現代のデジタル社会において、個人情報の保護とデータ活用の両立は企業にとって重要な課題となっています。仮名化技術は、この課題を解決する有効な手段として注目を集めており、応用情報技術者試験においても頻出の重要なトピックです。2020年に改正された個人情報保護法において、仮名加工情報という新たな概念が導入され、企業のデータ活用の可能性が大きく広がりました。
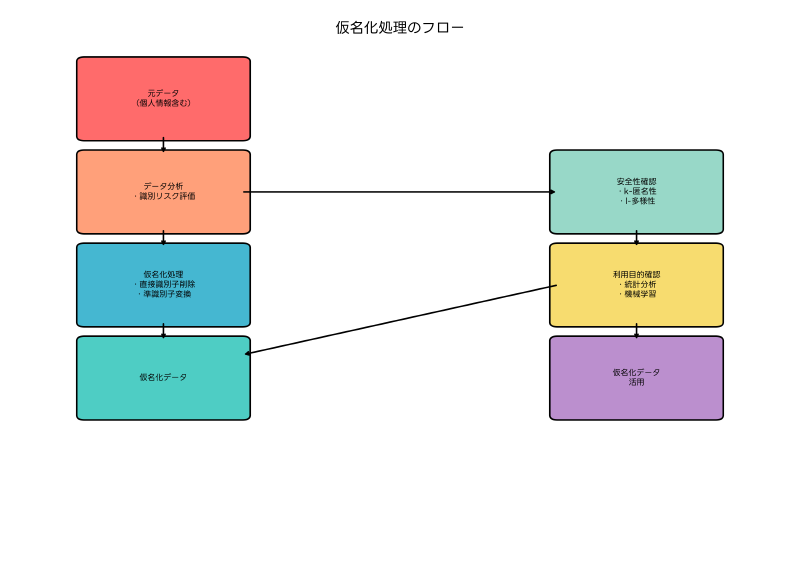
仮名化とは、個人情報に含まれる氏名などの直接的な識別子を削除または変更し、個人を特定することを困難にする処理のことです。完全に個人を特定できなくする匿名化とは異なり、仮名化では適切な追加情報があれば個人の特定が可能であるという特徴があります。これにより、プライバシーを保護しながらも、必要に応じて個人への連絡や追跡調査が可能な状態を維持できます。
仮名化の基本概念と定義
仮名化は「pseudonymization」の日本語訳であり、個人識別子を仮の識別子(pseudonym)に置き換える処理を指します。この技術は、個人のプライバシーを保護しながら、データの分析価値を維持することを目的としています。仮名化処理により、データ内の個人を直接的に識別することは困難になりますが、データの統計的性質や分析に必要な属性情報は保持されます。
仮名化の実装には、様々な技術的手法が用いられます。最も基本的な手法は、氏名や住所などの直接識別子を削除または仮の識別子に置き換えることです。より高度な手法では、年齢の範囲化、地域の大分類化、職業の一般化など、準識別子の粒度を調整することで再識別リスクを低減します。これらの処理を効率的に行うため、データマスキングソフトウェアや個人情報保護ツールが多くの企業で導入されています。
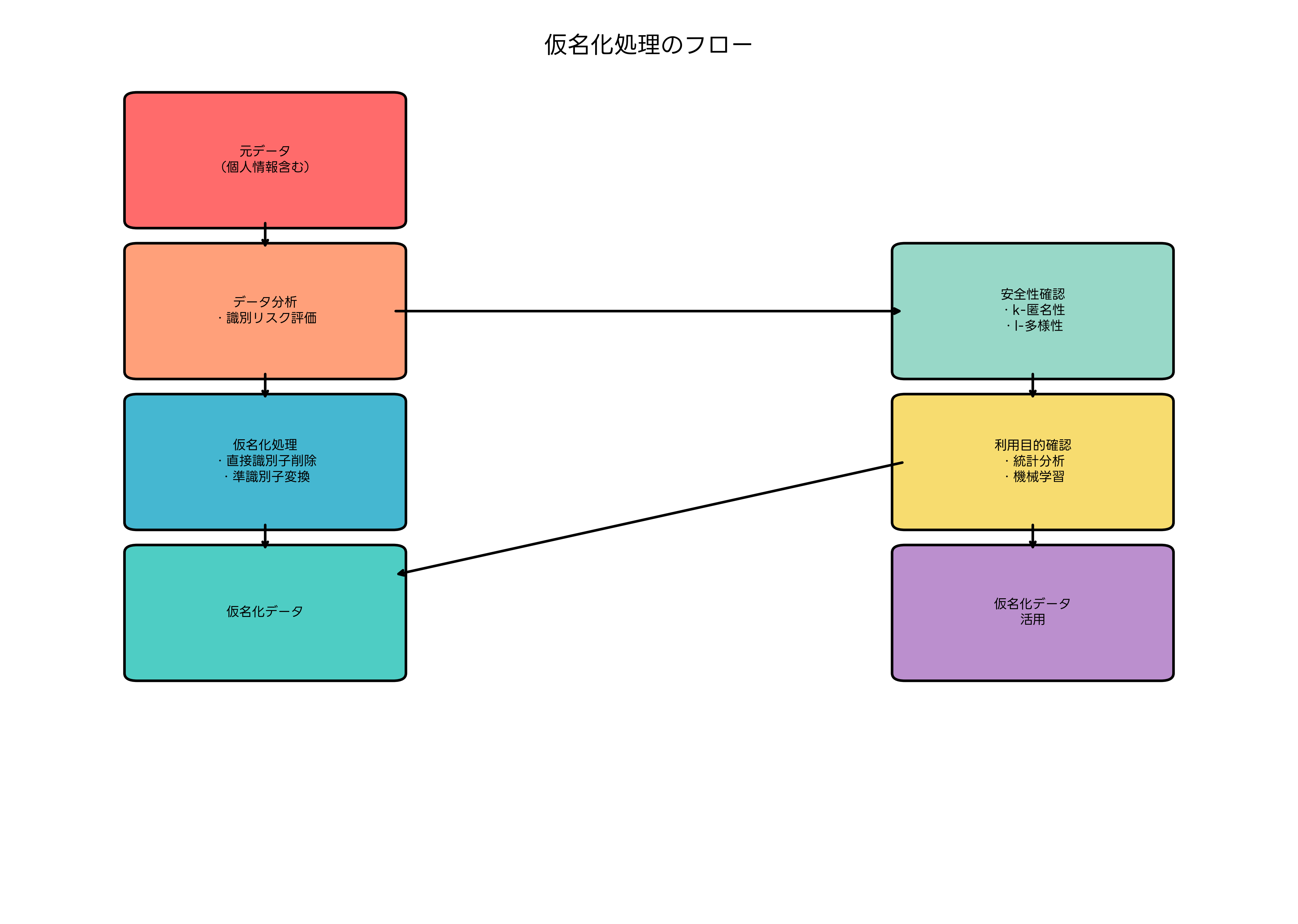
仮名化の品質評価には、プライバシー保護レベルとデータ有用性の両面から検討する必要があります。プライバシー保護レベルは、k-匿名性、l-多様性、t-近似性などの指標により定量的に評価できます。一方、データ有用性は、統計分析の精度、機械学習モデルの性能、ビジネス分析の有効性などにより評価されます。
法的な観点から見ると、仮名化は個人情報保護法において重要な概念となっています。仮名加工情報は、個人情報よりも規制が緩和されており、本人の同意なしに利用目的の変更や第三者提供が可能になる場合があります。ただし、仮名加工情報であっても、適切な安全管理措置を講じる義務があり、個人の権利利益を侵害しないよう配慮が必要です。
k-匿名性と仮名化の技術的基盤
k-匿名性は、仮名化の品質を評価する最も重要な指標の一つです。この概念は、データセット内の任意のレコードが、同じ準識別子を持つ他のk-1個以上のレコードと区別できない状態を指します。例えば、k=5の場合、任意の個人と同じ年齢、性別、居住地域を持つ人が最低でも4人以上存在することを意味します。
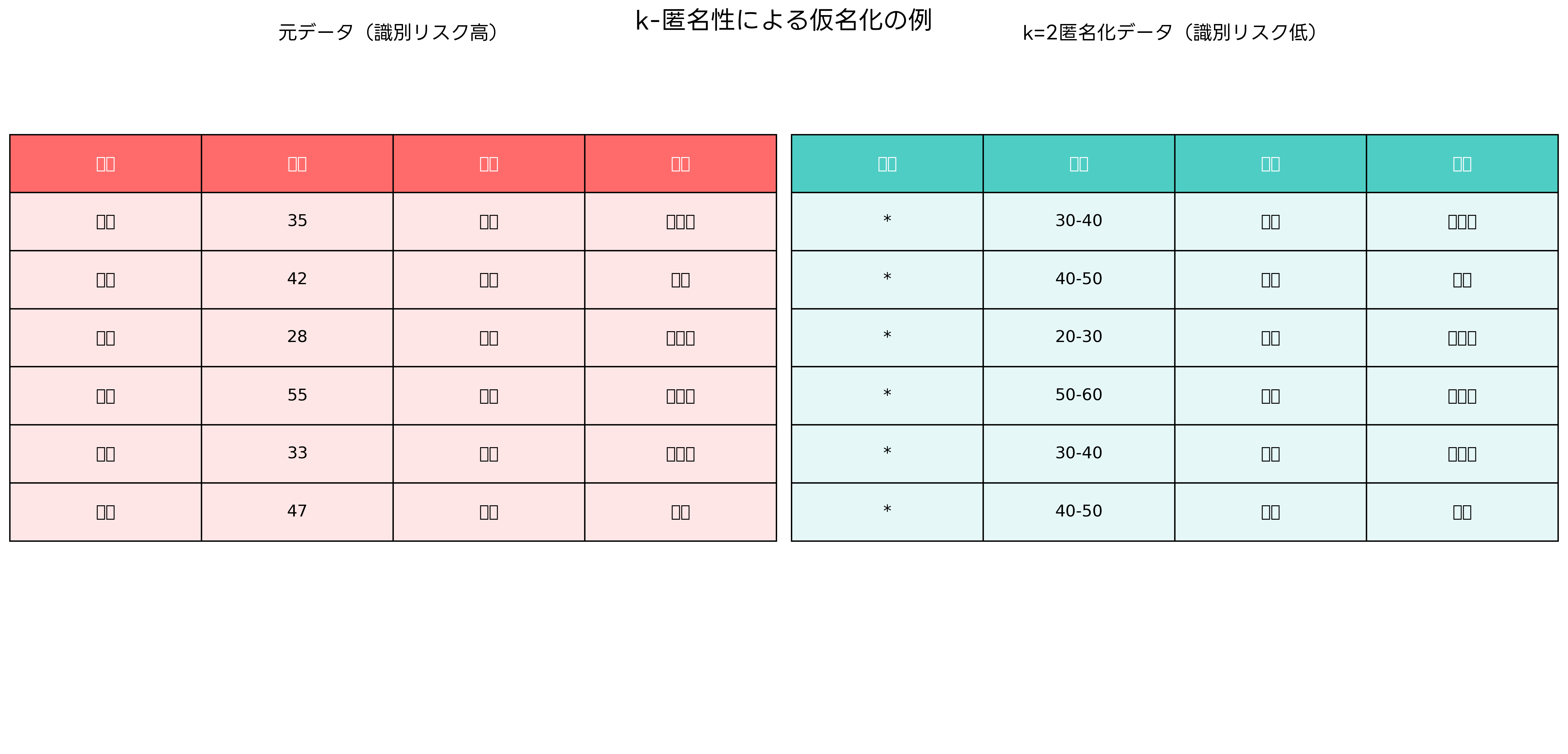
k-匿名性を実現するための主要な技術手法には、抑制(Suppression)と一般化(Generalization)があります。抑制は特定の属性値や行全体を削除する手法であり、一般化は具体的な値をより抽象的な値に置き換える手法です。例えば、「35歳」を「30-40歳」に変換したり、「東京都港区」を「関東地方」に変換したりします。
これらの処理を自動化するため、k-匿名化ソフトウェアやプライバシー保護分析ツールが開発されています。これらのツールは、指定されたk値に基づいて最適な一般化レベルを自動的に決定し、情報損失を最小化しながらプライバシー保護を実現します。
l-多様性は、k-匿名性の制約を補完する概念です。k-匿名性だけでは、同じ準識別子を持つグループ内のセンシティブ属性(疾患名、年収など)がすべて同じ値を持つ場合、個人のセンシティブ情報が推測される可能性があります。l-多様性では、各グループ内のセンシティブ属性が少なくともl個の異なる値を持つことを要求します。
t-近似性は、さらに高度なプライバシー保護を提供する概念です。各グループ内のセンシティブ属性の分布が、全体の分布と類似していることを要求します。これにより、グループメンバーシップからセンシティブ情報を推測することを防ぎます。これらの高度な匿名化技術を実装するため、統計的開示制御ソフトウェアが研究機関や大企業で活用されています。
個人情報保護法における仮名化の位置づけ
2020年の個人情報保護法改正により、仮名加工情報という新たなカテゴリが創設されました。この改正は、EU一般データ保護規則(GDPR)の影響を受けており、個人情報の利活用促進と保護強化の両立を図ることを目的としています。仮名加工情報は、個人情報と匿名加工情報の中間的な位置づけにあり、両者の利点を兼ね備えた制度設計となっています。
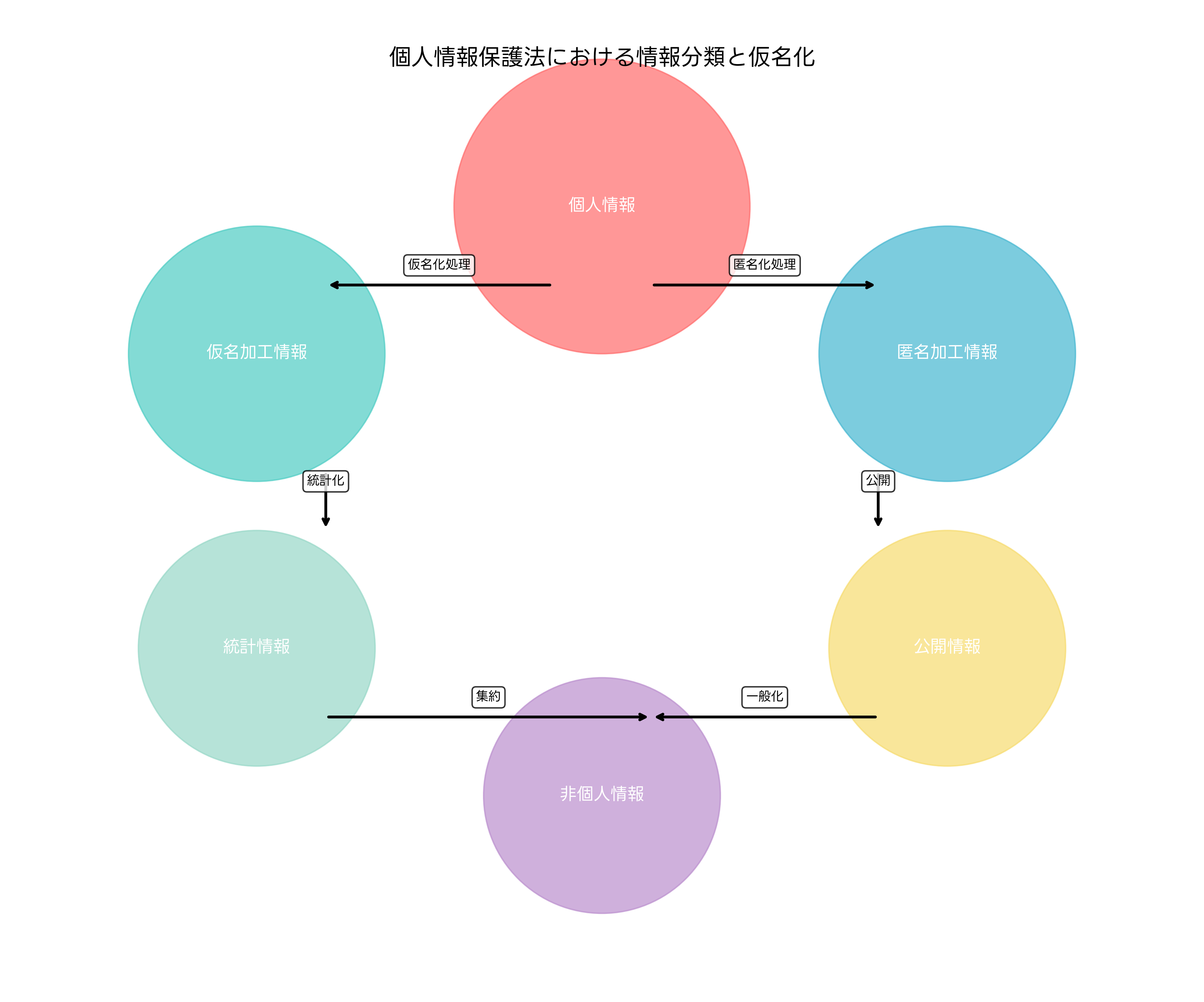
仮名加工情報の作成には、個人情報保護委員会が定める規則に従った適切な加工が必要です。具体的には、個人情報に含まれる氏名、住所、電話番号などの記述を削除し、個人識別符号を削除または他の記述に置き換える必要があります。また、特異な記述や個人を識別することができる記述を削除し、その他の個人情報と照合することができる記述を削除することも求められます。
仮名加工情報の利用には一定の制約があります。仮名加工情報である旨を本人に通知する必要があり、仮名加工情報とその他の情報を照合して元の個人を識別することは禁止されています。また、仮名加工情報を第三者に提供する場合は、原則として本人の同意が必要ですが、法令に基づく場合や人の生命・身体・財産の保護のために必要な場合などの例外があります。
企業が仮名加工情報を適切に管理するためには、個人情報管理システムやデータガバナンスツールの導入が推奨されます。これらのシステムにより、仮名加工情報の作成、管理、利用、削除までのライフサイクル全体を適切に管理できます。
匿名加工情報との違いを理解することも重要です。匿名加工情報は、個人を識別することができず、復元することもできないよう加工された情報であり、個人情報保護法の規制対象外となります。一方、仮名加工情報は、追加情報があれば個人の特定が可能であり、一定の規制を受けます。しかし、匿名加工情報よりも規制が緩和されており、より柔軟な利活用が可能です。
再識別リスクの評価と管理
仮名化されたデータであっても、他のデータと組み合わせることで個人が再識別される可能性があります。再識別リスクの評価と管理は、仮名化技術の実装において最も重要な要素の一つです。再識別攻撃は、レコードリンケージ攻撃、属性リンケージ攻撃、テーブルリンケージ攻撃など、様々な形態で行われる可能性があります。
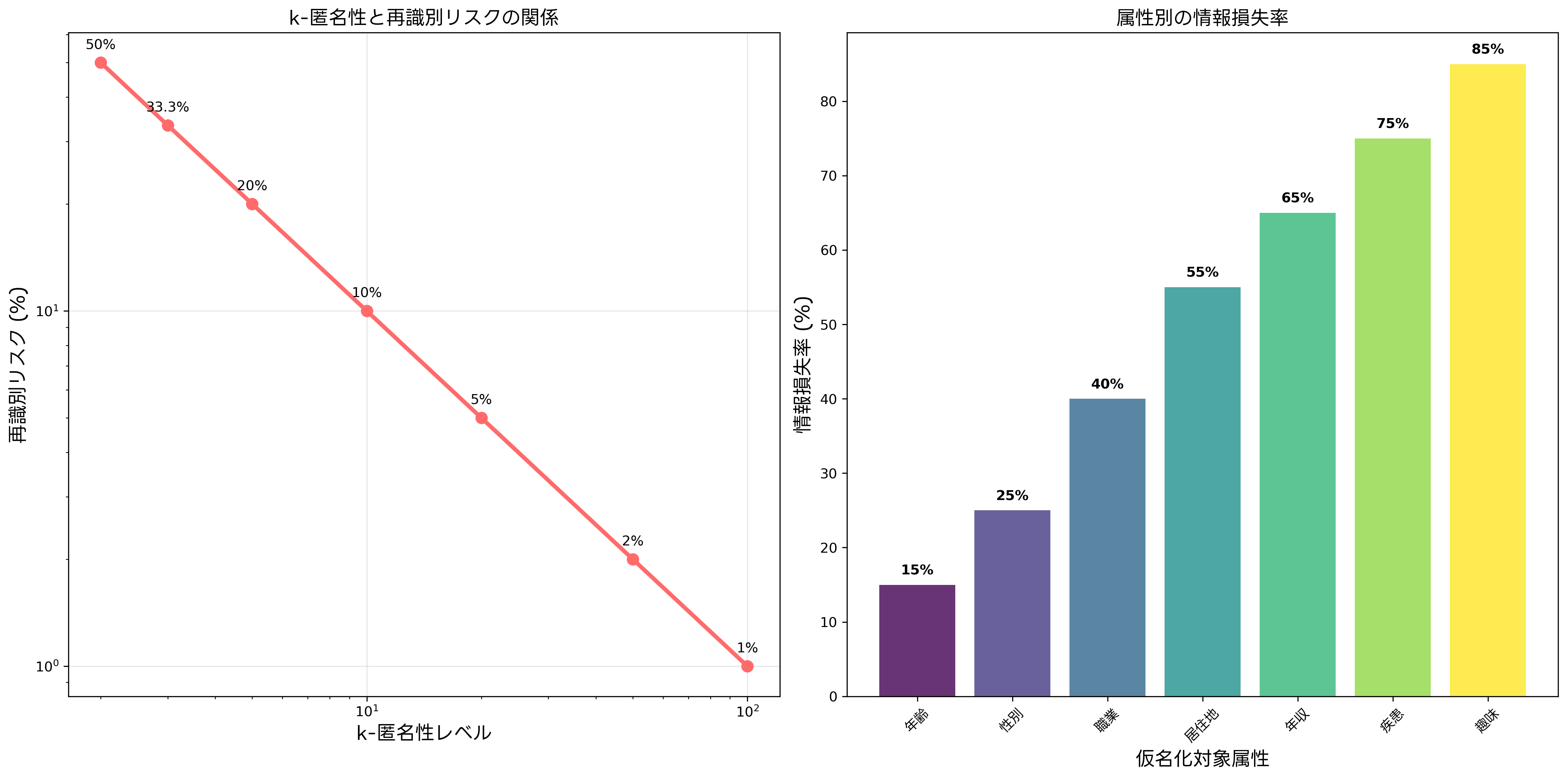
再識別リスクの定量的評価には、統計学的手法が用いられます。最も基本的な指標は、個人が一意に識別される確率ですが、より実用的な評価には、記録者攻撃のリスク、属性推論攻撃のリスク、メンバーシップ推論攻撃のリスクなどを総合的に考慮する必要があります。これらのリスク評価を自動化するため、リスク評価ソフトウェアが開発されており、大規模なデータセットでも効率的にリスク分析を実行できます。
外部データとの照合リスクも重要な考慮事項です。公開されている統計データ、ソーシャルメディアの情報、商用データベースなど、様々な外部データソースとの組み合わせにより、仮名化されたデータから個人が特定される場合があります。このリスクを軽減するため、データ利用環境の制限、アクセス制御の強化、データ使用後の確実な削除などの対策が必要です。
動的な再識別リスクの管理も重要です。時間の経過とともに新たな外部データが利用可能になったり、攻撃手法が高度化したりすることで、当初は安全と考えられていた仮名化データのリスクが高まる場合があります。継続的なリスク監視のため、継続的リスク監視システムを導入し、定期的にリスク評価を更新することが推奨されます。
差分プライバシーは、より厳密なプライバシー保護を提供する理論的枠組みです。この手法では、データセットに個人のデータが含まれているかどうかを推測することを数学的に困難にします。差分プライバシーを実装するための差分プライバシーライブラリやプライバシー保護機械学習ツールが提供されており、高度なプライバシー保護が求められる分野で活用されています。
業界別の仮名化適用事例
仮名化技術は、様々な業界で実用化されており、それぞれの業界特有の要件に応じた実装が行われています。医療分野では、患者の診療記録や臨床試験データの仮名化が重要な課題となっています。医療データは高度にセンシティブな情報を含むため、厳格なプライバシー保護が求められる一方で、医学研究や疫学調査のためにデータの詳細性も必要です。
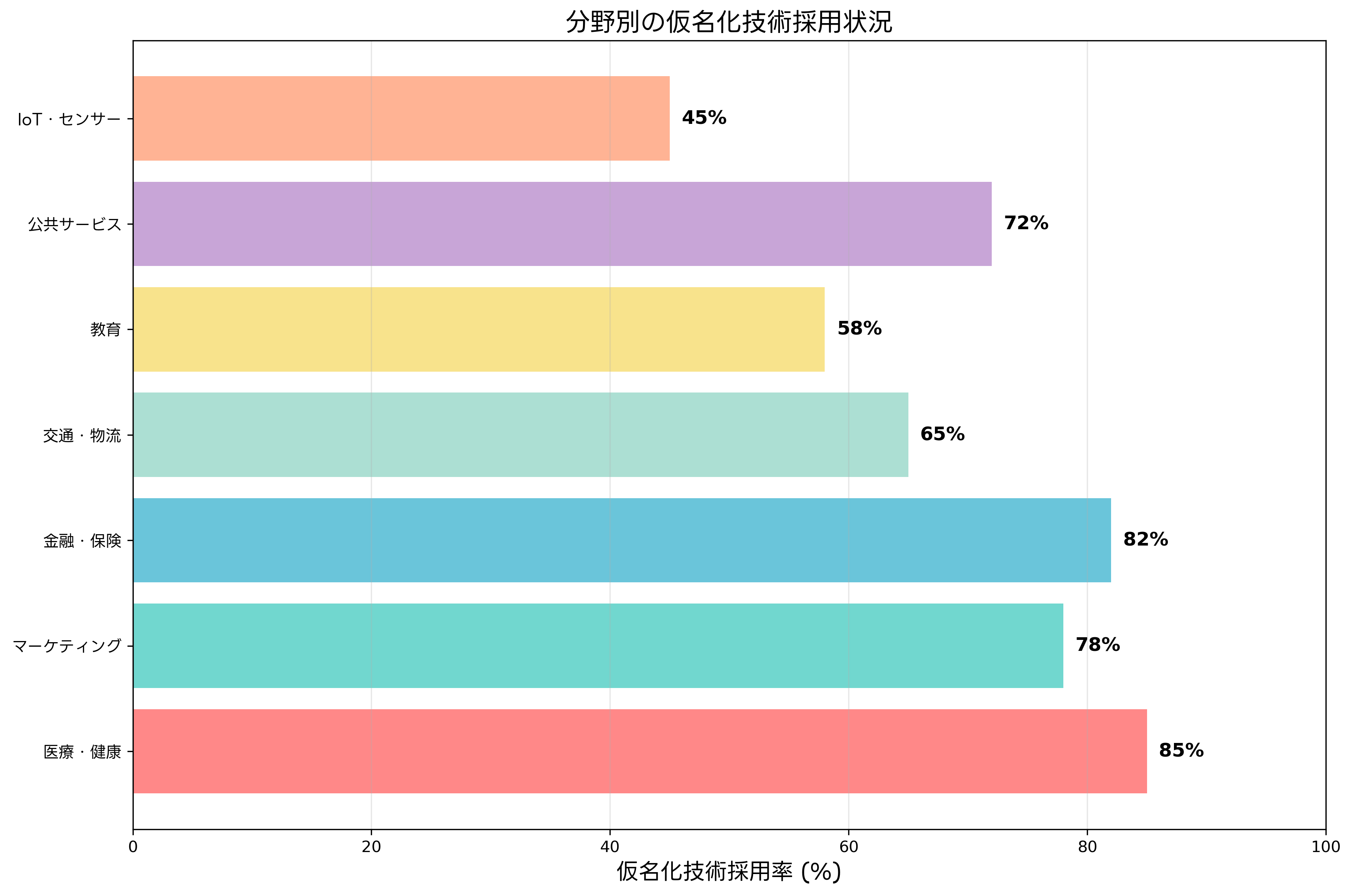
医療分野における仮名化では、患者ID、氏名、住所などの直接識別子の削除に加えて、診療日の一般化、稀な疾患名の上位分類への変換、検査値の範囲化などが行われます。これらの処理を効率化するため、医療データ仮名化システムやHIPAA準拠データ処理ツールが開発されており、医療機関や製薬会社で広く利用されています。
金融業界では、顧客の取引データや信用情報の仮名化が重要です。金融データは、詐欺検知、リスク管理、マーケティング分析などに活用される一方で、個人の経済状況という極めてセンシティブな情報を含んでいます。金融分野の仮名化では、取引金額の範囲化、取引先の業種分類化、取引日時の粗粒度化などが行われ、金融データプライバシー保護ソリューションにより実装されています。
マーケティング分野では、顧客行動データの仮名化が活発に行われています。Webサイトのアクセスログ、購買履歴、アンケート回答などのデータを仮名化することで、個人を特定せずにマーケティング分析や商品開発に活用できます。この分野では、顧客データ分析プラットフォームやプライバシー配慮型マーケティングツールが広く使用されています。
教育分野では、学習データや成績データの仮名化により、教育効果の分析や学習支援システムの改善が行われています。学生の学習履歴、テスト結果、出席状況などのデータを仮名化することで、個別の学習者を特定せずに教育研究や教材開発に活用できます。教育データマイニングツールや学習分析システムにより、これらの取り組みが支援されています。
技術的実装のベストプラクティス
効果的な仮名化システムを構築するためには、技術的なベストプラクティスを理解し、適切に実装することが重要です。データの前処理段階では、データ品質の評価、欠損値の処理、異常値の検出などを行い、仮名化処理の精度を向上させます。この段階でデータ品質管理ツールを使用することで、効率的なデータクレンジングが可能になります。
仮名化アルゴリズムの選択は、データの性質と利用目的に応じて慎重に行う必要があります。構造化データには表形式の匿名化手法が適用できますが、非構造化データ(テキスト、画像、音声など)には専用の手法が必要です。テキストデータの仮名化では、固有名詞の検出と置換、センシティブな表現の除去、文体の正規化などが行われ、自然言語処理ライブラリにより実装されます。
スケーラビリティの確保も重要な考慮事項です。大規模なデータセットを処理する場合、分散処理フレームワークを活用した並列処理が必要になります。Apache Spark、Hadoop、Daskなどのフレームワークを使用することで、ペタバイト規模のデータでも効率的に仮名化処理を実行できます。これらの環境を構築するため、ビッグデータ処理プラットフォームやクラウド分析サービスが活用されています。
バージョン管理と監査ログの記録も重要です。仮名化処理のパラメータ、使用したアルゴリズム、処理日時、担当者などの情報を詳細に記録し、後日の検証や規制対応に備える必要があります。データ系譜管理ツールにより、データの変換履歴を自動的に追跡し、コンプライアンス要件を満たすことができます。
セキュリティの確保も不可欠です。仮名化処理中のデータや、処理に使用する辞書ファイル、パラメータファイルなどが漏洩すると、仮名化の効果が損なわれる可能性があります。処理環境への適切なアクセス制御、データの暗号化、セキュアな通信の使用などの対策が必要です。データセキュリティ管理システムにより、これらのセキュリティ要件を統合的に管理できます。
機械学習との組み合わせ
近年、機械学習技術と仮名化技術の組み合わせにより、より高度なプライバシー保護手法が開発されています。連合学習(Federated Learning)は、データを集約せずに分散環境で機械学習モデルを訓練する手法であり、データの仮名化と組み合わせることで、プライバシーリスクを大幅に削減できます。
生成的敵対ネットワーク(GAN)を活用した合成データ生成も注目されています。実データを仮名化する代わりに、統計的性質を保持した合成データを生成することで、元データに関する情報を一切含まないデータセットを作成できます。合成データ生成ツールやプライバシー保護AI開発プラットフォームにより、これらの技術を実用化できます。
ホモモルフィック暗号化は、暗号化されたデータに対して直接計算を行うことができる技術です。データを復号せずに統計分析や機械学習を実行できるため、究極的なプライバシー保護を実現できます。ただし、計算コストが高いという課題があり、実用化には高性能暗号化ハードウェアや専用計算クラスターが必要になる場合があります。
セキュアマルチパーティ計算(SMPC)は、複数の参加者が秘密情報を共有せずに共同で計算を行う技術です。複数の組織が保有するデータを仮名化した上でSMPCにより分析することで、各組織のプライバシーを保護しながら有益な知見を得ることができます。この技術を実装するため、セキュアマルチパーティ計算フレームワークが研究開発されています。
国際的な動向と標準化
仮名化技術は国際的にも重要な技術として認識されており、様々な標準化活動が進められています。ISO/IEC 20889:2018「Privacy engineering - Privacy techniques and their use cases」では、仮名化を含む様々なプライバシー保護技術が体系的に整理されており、技術選択の指針として活用されています。
欧州連合の一般データ保護規則(GDPR)では、仮名化が適切な技術的組織的措置の一例として明示されています。GDPRの仮名化概念は日本の個人情報保護法にも影響を与えており、国際的な調和が図られています。GDPR準拠のシステムを構築するため、GDPR対応データ管理ソリューションが多くの企業で導入されています。
米国では、HIPAA(医療保険の相互運用性と説明責任に関する法律)において、医療データの非識別化手法が詳細に規定されています。また、カリフォルニア州消費者プライバシー法(CCPA)でも、プライバシー保護技術として仮名化が言及されています。これらの規制に対応するため、多法域対応プライバシー管理システムの需要が高まっています。
アジア太平洋地域でも仮名化技術への関心が高まっており、各国で個人データ保護法制の整備が進められています。シンガポールの個人データ保護法(PDPA)、韓国の個人情報保護法、タイの個人データ保護法などでも、仮名化に類似する概念が導入されています。
応用情報技術者試験での出題傾向
応用情報技術者試験において、仮名化に関する問題は情報セキュリティ分野で頻繁に出題されています。特に、個人情報保護法の改正以降、仮名加工情報に関する問題が増加傾向にあります。午前問題では、仮名化の定義、k-匿名性の概念、個人情報保護法における位置づけなどが問われることが多く、午後問題では、具体的な仮名化手法の選択や実装に関する問題が出題されます。
出題傾向としては、技術的な仮名化手法だけでなく、法的な観点からの問題も重視されています。個人情報、仮名加工情報、匿名加工情報の違いや、それぞれの取扱い規則に関する問題は特に重要です。また、再識別リスクの評価方法や、プライバシー影響評価(PIA)の実施方法に関する問題も出題されています。
実践的な問題では、企業のデータ活用戦略における仮名化技術の位置づけや、異なる仮名化手法の特性比較、コストベネフィット分析などが問われます。これらの問題に対応するため、応用情報技術者試験対策書や情報セキュリティ専門書を活用した学習が効果的です。
新技術との組み合わせに関する問題も増加しています。人工知能、ブロックチェーン、IoTなどの技術における仮名化の応用や、クラウドコンピューティング環境での仮名化実装に関する問題が出題されています。これらの分野の最新動向を把握するため、技術動向調査資料や学術論文集による学習も有効です。
まとめ
仮名化技術は、個人情報保護とデータ活用の両立を実現する重要な技術として、その重要性がますます高まっています。技術的な観点では、k-匿名性、l-多様性、差分プライバシーなどの理論的基盤に基づいた確実な実装が求められ、法的な観点では、個人情報保護法をはじめとする各国の規制要件への適切な対応が必要です。
応用情報技術者試験においても、仮名化は重要な出題分野となっており、技術的な理解と法的な知識の両方が求められます。実際のビジネス現場では、医療、金融、マーケティングなど様々な分野で仮名化技術が活用されており、その適用範囲は今後も拡大していくことが予想されます。
新しい技術との融合により、仮名化の手法もより高度化・多様化しています。機械学習、暗号化、ブロックチェーンなどの技術と組み合わせることで、従来では不可能だったレベルのプライバシー保護とデータ活用の両立が可能になっています。継続的な技術習得と法制度の動向把握により、変化する環境に対応できる能力を身につけることが重要です。