現代のITシステムにおいて、監視・モニタリングは安定したサービス提供と継続的な運用を実現するための必要不可欠な技術です。応用情報技術者試験でも重要な出題分野として位置づけられており、システム運用管理の基盤となる概念と技術を理解することが求められます。
監視・モニタリングとは、ITシステムの状態を継続的に観察し、異常や問題を早期に発見して対応するための一連の活動です。これにより、システムの可用性向上、パフォーマンス最適化、セキュリティ強化、コスト削減などの効果を実現できます。
監視・モニタリングの基本概念と目的
監視・モニタリングの主な目的は、システムの正常な動作を確保し、問題が発生した際に迅速な対応を可能にすることです。これには、予防的な監視と事後的な監視の両方が含まれます。予防的な監視では、システムの状態を継続的に監視し、問題が発生する前に警告を発することで、サービス停止を回避します。事後的な監視では、実際に発生した問題を速やかに検出し、影響を最小限に抑えるための対応を行います。
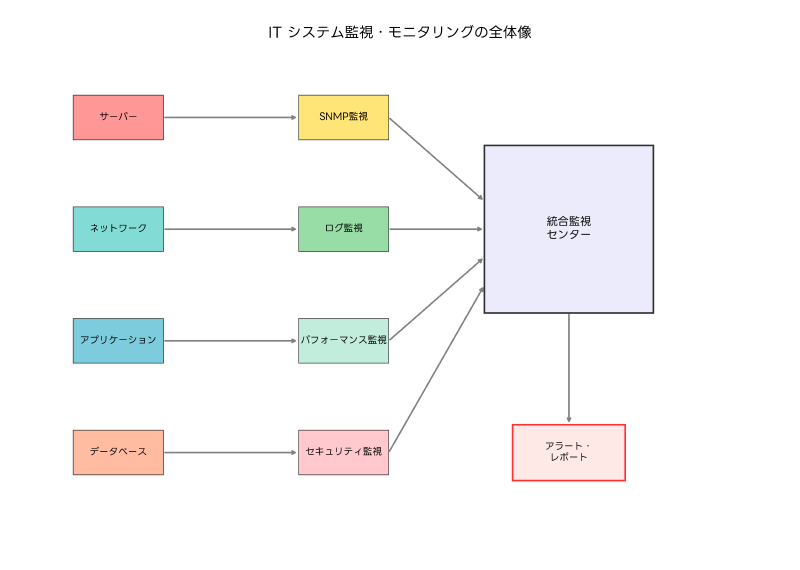
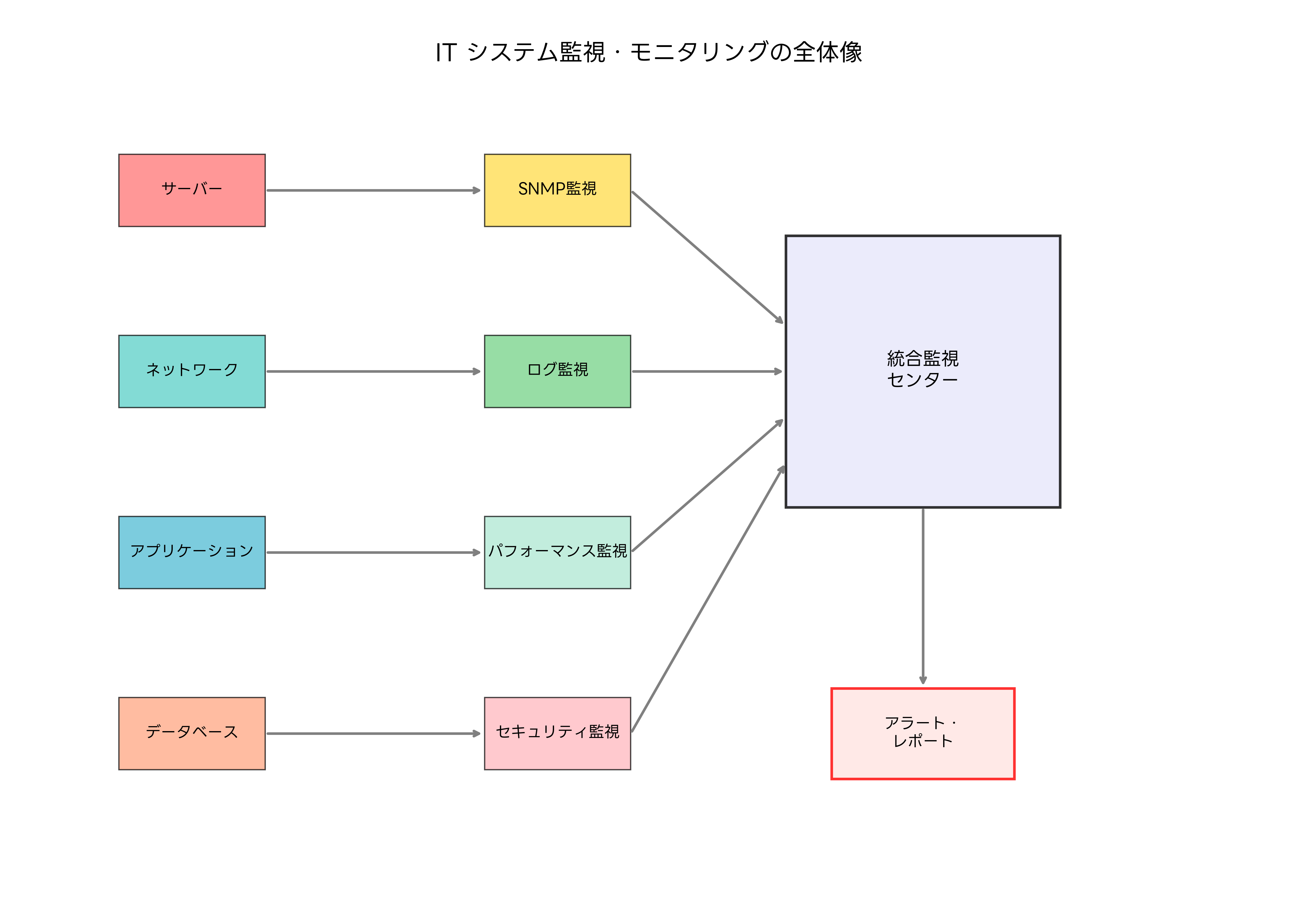
効果的な監視システムの構築には、適切な監視ソフトウェアの選択が重要です。企業の規模や要件に応じて、オープンソースの監視ツールから商用の統合監視プラットフォームまで、様々な選択肢があります。監視の対象となるのは、サーバー、ネットワーク機器、アプリケーション、データベース、ストレージシステムなど、ITインフラストラクチャ全体です。
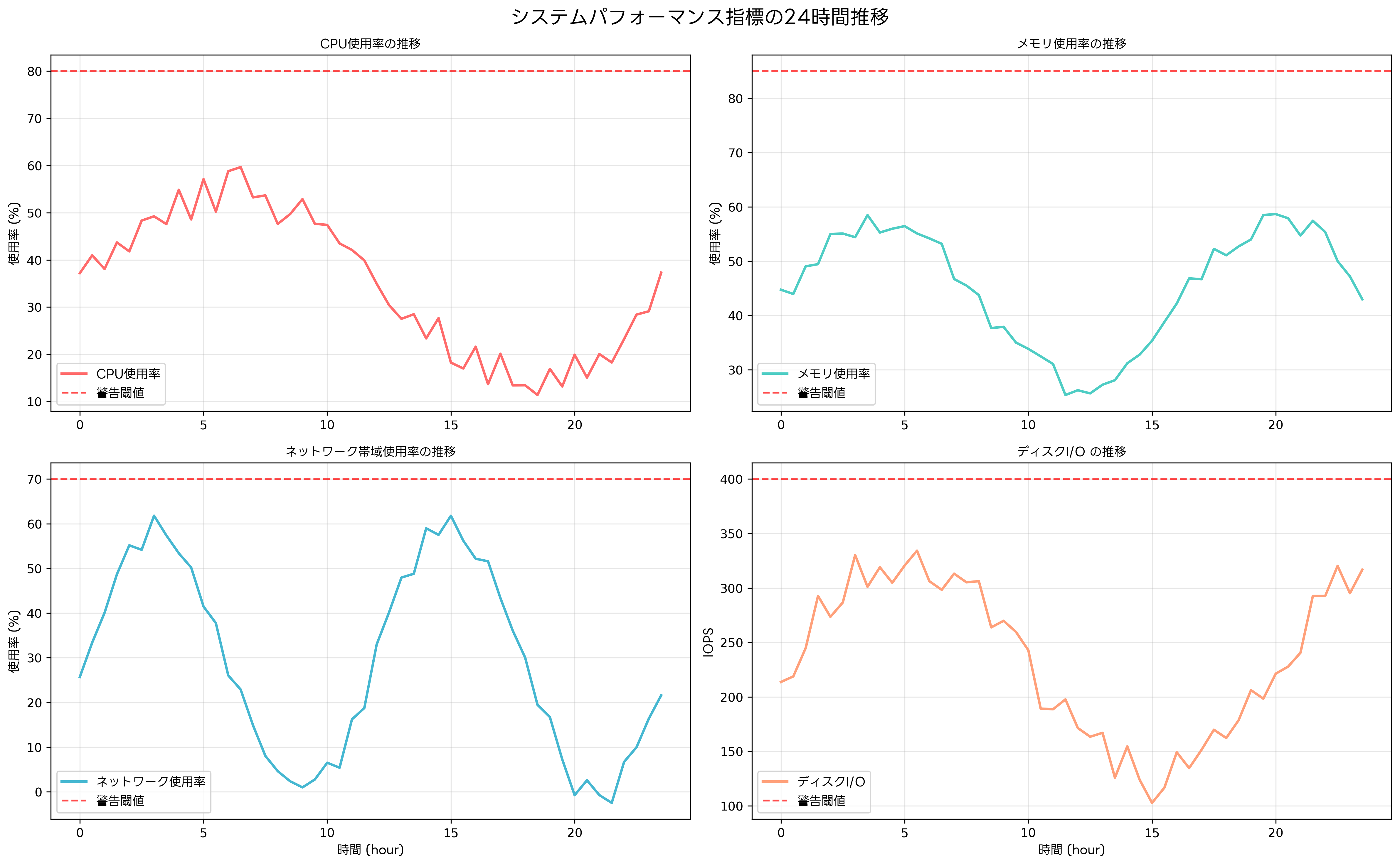
監視項目の設定では、CPU使用率、メモリ使用率、ディスク容量、ネットワーク帯域使用率、レスポンス時間、エラー率などの基本的な指標から、ビジネス固有のKPI(重要業績評価指標)まで、幅広い観点での監視が必要です。これらの指標を効果的に管理するため、多くの企業では統合監視ダッシュボードを導入し、一元的な状況把握を実現しています。
監視データの収集方法には、エージェント型とエージェントレス型があります。エージェント型では、監視対象システムに専用のソフトウェアをインストールして詳細な情報を収集します。エージェントレス型では、SNMP、WMI、SSH、HTTPなどの標準プロトコルを使用して外部から情報を取得します。それぞれにメリット・デメリットがあるため、環境や要件に応じて適切な方法を選択することが重要です。
インフラストラクチャ監視の実装
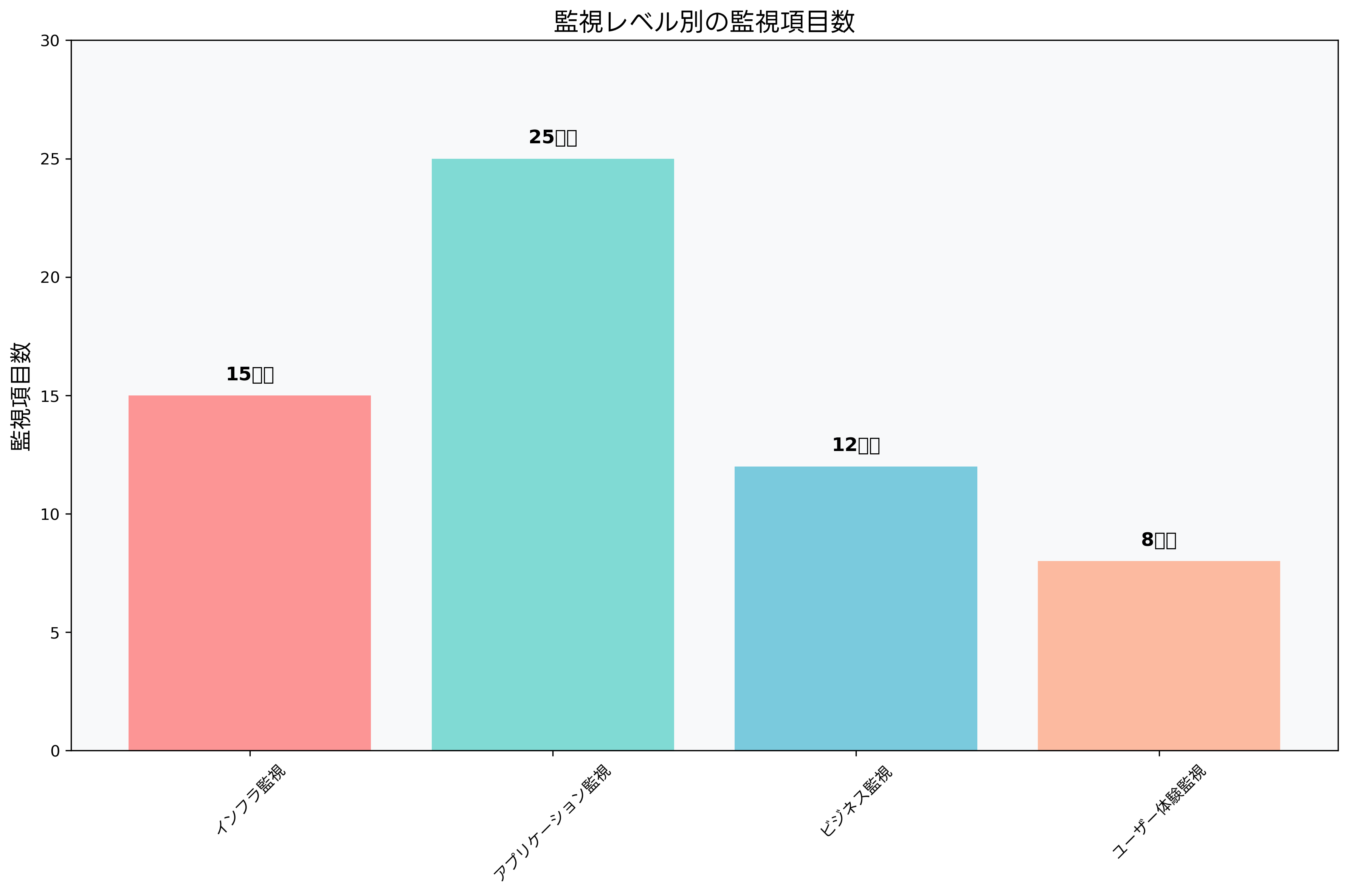
インフラストラクチャ監視は、ITシステムの基盤となるハードウェアとソフトウェアの状態を監視する領域です。サーバー監視では、物理サーバーや仮想マシンのリソース使用状況、プロセスの動作状態、サービスの稼働状況などを継続的に監視します。現代のデータセンターでは、高性能サーバー監視システムの導入により、数百台から数千台のサーバーを効率的に管理しています。
ネットワーク監視では、ルーター、スイッチ、ファイアウォールなどのネットワーク機器の状態を監視します。帯域使用率、パケットロス、レイテンシー、接続数などの指標を監視することで、ネットワークのボトルネックや障害を早期に発見できます。ネットワーク監視ツールには、SNMPベースの従来型から、フロー分析機能を持つ高度なものまで様々な種類があります。
ストレージ監視では、ディスク使用量、I/O性能、RAID状態、バックアップ状況などを監視します。データの増加に伴い、ストレージ容量の枯渇は深刻な問題となるため、容量の推移を予測し、適切なタイミングで拡張を行うことが重要です。ストレージ監視ソリューションを活用することで、複雑なストレージ環境の効率的な管理が可能になります。
仮想化環境の監視では、ハイパーバイザーレベルでの監視が重要になります。仮想マシンのリソース配分、マイグレーション状況、クラスター全体の負荷バランスなどを監視し、仮想化基盤全体の最適化を図ります。仮想化監視プラットフォームの導入により、物理環境と仮想環境の統合的な監視が実現できます。
クラウド環境では、従来のオンプレミス監視とは異なるアプローチが必要です。クラウドプロバイダーの提供する監視サービスと、サードパーティのクラウド監視ツールを組み合わせて、ハイブリッドクラウド環境全体の可視化を実現します。
アプリケーション・パフォーマンス監視(APM)
アプリケーション・パフォーマンス監視は、ビジネスアプリケーションの性能と動作を監視する技術です。単なるインフラストラクチャの監視を超えて、アプリケーションの内部動作、トランザクションの処理時間、データベースクエリの実行状況、外部システムとの連携状況などを詳細に監視します。
APMツールでは、アプリケーションコードに組み込まれたエージェントやプローブが、実行時の詳細な情報を収集します。これにより、処理の遅延がどこで発生しているか、どのコンポーネントがボトルネックになっているかを特定できます。APMソリューションの導入により、複雑な分散システムでも問題の根本原因を迅速に特定することができます。
トランザクション追跡機能では、一つのビジネストランザクションが複数のシステムコンポーネントを通過する様子を可視化できます。Webサーバー、アプリケーションサーバー、データベースサーバーにまたがる処理の流れを追跡し、どの段階で問題が発生しているかを特定します。これは、マイクロサービスアーキテクチャにおいて特に重要な機能です。
エラー監視とログ分析も APM の重要な要素です。アプリケーションで発生するエラーやエクセプションを自動的に収集し、発生頻度や影響範囲を分析します。ログ分析プラットフォームと連携することで、エラーの詳細な原因分析が可能になります。
ユーザーエクスペリエンス監視では、実際のユーザーがアプリケーションを使用する際の体験を測定します。ページの読み込み時間、操作の応答時間、エラー発生率などを実測し、ビジネスに直接影響する指標として監視します。リアルユーザー監視ツールにより、地理的な場所や使用ブラウザーによる性能差も把握できます。
セキュリティ監視とログ管理
セキュリティ監視は、システムに対する脅威や攻撃を検出し、セキュリティインシデントに迅速に対応するための監視活動です。SIEM(Security Information and Event Management)システムを中心として、多様なセキュリティイベントを収集、分析、対応する統合的なアプローチが採用されています。
ログ監視では、システムの各コンポーネントから生成されるログファイルを収集し、異常なパターンや疑わしい活動を検出します。Webサーバーのアクセスログ、アプリケーションのエラーログ、データベースの監査ログ、ファイアウォールの通信ログなど、多様なソースからの情報を統合分析します。ログ管理システムの導入により、大量のログデータの効率的な処理と分析が可能になります。
侵入検知システム(IDS)と侵入防止システム(IPS)は、ネットワークトラフィックやシステムの活動を監視し、悪意のある活動を検出・防止します。署名ベースの検知と異常ベースの検知を組み合わせることで、既知の攻撃パターンと未知の脅威の両方に対応できます。統合セキュリティ監視プラットフォームにより、複数のセキュリティツールを一元管理できます。
脆弱性監視では、システムの構成変更や新しい脆弱性情報に基づいて、継続的にセキュリティリスクを評価します。パッチ管理システムと連携し、重要な脆弱性に対する迅速な対応を支援します。脆弱性管理ツールを使用することで、システム全体のセキュリティ状況を可視化し、リスクベースの管理が可能になります。
コンプライアンス監視では、規制要件や社内ポリシーへの準拠状況を継続的に監視します。アクセス権限の変更、機密データへのアクセス、システム構成の変更などを追跡し、監査証跡を維持します。コンプライアンス監視ソリューションにより、規制要件への対応を自動化できます。
アラート管理とインシデント対応
効果的なアラート管理は、監視システムの価値を最大化するための重要な要素です。適切な閾値設定、優先度の分類、エスカレーション手順の定義により、重要な問題に迅速に対応できる体制を構築します。
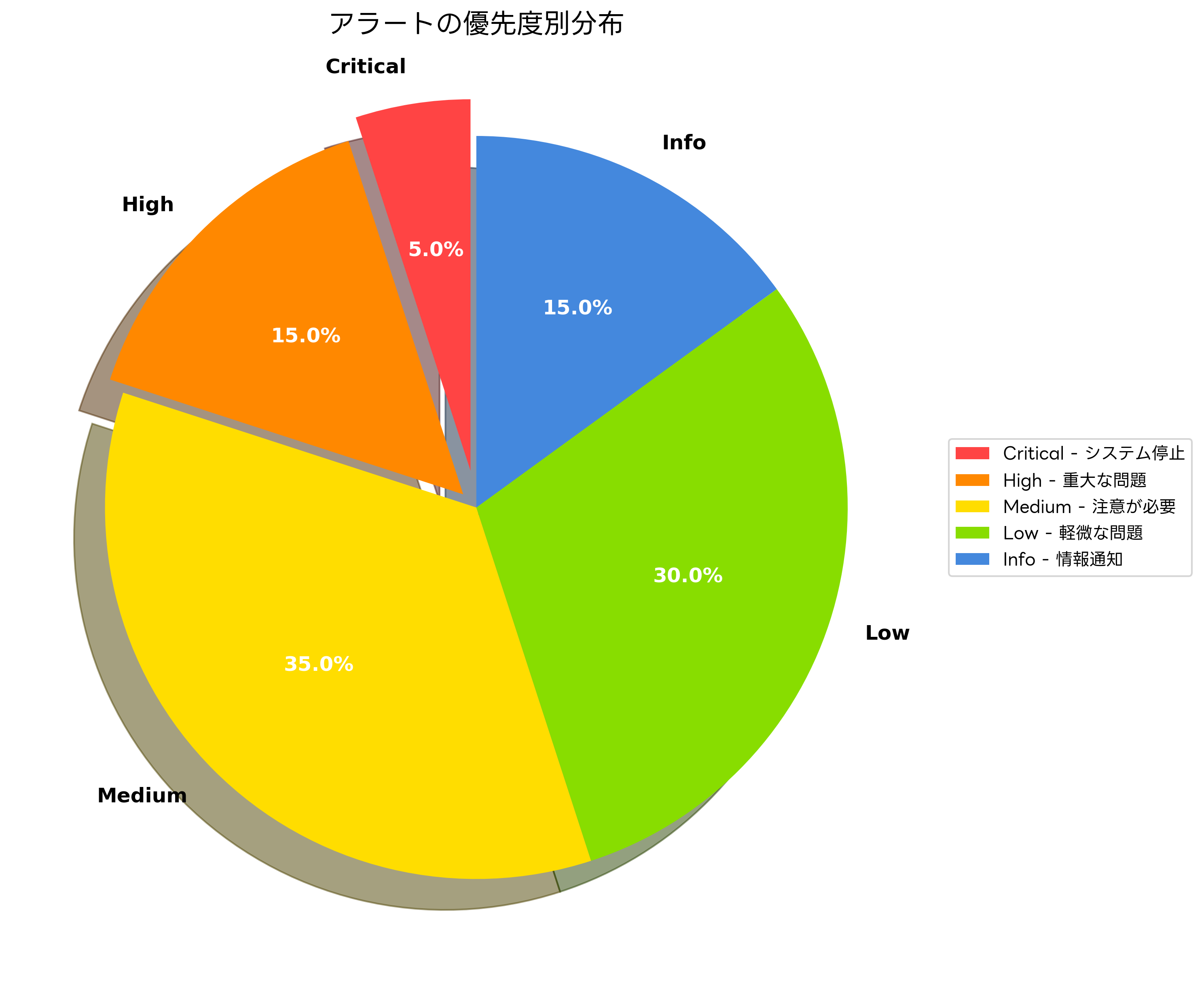
アラートの分類では、Critical、High、Medium、Low、Infoの5段階に分けて優先度を設定するのが一般的です。Criticalアラートはシステム停止など即座の対応が必要な問題、Highアラートは重大な性能劣化など数分以内の対応が必要な問題として分類します。アラート管理システムを使用することで、複数の監視ツールからのアラートを統合管理できます。
エスカレーション手順では、初期対応者が一定時間内に対応できない場合の上位者への通知ルールを定義します。時間外や休日の対応体制、緊急連絡先の管理、代理対応者の指定などを含む包括的なエスカレーション体制が必要です。インシデント管理プラットフォームにより、複雑なエスカレーション手順を自動化できます。
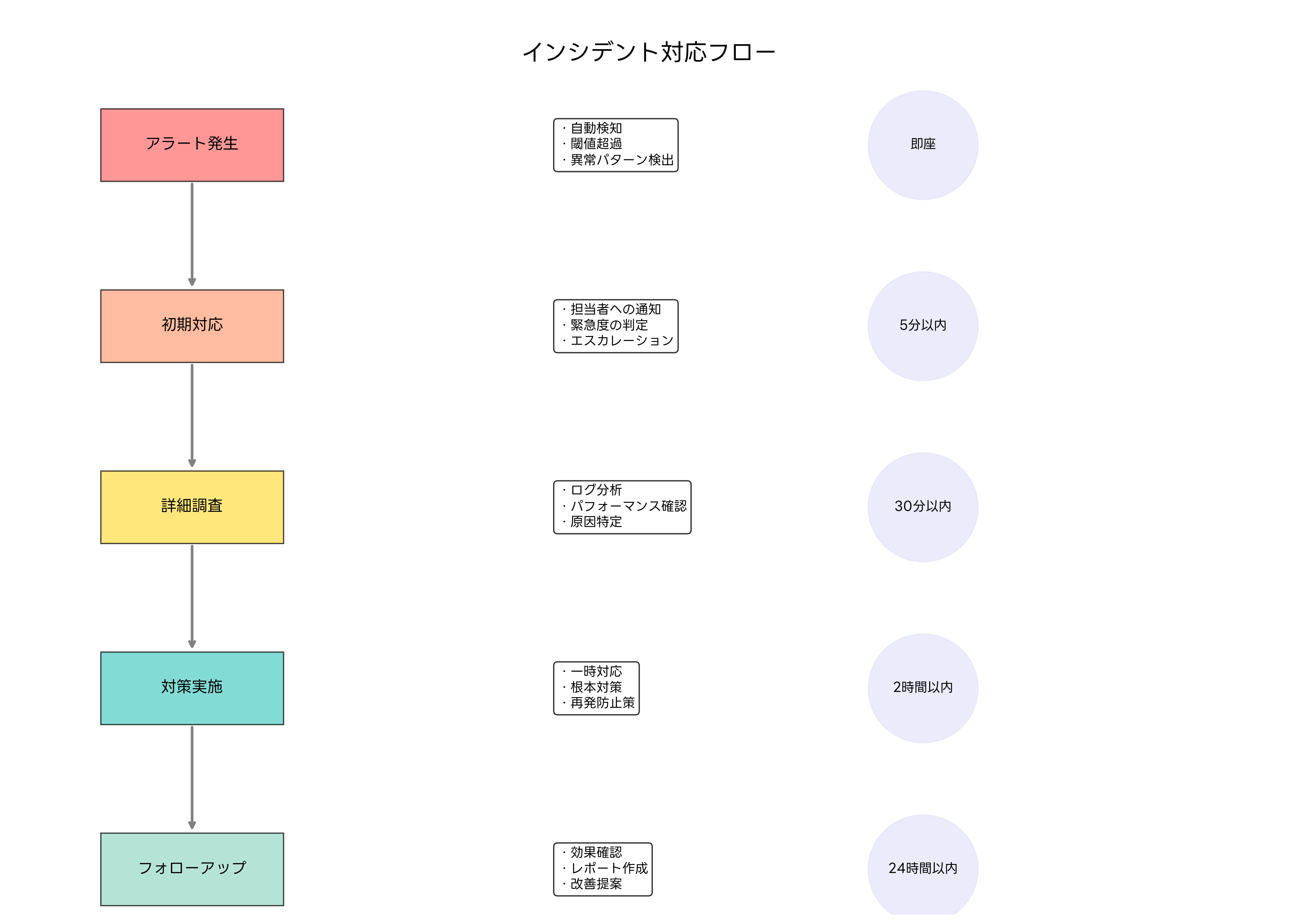
通知方法の多様化も重要です。メール、SMS、音声通話、チャットツールへの通知など、複数のチャネルを組み合わせることで、確実な情報伝達を実現します。マルチチャネル通知システムを導入することで、状況に応じた最適な通知方法を選択できます。
アラートの抑制とグループ化機能により、関連する複数のアラートを統合して通知することで、アラートストームを防止できます。根本原因となる問題を特定し、関連する症状的なアラートを自動的に抑制することで、対応者の負荷を軽減し、重要な問題に集中できる環境を提供します。
監視ツールの選択と比較
監視ツールの選択は、組織の規模、技術スタック、予算、運用体制などを総合的に考慮して行う必要があります。オープンソースのツールから商用のエンタープライズソリューションまで、多様な選択肢があります。
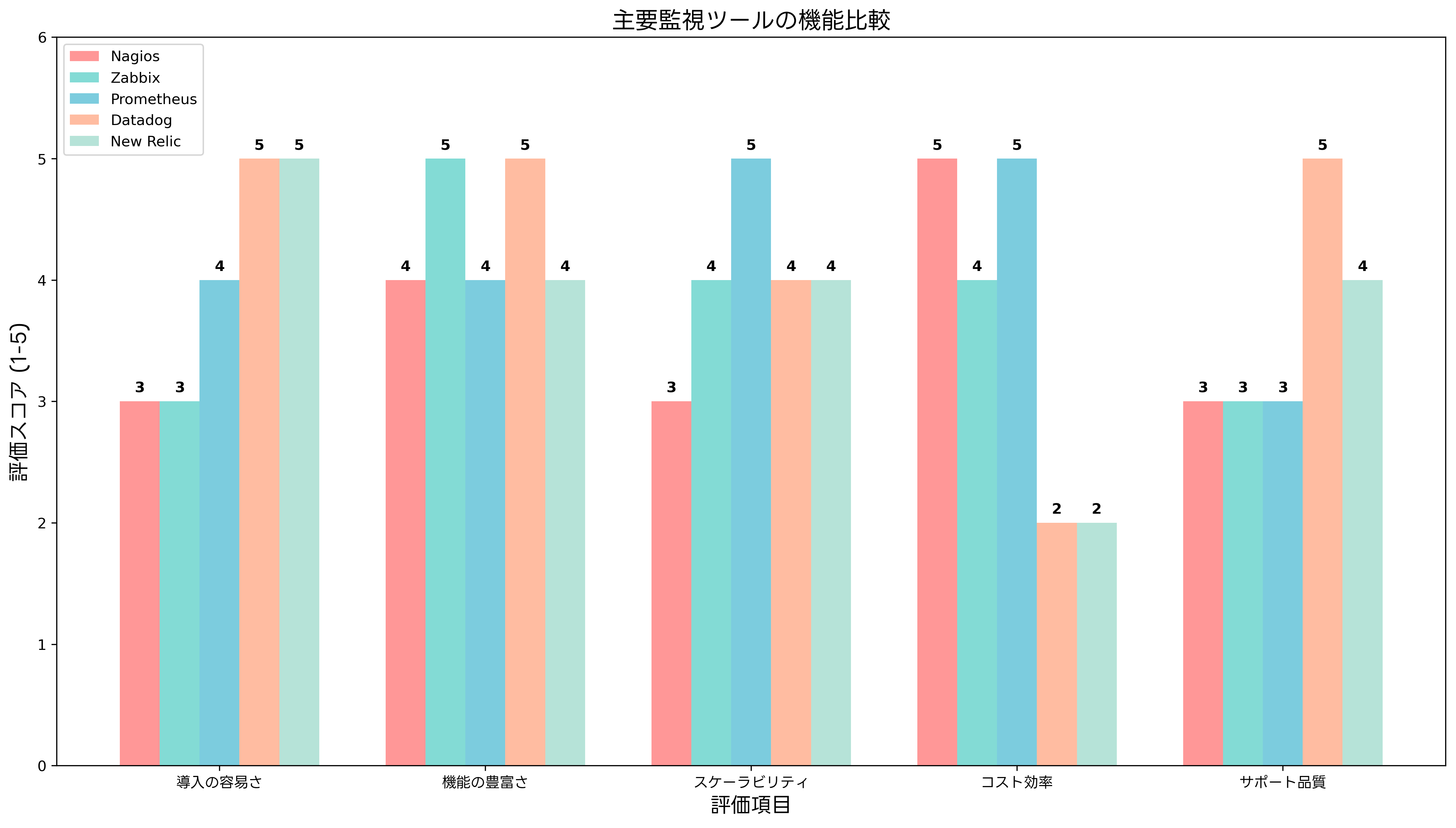
オープンソース系の監視ツールでは、Nagios、Zabbix、Prometheusなどが代表的です。Nagiosはシンプルでカスタマイズしやすいのがメリットですが、大規模環境での運用には工夫が必要です。Zabbixは豊富な機能と柔軟な設定が可能で、中規模から大規模環境に適用できます。Prometheusは時系列データベースとしての機能が優秀で、コンテナ環境の監視に特に適しています。これらのツールを効果的に活用するため、オープンソース監視ツール導入ガイドなどの参考書籍を活用することをお勧めします。
商用の統合監視プラットフォームでは、Datadog、New Relic、Dynatrace、SolarWindsなどが主要な選択肢です。これらのツールは導入の容易さ、豊富な機能、サポート体制が充実していますが、コストが高いのがデメリットです。エンタープライズ監視ソリューション比較の資料を参考に、組織の要件に最適なツールを選択することが重要です。
クラウドネイティブな監視ソリューションでは、AWS CloudWatch、Azure Monitor、Google Cloud Monitoringなどがあります。クラウドサービスとの深い統合が可能で、スケーラビリティに優れていますが、マルチクラウド環境では複数のツールを組み合わせる必要があります。クラウド監視戦略に関する書籍を参考に、包括的な監視戦略を立案することが重要です。
現代的な監視アプローチとベストプラクティス
観測可能性(Observability)の概念が注目を集めています。従来の監視が既知の問題を検出することに焦点を当てていたのに対し、観測可能性は未知の問題も含めてシステムの内部状態を理解することを目指します。メトリクス、ログ、トレースの3つの柱を統合的に活用することで、より深いシステム理解が可能になります。
SRE(Site Reliability Engineering)のアプローチでは、SLI(Service Level Indicator)、SLO(Service Level Objective)、エラーバジェットの概念を導入して、サービスの信頼性を定量的に管理します。SRE実践ガイドを参考に、データドリブンな運用管理を実現できます。
AIと機械学習を活用した異常検知が普及しています。従来の閾値ベースの監視では検出が困難だった微細な異常や複合的な問題を、機械学習アルゴリズムにより検出できます。AI監視システムの導入により、予防的な問題対応が可能になります。
コンテナとマイクロサービスアーキテクチャに対応した監視では、動的に変化するインフラストラクチャを効果的に監視する新しいアプローチが必要です。サービスディスカバリー、分散トレーシング、メトリクスの自動収集などの技術を組み合わせて、複雑な分散システムの可視化を実現します。コンテナ監視ソリューションにより、Kubernetes環境での効率的な監視が可能になります。
応用情報技術者試験での出題傾向と対策
応用情報技術者試験では、監視・モニタリングに関する問題が システム運用管理、サービスマネジメント、システム監査の分野で出題されます。特に、ITIL v4のサービス運用管理や、ISO 20000の要求事項に基づいた問題が頻出します。
午前問題では、監視ツールの種類と特徴、SLA(Service Level Agreement)とSLOの関係、インシデント管理とプロブレム管理の違い、キャパシティ管理と可用性管理の手法などが問われます。応用情報技術者試験対策書を活用して、体系的な知識を身につけることが重要です。
午後問題では、実際の運用シナリオに基づいた問題解決能力が問われます。システム障害の原因分析、監視システムの設計、パフォーマンス改善提案、コスト最適化などの実践的な問題が出題されます。システム運用管理の実践に関する書籍で、実務的な知識を補強することをお勧めします。
試験対策としては、主要な監視ツールの特徴と適用場面、ITILプロセスの理解、定量的な管理手法(KPI、SLA、SLO)の計算問題への対応が重要です。[ITIL Foundation認定書籍](https://www.amazon.co.jp/s?k=ITIL Foundation認定&tag=amazon-product-items-22)を併用することで、サービス管理の体系的な理解が深まります。
組織的な監視体制の構築
効果的な監視システムの運用には、技術的な側面だけでなく、組織体制の整備も重要です。NOC(Network Operations Center)やSOC(Security Operations Center)の設置、24時間365日の監視体制、運用担当者のスキル開発、手順書の整備などが必要です。
運用チームの編成では、レベル1からレベル3までの階層的なサポート体制を構築します。レベル1では基本的な監視とアラート対応、レベル2では詳細な問題分析と対策実施、レベル3では高度な技術的問題の解決を担当します。ITサービス運用の組織論を参考に、効率的な組織体制を設計できます。
継続的改善の仕組みとして、定期的な監視システムの見直し、閾値の調整、プロセスの最適化を実施します。月次や四半期のレビューミーティングを通じて、監視の効果を評価し、改善策を検討します。継続的改善の実践に関する方法論を活用することで、組織の監視能力を向上させることができます。
災害対策と事業継続計画では、監視システム自体の冗長性確保も重要です。プライマリサイトとセカンダリサイトでの監視システムの冗長化、データのバックアップと復旧手順、通信回線の多重化などを実装します。災害復旧計画の策定により、緊急時でも継続的な監視を維持できます。
まとめ
監視・モニタリングは、現代のITシステム運用において不可欠な技術領域です。インフラストラクチャからアプリケーション、セキュリティに至るまで、包括的な監視を実現することで、システムの安定性、性能、セキュリティを確保できます。応用情報技術者試験では、これらの技術的知識に加えて、組織的な運用管理の理解も求められます。
技術の進歩とともに、監視・モニタリングの手法も進化し続けています。クラウドネイティブな環境、マイクロサービスアーキテクチャ、AIを活用した異常検知など、新しい技術トレンドに対応した監視システムの構築が重要になっています。継続的な学習と実践を通じて、変化する技術環境に対応できる監視スキルを身につけることが、ITプロフェッショナルとしての競争力向上につながります。