
プログラミングにおいてイテレーターは、コンテナ(配列、リスト、セットなど)の要素に順次アクセスするための統一された仕組みです。応用情報技術者試験においても重要なトピックであり、現代のプログラミングにおける効率的なデータ処理の基盤となっています。本記事では、イテレーターの基本概念から高度な実装まで、包括的に解説していきます。

イテレーターパターンは、GoFデザインパターンの一つとして広く知られており、コレクションの内部構造を公開することなく、その要素に順次アクセスする方法を提供します。この設計により、異なる種類のコンテナに対して統一されたインターフェースでアクセスでき、アルゴリズムの汎用性が大幅に向上します。
イテレーターの基本概念と動作原理
イテレーターは、コンテナ内の現在位置を表すオブジェクトであり、要素への参照、次の要素への移動、終端の判定などの基本操作を提供します。これらの操作は言語やライブラリによって異なる構文で実装されますが、基本的な概念は共通しています。
C++のSTL(Standard Template Library)におけるイテレーターは、ポインタに似た動作をする軽量なオブジェクトです。例えば、vector コンテナのイテレーターは内部的にはポインタとして実装され、効率的なメモリアクセスを実現しています。一方、list コンテナのイテレーターはノードポインタを保持し、リンクを辿って次の要素にアクセスします。
STL解説書を参考にすることで、具体的な実装方法と最適化技術について深く理解できます。また、アルゴリズムとデータ構造入門書では、イテレーターパターンの理論的背景について詳しく説明されています。
イテレーターの利点は、コンテナの内部実装に依存しない統一されたアクセス方法を提供することです。配列であってもリンクリストであっても、同じインターフェースでアクセスできるため、アルゴリズムの再利用性が大幅に向上します。この特性により、STLのような汎用ライブラリが実現され、効率的なソフトウェア開発が可能になっています。
イテレーターの種類と階層構造
イテレーターには、その機能と性能特性に応じて複数の種類があります。C++のSTLでは、イテレーターを5つのカテゴリに分類しており、それぞれが異なる操作セットと性能保証を提供します。
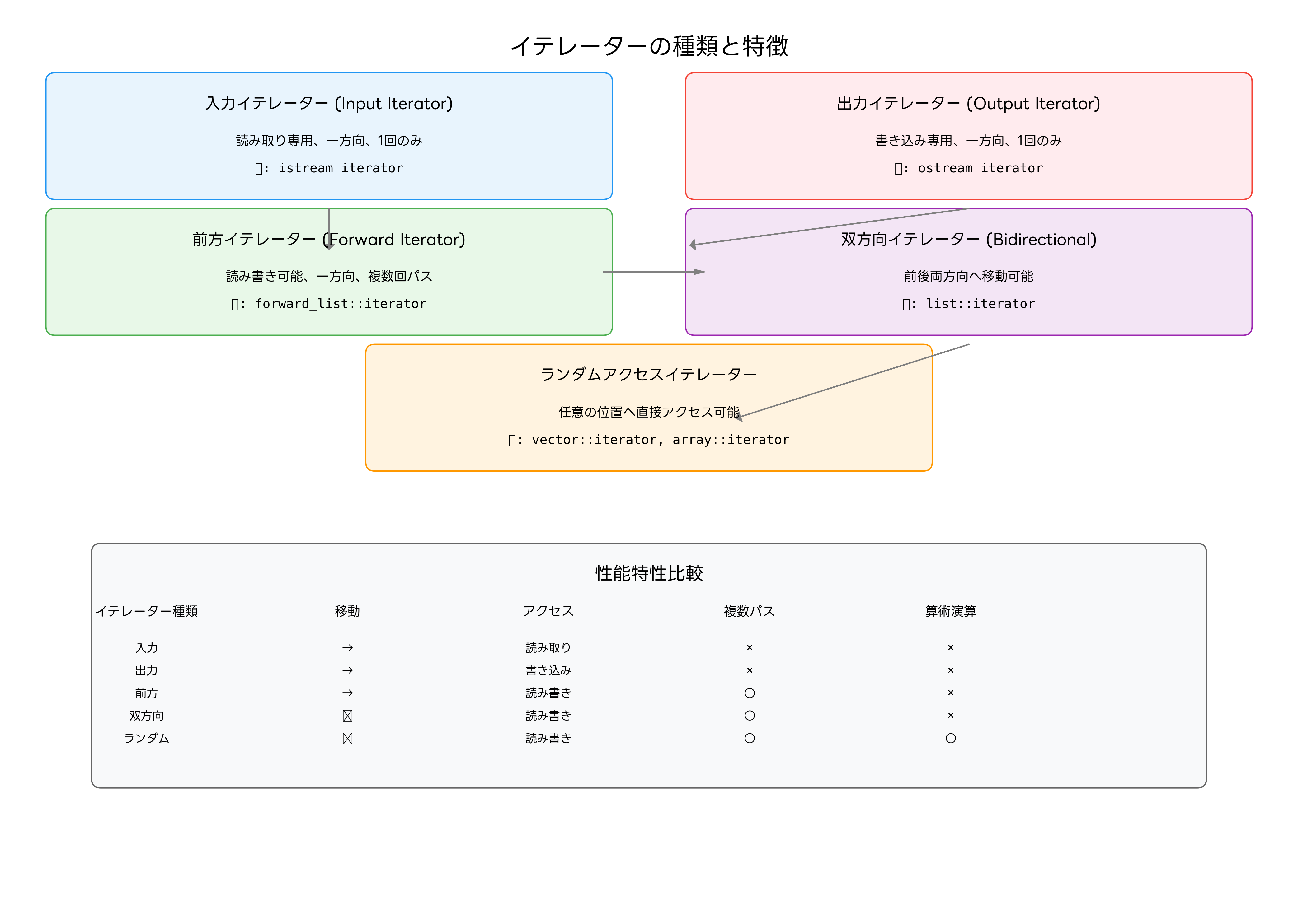
入力イテレーター(Input Iterator)は最も基本的な形式で、要素の読み取りと前方への移動のみをサポートします。このイテレーターは一度しか走査できず、ファイルやネットワークストリームからのデータ読み取りに適しています。istream_iteratorはこのカテゴリの代表例です。
出力イテレーター(Output Iterator)は書き込み専用のイテレーターで、要素への値の代入と前方への移動をサポートします。ostream_iteratorやback_insert_iteratorなどがこのカテゴリに属し、結果の出力や容器の拡張に使用されます。
前方イテレーター(Forward Iterator)は、読み書き両方が可能で、複数回の走査をサポートします。forward_listのイテレーターがこの例で、単方向リンクリストの特性を反映したインターフェースを提供します。データ構造アルゴリズム実装ガイドでは、このような特殊なデータ構造の実装について詳しく説明されています。
双方向イテレーター(Bidirectional Iterator)は前後両方向への移動が可能で、listやsetのイテレーターが該当します。逆順走査や複雑な位置操作が必要なアルゴリズムで威力を発揮します。
ランダムアクセスイテレーター(Random Access Iterator)は最も機能豊富で、任意の位置への直接アクセス、算術演算、比較演算をサポートします。vectorやarrayのイテレーターがこのカテゴリに属し、ソートアルゴリズムなどの高性能なアルゴリズムで使用されます。
実際の使用パターンとベストプラクティス
イテレーターの使用パターンは、プログラミング言語の進化とともに変化してきました。従来の明示的なイテレーターループから、現代的な範囲ベースforループまで、様々なアプローチが存在します。

従来のイテレーターループでは、begin()とend()を明示的に使用してコンテナを走査します。この方法は全てのコンテナタイプで使用でき、細かい制御が可能ですが、記述が冗長になる傾向があります。特に複雑な条件処理や早期終了が必要な場合には、この形式が適しています。
C++11で導入された範囲ベースforループは、内部的にイテレーターを使用しながらも、より簡潔で読みやすい構文を提供します。この構文は、単純な全要素走査において推奨される方法です。[Modern C++プログラミング入門](https://www.amazon.co.jp/s?k=Modern C++プログラミング入門&tag=amazon-product-items-22)では、このような現代的な構文について詳しく解説されています。
STLアルゴリズムとの組み合わせでは、イテレーターが真価を発揮します。find、transform、sort、accumulateなどのアルゴリズムは、イテレーターペアを受け取ることで、任意のコンテナに対して動作します。この設計により、高度に最適化されたアルゴリズムを様々なデータ構造で再利用できます。
カスタムイテレーターの実装では、独自のデータ構造に対してもSTLアルゴリズムを適用できます。例えば、ツリー構造のイン・オーダー走査やグラフの幅優先探索をイテレーターとして実装することで、標準アルゴリズムとシームレスに統合できます。[Advanced C++技法解説書](https://www.amazon.co.jp/s?k=Advanced C++技法解説書&tag=amazon-product-items-22)では、このような高度な実装技術について説明されています。
イテレーターの内部実装と性能特性
イテレーターの内部実装は、コンテナの種類によって大きく異なります。この違いを理解することで、適切なコンテナの選択と効率的な使用法を身につけることができます。
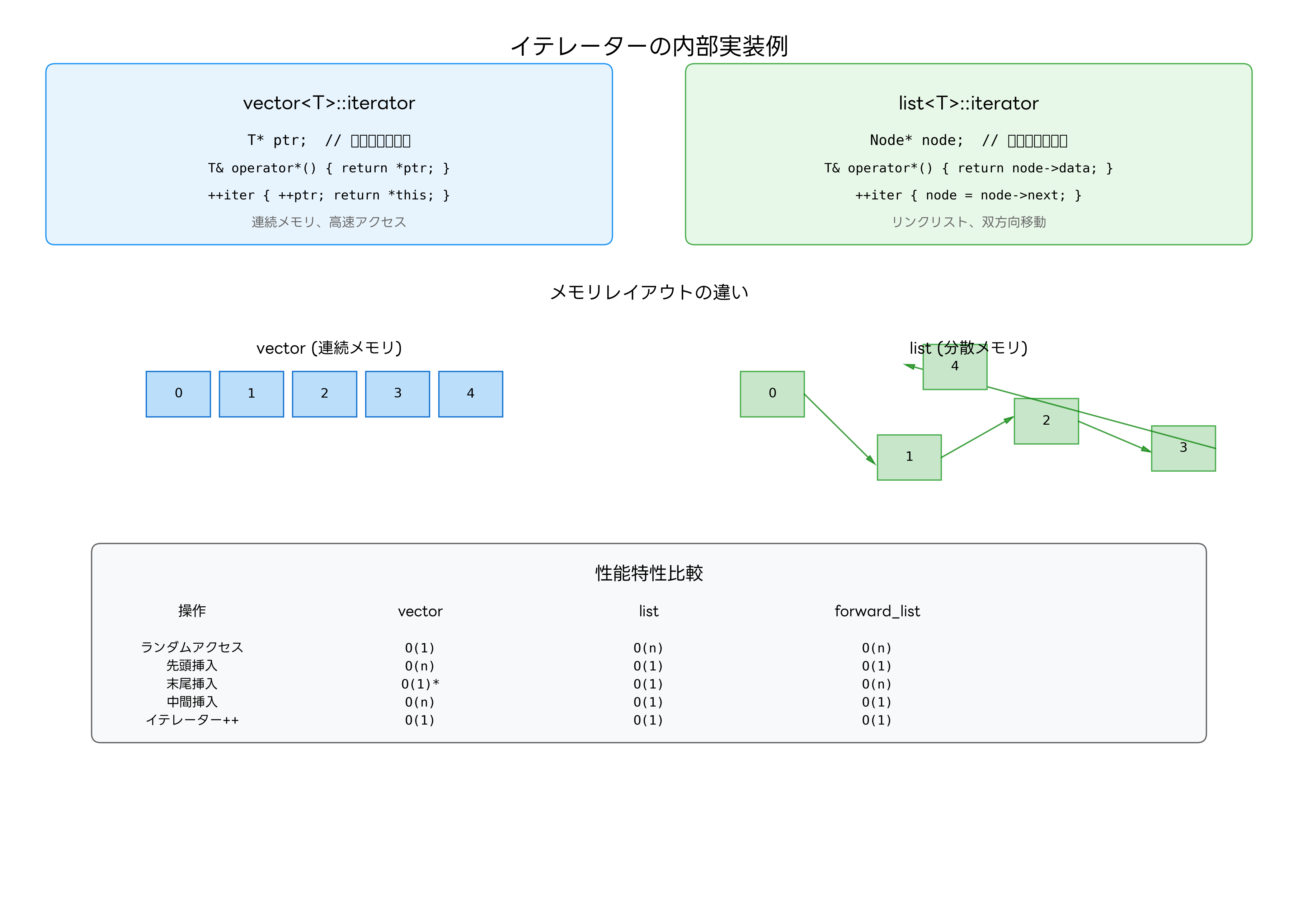
vectorのイテレーターは、最もシンプルな実装の一つです。内部的にはポインタとして実装され、インクリメント操作は単純なポインタ算術で実現されます。この実装により、ランダムアクセスイテレーターの全機能を効率的に提供でき、メモリ局所性の恩恵も受けられます。
listのイテレーターは、ノードポインタを保持する形で実装されます。前進操作はnode->nextを辿り、後退操作はnode->prevを辿ることで実現されます。この実装では、要素の挿入や削除がO(1)で実行できる一方、ランダムアクセスはO(n)の時間計算量となります。
forward_listのイテレーターは、メモリ効率を重視した設計となっています。後方ポインタを持たないため、メモリ使用量を削減できますが、双方向移動はサポートされません。この制約により、特定のアルゴリズムでは使用できない場合があります。
イテレーターの性能特性を理解することで、適切なコンテナ選択ができます。[High Performance C++プログラミング](https://www.amazon.co.jp/s?k=High Performance C++プログラミング&tag=amazon-product-items-22)では、このような性能観点からの設計について詳しく説明されています。また、メモリ効率プログラミング技法では、メモリアクセスパターンの最適化について解説されています。
STLアルゴリズムとイテレーターの関係
STLアルゴリズムは、イテレーターを介してコンテナにアクセスする設計となっており、この組み合わせにより強力な汎用ライブラリが実現されています。各アルゴリズムは、必要なイテレーターのカテゴリを要求し、コンパイル時にチェックされます。

検索アルゴリズムの多くは入力イテレーターのみを要求し、最小限の機能で動作します。findアルゴリズムは線形探索を行うため、前方向への移動と要素の読み取りができれば十分です。一方、binary_searchはランダムアクセスイテレーターを要求し、効率的な二分探索を実現します。
変更アルゴリズムは、要素の値を変更するため、より高度なイテレーター機能を必要とする場合があります。transformアルゴリズムは、入力と出力に異なるイテレーターカテゴリを使用でき、柔軟なデータ変換パイプラインを構築できます。
ソートアルゴリズムは、要素の比較と交換を効率的に行うため、ランダムアクセスイテレーターを必要とします。stable_sortやpartial_sortなどの特殊なソートアルゴリズムも同様の要求を持ちます。ソートアルゴリズム詳解では、これらのアルゴリズムの内部動作について詳しく説明されています。
数値アルゴリズムは、数学的計算に特化したものが多く、accumulateやinner_productなどが代表例です。これらのアルゴリズムを効果的に使用することで、数値計算処理を効率化できます。数値計算プログラミング入門では、このような専門的な計算手法について解説されています。
カスタムイテレーターの設計と実装
独自のデータ構造に対してイテレーターを実装することで、STLアルゴリズムとの統合が可能になります。適切な設計により、標準ライブラリの恩恵を最大限に活用できます。
カスタムイテレーターの実装では、必要な演算子のオーバーロードと、適切なiterator_traitsの定義が重要です。これらの設定により、コンパイラはイテレーターのカテゴリを判定し、最適なアルゴリズムを選択できます。
例えば、二分木のイン・オーダー走査をイテレーターとして実装する場合、スタックを使用して走査状態を管理します。この実装により、木構造をあたかも線形コンテナのように扱えます。データ構造とアルゴリズム実装では、このような高度な実装技術について詳しく説明されています。
フィルタリングイテレーターは、条件を満たす要素のみを走査するイテレーターで、述語関数と組み合わせて柔軟なデータ処理を実現できます。このパターンは、大きなデータセットから特定の条件を満たす要素を効率的に抽出する場合に有効です。
イテレーターアダプタは、既存のイテレーターに新しい機能を追加する設計パターンです。reverse_iteratorやinsert_iteratorなどがSTLで提供されており、これらの実装を参考にしてカスタムアダプタを作成できます。[Design Patterns実装ガイド](https://www.amazon.co.jp/s?k=Design Patterns実装ガイド&tag=amazon-product-items-22)では、このような設計パターンの活用方法について説明されています。
並列処理とイテレーター
現代のマルチコア環境では、イテレーターを並列処理と組み合わせることで、大幅な性能向上が期待できます。C++17で導入された並列アルゴリズムは、イテレーターベースの設計を活用して並列化を実現しています。
並列実行ポリシーを指定することで、多くのSTLアルゴリズムが自動的に並列化されます。std::execution::parやstd::execution::par_unseqなどのポリシーにより、実行方法を制御できます。ただし、並列化の効果はデータサイズやアルゴリズムの特性に依存するため、適切なベンチマークが必要です。
並列プログラミング実践ガイドでは、効果的な並列化手法について詳しく説明されています。また、マルチスレッドプログラミング技術書では、スレッドセーフなデータ構造の設計について解説されています。
分散処理環境では、イテレーターパターンをネットワーク越しに拡張することで、大規模データ処理が可能になります。Apache SparkやHadoopなどのフレームワークでは、このような分散イテレーターの概念が活用されています。
関数型プログラミングとイテレーター
関数型プログラミングパラダイムでは、イテレーターに相当する概念として、遅延評価や無限シーケンスがあります。これらの概念を組み合わせることで、メモリ効率の良いデータ処理パイプラインを構築できます。
C++20で導入されたRangesライブラリは、関数型プログラミングの考え方をイテレーターベースの設計に統合したものです。viewやactionの概念により、宣言的なデータ処理が可能になります。関数型プログラミング入門では、このような新しいプログラミングパラダイムについて説明されています。
遅延評価イテレーターは、必要になるまで計算を延期することで、メモリ使用量を削減し、パフォーマンスを向上させます。無限シーケンスを扱う場合や、計算コストの高い変換処理において特に有効です。
パイプライン処理では、複数の変換操作を連鎖させて効率的なデータ処理を実現します。ストリーム処理プログラミングでは、このような処理パターンについて詳しく解説されています。
応用情報技術者試験での出題傾向
応用情報技術者試験においては、イテレーターに関する問題が様々な形で出題されています。基本的な概念理解から実装技術、性能特性まで、幅広い知識が問われます。
午前問題では、イテレーターの種類と特徴、STLアルゴリズムとの関係、時間計算量などが頻繁に出題されます。特に、異なるコンテナタイプでの性能差や、適切なイテレーターカテゴリの選択に関する問題が多く見られます。
午後問題では、具体的なアルゴリズムの実装やデータ構造の設計において、イテレーターの活用が問われることがあります。効率的なデータ処理やメモリ使用量の最適化などの観点から、適切な実装方法を選択する能力が評価されます。
試験対策としては、応用情報技術者試験対策問題集で基本的な問題パターンを習得し、プログラミング理論解説書で理論的な背景を理解することが効果的です。
実際のプログラミング経験を通じて、様々なイテレーターの実装と使用方法を理解することも重要です。実践的プログラミング演習書では、具体的なコード例とともに実装技術が説明されています。
セキュリティ面での考慮事項
イテレーターの使用においても、セキュリティ面での注意が必要です。不正なイテレーター操作は、バッファオーバーフローやメモリ破壊の原因となる可能性があります。
イテレーターの有効性検証は、安全なプログラムを作成する上で重要です。無効なイテレーターの使用は未定義動作を引き起こし、セキュリティホールとなる可能性があります。begin()とend()の適切な使用により、このような問題を回避できます。
範囲チェック付きイテレーターを使用することで、境界外アクセスを防止できます。デバッグビルドでは、多くの実装が自動的に範囲チェックを行いますが、リリースビルドでは性能のために省略される場合があります。
セキュアプログラミング技法では、このような脆弱性の回避方法について詳しく説明されています。また、静的解析ツール活用ガイドでは、自動的な問題検出手法について解説されています。
最新技術動向とイテレーター
現代のプログラミング環境では、イテレーターを取り巻く技術も急速に進化しています。C++20のRangesライブラリ、Rustの所有権システム、Pythonのジェネレータなど、各言語で独自の発展を遂げています。
C++20のRangesライブラリは、イテレーターの概念を大幅に拡張し、より宣言的で安全なプログラミングを可能にします。viewsとactionsの組み合わせにより、効率的なデータ処理パイプラインを構築できます。[Modern C++20入門](https://www.amazon.co.jp/s?k=Modern C++20入門&tag=amazon-product-items-22)では、これらの新機能について詳しく解説されています。
コルーチンとイテレーターの組み合わせにより、非同期データ処理が効率化されています。C++20のコルーチンやPythonのasync/awaitなどが代表例で、I/Oバウンドなタスクでの性能向上が期待できます。
機械学習フレームワークにおいては、大規模データセットの効率的な処理のため、高度なイテレーター実装が使用されています。バッチ処理、データ変換、並列化などの機能を統合したイテレーターにより、学習処理の効率化が実現されています。機械学習システム設計では、このような最新の実装技術について説明されています。
まとめ
イテレーターは、現代のプログラミングにおいて不可欠な概念です。統一されたインターフェースによるコンテナアクセス、STLアルゴリズムとの統合、効率的なメモリ使用など、多くの利点を提供します。応用情報技術者試験の観点からも、理論的理解と実践的応用の両方が重要です。
基本的な概念から高度な実装技術まで、段階的に理解を深めることで、効率的で安全なプログラムを作成できるようになります。また、最新の技術動向を継続的に学習することで、進化し続けるプログラミング環境に対応できます。
イテレーターの理解は、単なる文法知識にとどまらず、設計思想やアーキテクチャパターンの理解につながります。この知識を活用することで、より質の高いソフトウェア開発が可能になり、現代的なプログラミングスキルを身につけることができるでしょう。