、機械学習、システム設計の知識を総合的に活用し、ビジネス要件に適した異常検知システムを構築できる能力が求められています。
技術の急速な進歩により、異常検知の手法と応用範囲は今後も拡大し続けることが予想されます。継続的な学習と実践により、変化する技術環境に対応し、組織の競争力向上に貢献できる専門家として成長することが重要です。新しい技術やツールを積極的に活用し、実際のビジネス課題の解決に異常検知技術を応用することで、理論と実践の両面での専門性を高めることができます。