プログラミングにおいてインクリメント演算は、変数の値を1増加させる基本的な操作です。応用情報技術者試験においても頻出の重要なトピックであり、単純に見える演算でありながら、その実装方法や使用法には奥深い技術的側面が存在します。本記事では、インクリメント演算の基本概念から高度な応用まで、包括的に解説していきます。
インクリメント演算には前置インクリメント(++i)と後置インクリメント(i++)の2つの形式があり、それぞれ異なる動作特性を持ちます。この違いを正確に理解することは、効率的なプログラムを作成する上で極めて重要です。また、対となるデクリメント演算(–i, i–)についても同様の原理が適用されます。
前置インクリメントと後置インクリメントの基本動作
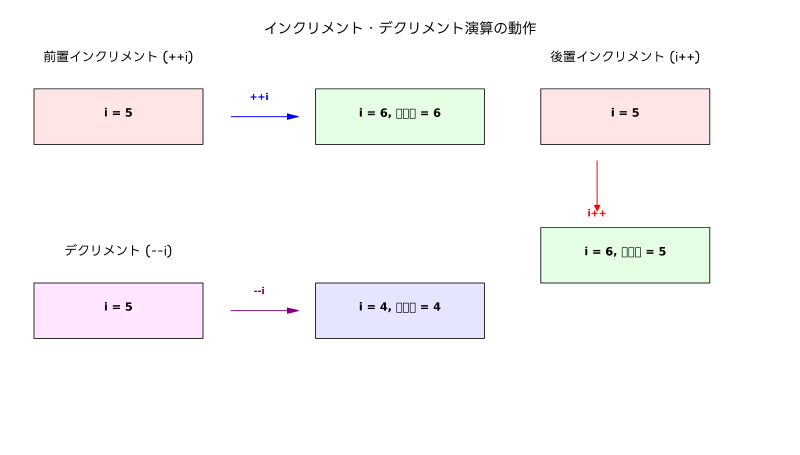
前置インクリメント(++i)は、変数iの値を1増加させ、増加後の値を返します。一方、後置インクリメント(i++)は、変数iの現在の値を一時的に保存し、変数を1増加させた後、保存しておいた元の値を返します。この動作の違いは、式の評価順序や戻り値の使用において重要な意味を持ちます。
具体的な例を考えてみましょう。変数iの初期値が5の場合、++iを実行すると変数iは6になり、式の戻り値も6となります。これに対してi++を実行すると、変数iは6になりますが、式の戻り値は元の値である5となります。この違いは、代入文や条件文の中でインクリメント演算を使用する際に、プログラムの動作に大きな影響を与える可能性があります。
プログラミング言語によっては、インクリメント演算の実装方法が異なる場合があります。C言語やC++では、インクリメント演算子のオーバーロードが可能であり、カスタムクラスに対して独自のインクリメント動作を定義できます。プログラミング言語解説書を参考にすることで、各言語固有の特徴を深く理解できます。
実際の開発現場では、インクリメント演算の使い方によってコードの可読性と保守性が大きく変わります。特に複雑な式の中でインクリメント演算を使用する場合は、意図しない副作用を避けるために注意深い設計が必要です。コーディング規約ガイドブックには、インクリメント演算の適切な使用方法に関する詳細な指針が記載されています。
性能面での考慮事項と最適化
インクリメント演算の性能特性は、データ型や実行環境によって大きく異なります。基本データ型(int、long等)に対するインクリメント演算では、前置と後置の性能差はほとんどありませんが、クラス型や反復子(イテレータ)に対するインクリメント演算では、明確な性能差が生じることがあります。
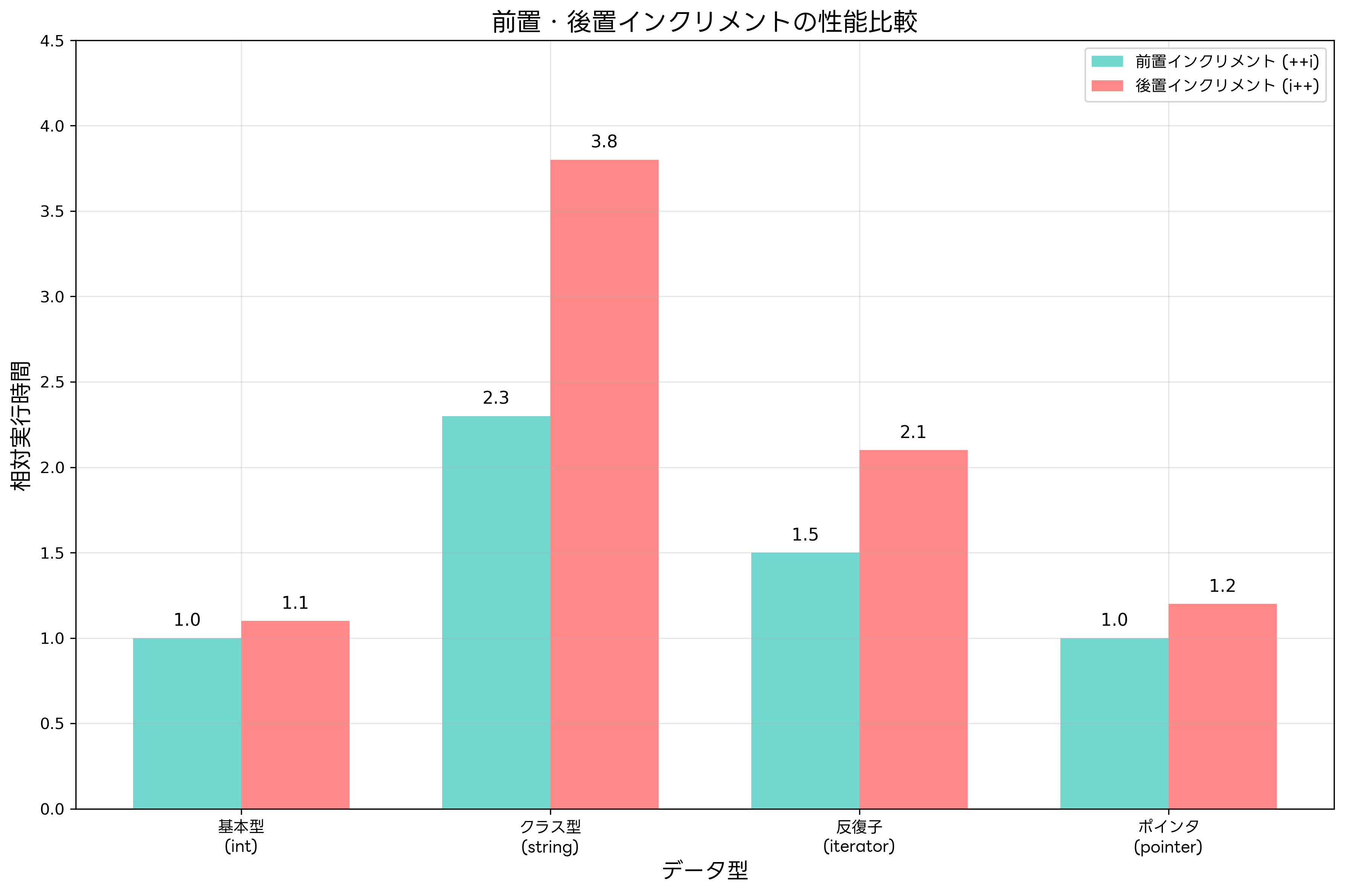
後置インクリメントは一時オブジェクトの生成が必要なため、特にクラス型のオブジェクトに対して使用する場合、前置インクリメントよりも多くのメモリとCPUサイクルを消費します。例えば、std::stringクラスのオブジェクトに対して後置インクリメントを適用すると、元のオブジェクトのコピーを作成する必要があり、これが性能低下の原因となります。
現代のコンパイラは高度な最適化機能を持ち、単純なケースでは前置と後置の違いを自動的に最適化することがあります。しかし、複雑な式や関数呼び出しが含まれる場合、コンパイラの最適化が効かない場合もあります。コンパイラ最適化技術解説書では、このような最適化の仕組みについて詳しく説明されています。
マルチスレッド環境でのインクリメント演算には特別な注意が必要です。複数のスレッドが同じ変数に対して同時にインクリメント演算を実行すると、競合状態(レースコンディション)が発生し、予期しない結果を招く可能性があります。このような場合は、アトミック操作ライブラリや並行プログラミング技術書を参考にして、適切な同期メカニズムを実装する必要があります。
プロファイリングツールを使用することで、インクリメント演算の性能影響を定量的に測定できます。性能プロファイリングツールを活用することで、ボトルネックの特定と最適化の効果測定が可能になります。
ループ構造での活用パターン
インクリメント演算は、様々なループ構造において中心的な役割を果たします。従来のforループから現代的な範囲ベースforループまで、インクリメント演算の使用方法はプログラミングパラダイムの進化とともに変化してきました。
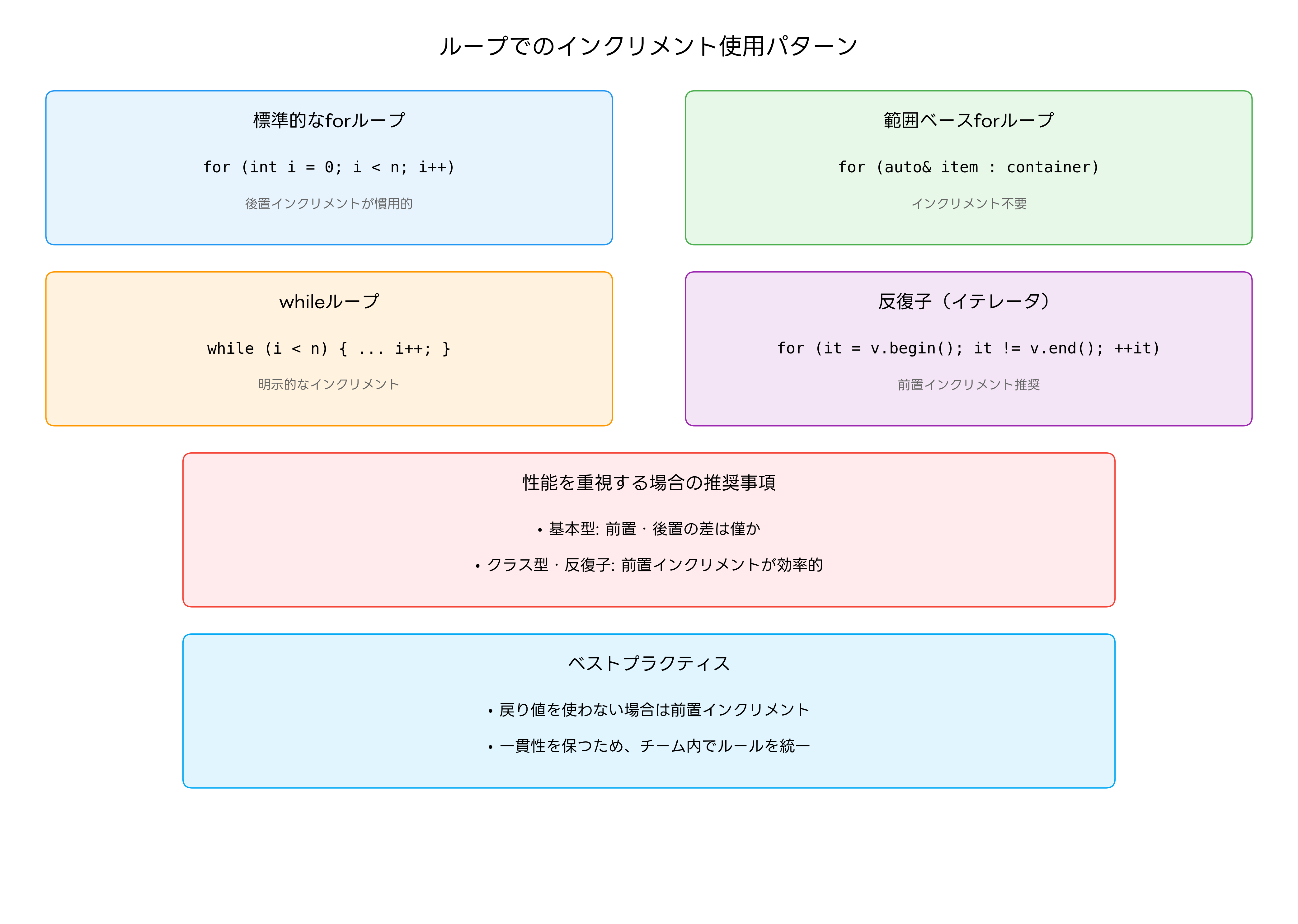
最も一般的なforループでは、ループカウンタとしてインクリメント演算を使用します。慣習的には後置インクリメント(i++)が使用されることが多いですが、戻り値を使用しない場合は前置インクリメント(++i)の方が理論的には効率的です。ただし、基本データ型に対しては実用上の性能差はほとんどありません。
STL(Standard Template Library)の反復子を使用する場合、前置インクリメントが推奨されます。これは、複雑な反復子クラスでは後置インクリメントが一時オブジェクトの生成を伴うためです。STL解説書には、効率的な反復子の使用方法が詳しく説明されています。
範囲ベースforループ(for-each)の普及により、明示的なインクリメント演算の必要性は減少していますが、特定の用途では依然として重要です。例えば、配列のインデックスを操作したり、複数の配列を同時に処理したりする場合には、従来のforループとインクリメント演算が有効です。
ループの最適化において、コンパイラはインクリメント演算を様々な方法で最適化します。ループアンローリング、ベクトル化、並列化などの最適化技術により、単純なインクリメント演算が高度に最適化されたコードに変換されます。コンパイラ理論と実装では、これらの最適化技術について詳細に解説されています。
マルチスレッド環境での安全なインクリメント
マルチスレッド環境では、単純なインクリメント演算でさえ複雑な問題を引き起こす可能性があります。複数のスレッドが同じ変数に対して同時にインクリメント演算を実行すると、読み取り、増加、書き込みの各操作が他のスレッドの操作と交錯し、データ競合が発生します。
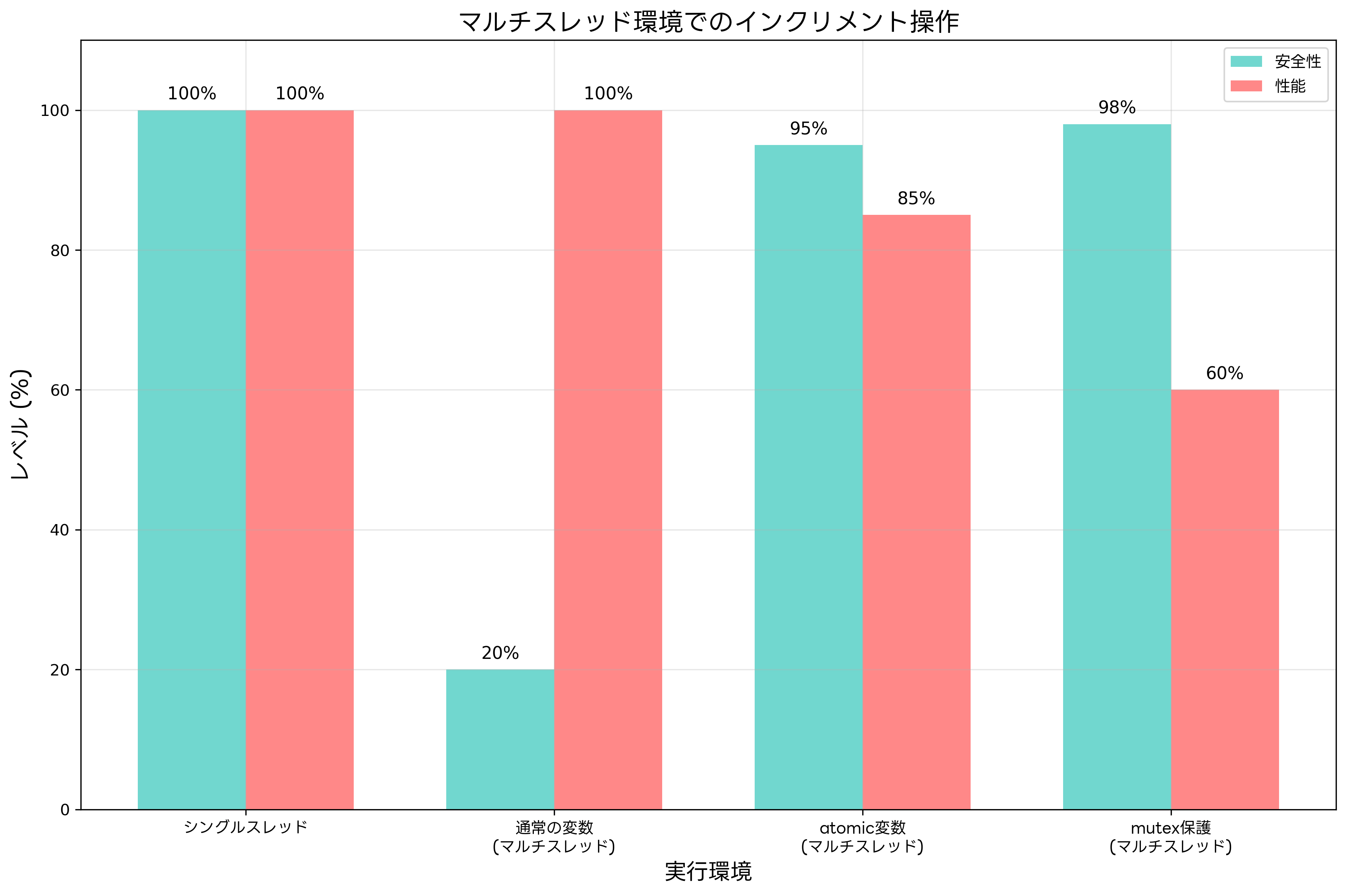
アトミック変数(std::atomic)を使用することで、インクリメント演算を原子的に実行できます。アトミック変数に対するインクリメント演算は、ハードウェアレベルでの原子性が保証され、他のスレッドからの干渉を受けません。ただし、アトミック操作は通常の操作よりもオーバーヘッドが大きいため、性能要件を考慮した設計が必要です。
mutex(相互排他ロック)を使用してインクリメント演算を保護する方法もあります。この場合、インクリメント演算自体は通常の操作ですが、mutexによる排他制御により同時アクセスを防ぎます。しかし、mutexのロック・アンロックのオーバーヘッドは大きく、頻繁なインクリメント操作には適さない場合があります。
並行プログラミング実践ガイドには、様々な同期メカニズムの特徴と適切な使用場面について詳しく説明されています。また、マルチスレッドプログラミング技術書では、実際のコード例とともに安全なインクリメント演算の実装方法が紹介されています。
ロックフリープログラミングにおいては、Compare-And-Swap(CAS)操作を使用してインクリメント演算を実装することがあります。この手法は高い性能を実現できますが、実装の複雑さとデバッグの困難さが課題となります。ロックフリープログラミング解説書では、これらの高度な技術について詳細に説明されています。
演算子オーバーロードによる拡張
C++やC#などのオブジェクト指向言語では、インクリメント演算子をオーバーロードして、カスタムクラスに対する独自のインクリメント動作を定義できます。これにより、ユーザー定義型に対しても直感的なインクリメント操作を提供できます。

前置インクリメント演算子のオーバーロードでは、オブジェクト自身への参照を返すのが一般的です。これにより、連続したインクリメント演算(++++i)や代入文での使用が可能になります。実装においては、オブジェクトの状態を変更した後、*thisを返します。
後置インクリメント演算子のオーバーロードは、前置インクリメントよりも複雑です。元のオブジェクトの状態を一時的に保存し、オブジェクトをインクリメントした後、保存した元の状態を返す必要があります。このため、一時オブジェクトの生成が必要となり、性能面でのオーバーヘッドが生じます。
演算子オーバーロードの実装においては、例外安全性を考慮することが重要です。インクリメント操作中に例外が発生した場合、オブジェクトの状態が不整合にならないよう、適切な例外処理を実装する必要があります。例外安全プログラミング技法では、このような設計上の考慮事項について詳しく説明されています。
カスタムイテレータクラスでは、インクリメント演算子のオーバーロードが特に重要です。STLアルゴリズムとの互換性を保つために、適切なインクリメント動作を実装する必要があります。STLアルゴリズム実装ガイドには、効率的なイテレータの設計方法が詳しく説明されています。
アセンブリレベルでの実装理解
インクリメント演算のアセンブリレベルでの実装を理解することで、性能特性やハードウェア依存の動作を深く理解できます。現代のプロセッサでは、インクリメント演算に特化した命令が提供されており、効率的な実行が可能です。
x86アーキテクチャでは、INC命令により直接的なインクリメント操作が可能です。この命令は、メモリやレジスタの値を直接1増加させることができ、通常のADD命令よりも高速に実行されます。ただし、フラグレジスタへの影響が異なるため、条件分岐と組み合わせる場合は注意が必要です。
RISC系のプロセッサでは、専用のインクリメント命令がない場合もあり、ADD命令で即値1を加算することでインクリメント演算を実現します。この場合でも、パイプライン処理や分岐予測により高い性能を実現できます。コンピュータアーキテクチャ解説書では、様々なプロセッサアーキテクチャでの演算実装について詳しく説明されています。
コンパイラの最適化により、高級言語でのインクリメント演算は様々なアセンブリコードに変換されます。ループアンローリング、命令並列化、レジスタ割り当て最適化などにより、単純なインクリメント演算が高度に最適化されたコードになります。コンパイラ最適化詳解では、これらの最適化技術について実例とともに説明されています。
デバッグ時には、アセンブリレベルでのインクリメント演算の動作を確認することが有効です。アセンブリ言語プログラミング入門を参考にすることで、低レベルでの動作理解が深まります。
応用情報技術者試験での出題傾向
応用情報技術者試験においては、インクリメント演算に関する問題が様々な形で出題されています。基本的な動作理解から性能特性、アルゴリズムでの応用まで、幅広い知識が問われます。
午前問題では、前置・後置インクリメントの動作の違い、式の評価順序、ループでの使用方法などが頻繁に出題されます。特に、複雑な式の中でインクリメント演算が使用された場合の最終的な変数の値を求める問題が多く見られます。
午後問題では、アルゴリズムの効率化や最適化の文脈でインクリメント演算が扱われることがあります。例えば、ソートアルゴリズムや探索アルゴリズムにおけるカウンタ変数の管理、配列インデックスの操作などが問題として出題されます。
試験対策としては、応用情報技術者試験対策問題集で基本的な問題パターンを習得し、プログラミング理論解説書で理論的な背景を理解することが効果的です。
実際のプログラミング経験がある場合は、様々なプログラミング言語でのインクリメント演算の実装を比較検討することで、理解が深まります。多言語プログラミング比較書籍では、言語固有の特徴について詳しく説明されています。
実際の開発現場での活用事例
実際の開発現場では、インクリメント演算は様々な場面で活用されています。Webアプリケーション開発では、ページネーション機能やカウンタ機能の実装において、インクリメント演算が重要な役割を果たします。
データベースシステムでは、主キーの自動採番やシーケンス管理において、アトミックなインクリメント操作が必要です。MySQLのAUTO_INCREMENTやPostgreSQLのSERIALなど、データベース固有のインクリメント機能を理解することが重要です。データベース設計実践ガイドには、これらの機能について詳しく説明されています。
ゲーム開発においては、フレームカウンタ、スコア管理、アニメーション制御など、様々な場面でインクリメント演算が使用されます。リアルタイム性が要求されるゲーム開発では、インクリメント演算の性能特性を理解することが特に重要です。ゲームプログラミング技術書では、効率的なカウンタ実装について解説されています。
組み込みシステム開発では、メモリ制約やリアルタイム制約の中で効率的なインクリメント演算を実装する必要があります。割り込み処理の中でカウンタを更新する場合は、アトミック性を保証するための特別な配慮が必要です。組み込みシステムプログラミング入門では、これらの制約下での効率的なプログラミング技法について説明されています。
セキュリティ面での考慮事項
インクリメント演算は単純な操作に見えますが、セキュリティの観点から重要な考慮事項があります。整数オーバーフローは、インクリメント演算で最も注意すべき問題の一つです。変数が最大値に達した状態でインクリメント演算を実行すると、値が最小値に戻る(オーバーフロー)現象が発生します。
このようなオーバーフローは、バッファオーバーフロー攻撃やサービス拒否攻撃の原因となる可能性があります。例えば、配列のインデックスとして使用されるカウンタ変数がオーバーフローすると、予期しないメモリ領域へのアクセスが発生し、セキュリティホールとなる可能性があります。
セキュアプログラミングにおいては、インクリメント演算の前に境界値チェックを実装することが重要です。また、符号付き整数と符号なし整数の混在使用による予期しない動作を避けるため、適切なデータ型の選択が必要です。セキュアプログラミング技法では、このような脆弱性の回避方法について詳しく説明されています。
静的解析ツールを使用することで、インクリメント演算に関連する潜在的な問題を早期に発見できます。静的解析ツール活用ガイドでは、効果的な解析ツールの使用方法について説明されています。
最新技術動向とインクリメント演算
現代のプログラミング環境では、インクリメント演算を取り巻く技術も進化しています。関数型プログラミングパラダイムでは、可変状態を避ける傾向があり、従来のインクリメント演算に代わる新しいアプローチが提案されています。
並列処理フレームワークでは、分散環境でのカウンタ管理が重要な課題となっています。Apache SparkやHadoopなどのビッグデータ処理フレームワークでは、効率的なカウンタ実装により処理性能が大きく左右されます。ビッグデータ処理技術解説書では、分散環境でのカウンタ実装について詳しく説明されています。
機械学習フレームワークでは、勾配計算やイテレーション管理において、高精度で効率的なカウンタ実装が求められます。TensorFlowやPyTorchなどのフレームワークでは、GPU上での並列インクリメント操作が重要な技術要素となっています。機械学習システム設計書では、このような最新の実装技術について解説されています。
クラウドコンピューティング環境では、マイクロサービスアーキテクチャにおけるカウンタの一貫性管理が課題となっています。分散データベースでのインクリメント演算は、CAP定理の制約の中で適切なトレードオフを見つける必要があります。分散システム設計実践では、これらの現代的な課題について詳しく説明されています。
まとめ
インクリメント演算は、プログラミングの基本的な演算でありながら、その奥深さは計り知れません。前置と後置の違い、性能特性、マルチスレッド環境での安全性、演算子オーバーロードによる拡張など、様々な技術的側面を理解することで、より効率的で安全なプログラムを作成できます。
応用情報技術者試験の観点からは、基本的な動作理解に加えて、実際の開発現場での活用方法やセキュリティ面での考慮事項まで、幅広い知識が求められます。継続的な学習と実践を通じて、インクリメント演算に関する深い理解を身につけることが重要です。
現代のソフトウェア開発では、インクリメント演算を取り巻く技術環境も急速に進化しています。並列処理、分散システム、機械学習など、新しい技術領域においても、基本的なインクリメント演算の理解は重要な基盤となります。今後も継続的に技術動向を追い、実践的な知識を蓄積していくことで、高品質なソフトウェア開発に貢献できるでしょう。