コンピュータの世界において、オペランドは機械語命令の重要な構成要素として、プロセッサの動作を理解する上で欠かせない概念です。応用情報技術者試験においても、コンピュータシステムの基礎知識として頻出のトピックであり、プログラミングや システム設計の理解を深めるために必要不可欠な知識です。
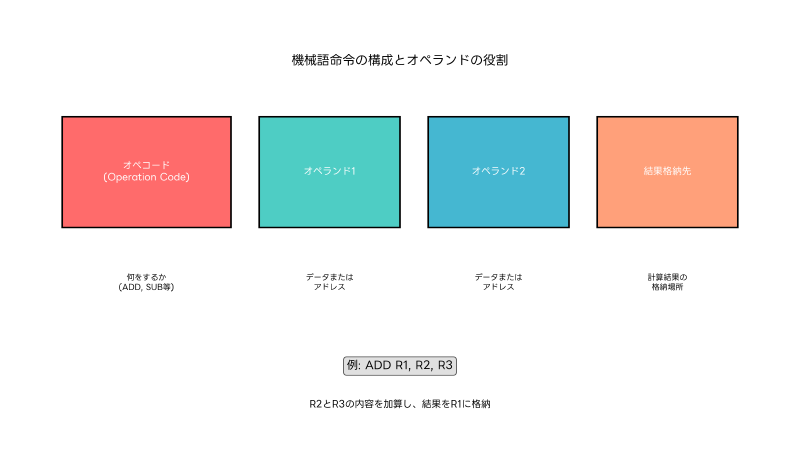
オペランドとは、機械語命令において演算の対象となるデータやそのデータが格納されている場所を指定する部分です。命令はオペコード(Operation Code)と一つ以上のオペランドで構成され、オペコードが「何をするか」を指定するのに対し、オペランドは「何に対して」「どこから」「どこへ」といった情報を提供します。
現代のコンピュータシステムでは、高性能なプロセッサが複雑なオペランド処理を高速で実行し、多様なアプリケーションの動作を支えています。オペランドの理解は、システムの最適化や効率的なプログラミングに直結する重要な知識です。
オペランドの基本概念と分類
オペランドは、その性質と使用方法によっていくつかの種類に分類されます。最も基本的な分類は、オペランドが実際のデータを含むか、データの場所を示すかという観点で行われます。
即値オペランド(Immediate Operand)は、命令の中に直接データが埋め込まれている形式です。例えば、「MOV R1, #100」という命令では、「#100」が即値オペランドであり、レジスタR1に直接100という値を格納します。この方式は高速ですが、命令サイズが大きくなる欠点があります。
レジスタオペランド(Register Operand)は、プロセッサ内のレジスタを指定する形式です。レジスタは高速アクセスが可能なため、頻繁に使用されるデータの格納に適しています。高性能なコンピュータでは、多数のレジスタを搭載してオペランドアクセスの高速化を図っています。
メモリオペランド(Memory Operand)は、主記憶装置上のアドレスを指定する形式です。大量のデータを扱う場合に使用され、様々なアドレッシングモードと組み合わせて柔軟なデータアクセスを実現します。現代のシステムでは、大容量メモリを搭載することで、複雑なオペランド処理を効率的に実行できます。
アドレッシングモードとオペランドの関係
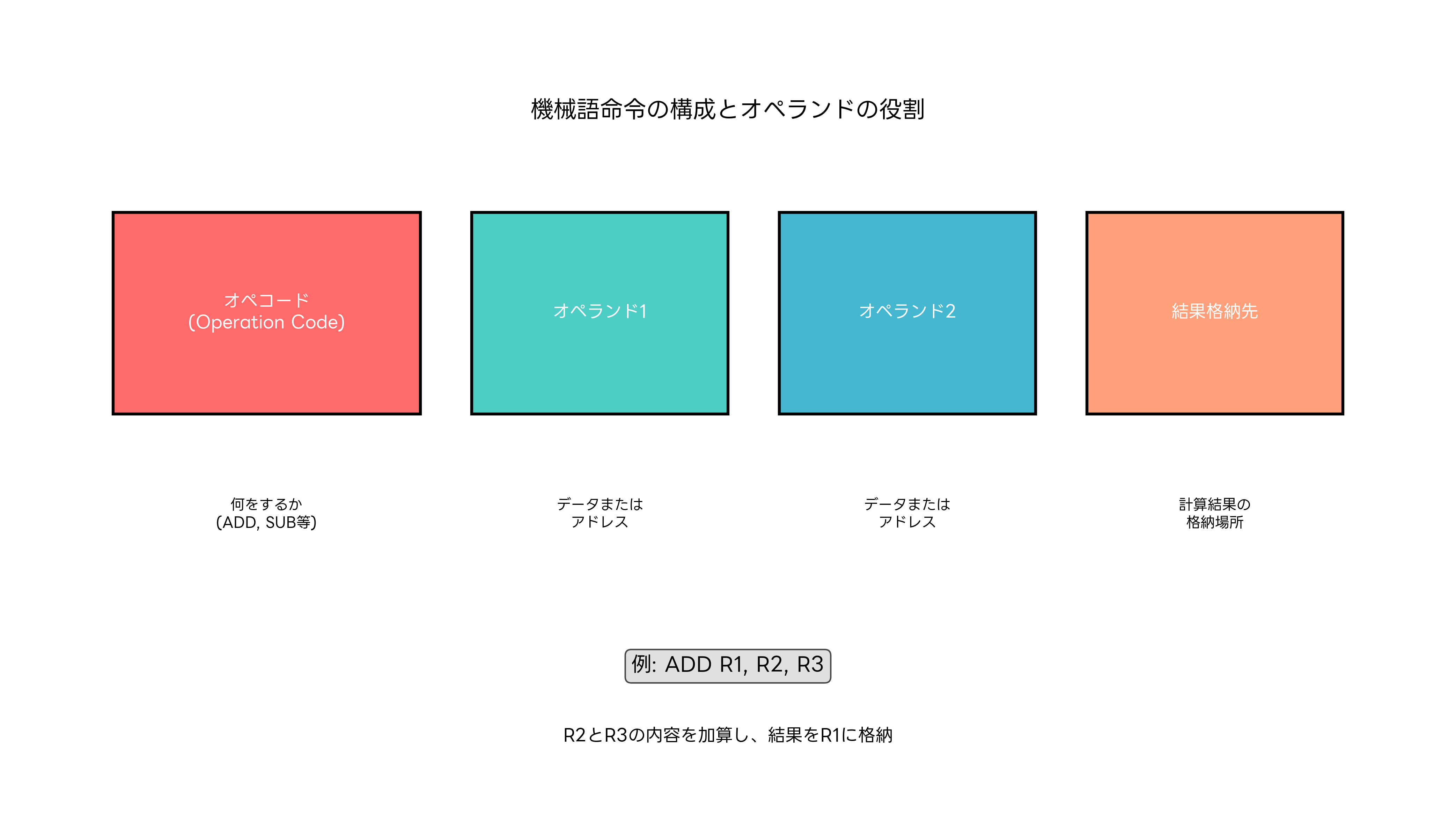
アドレッシングモード(Addressing Mode)は、オペランドがデータにアクセスする方法を定義する重要な概念です。これは、オペランドフィールドに記述された情報をどのように解釈してデータを取得するかを決定します。
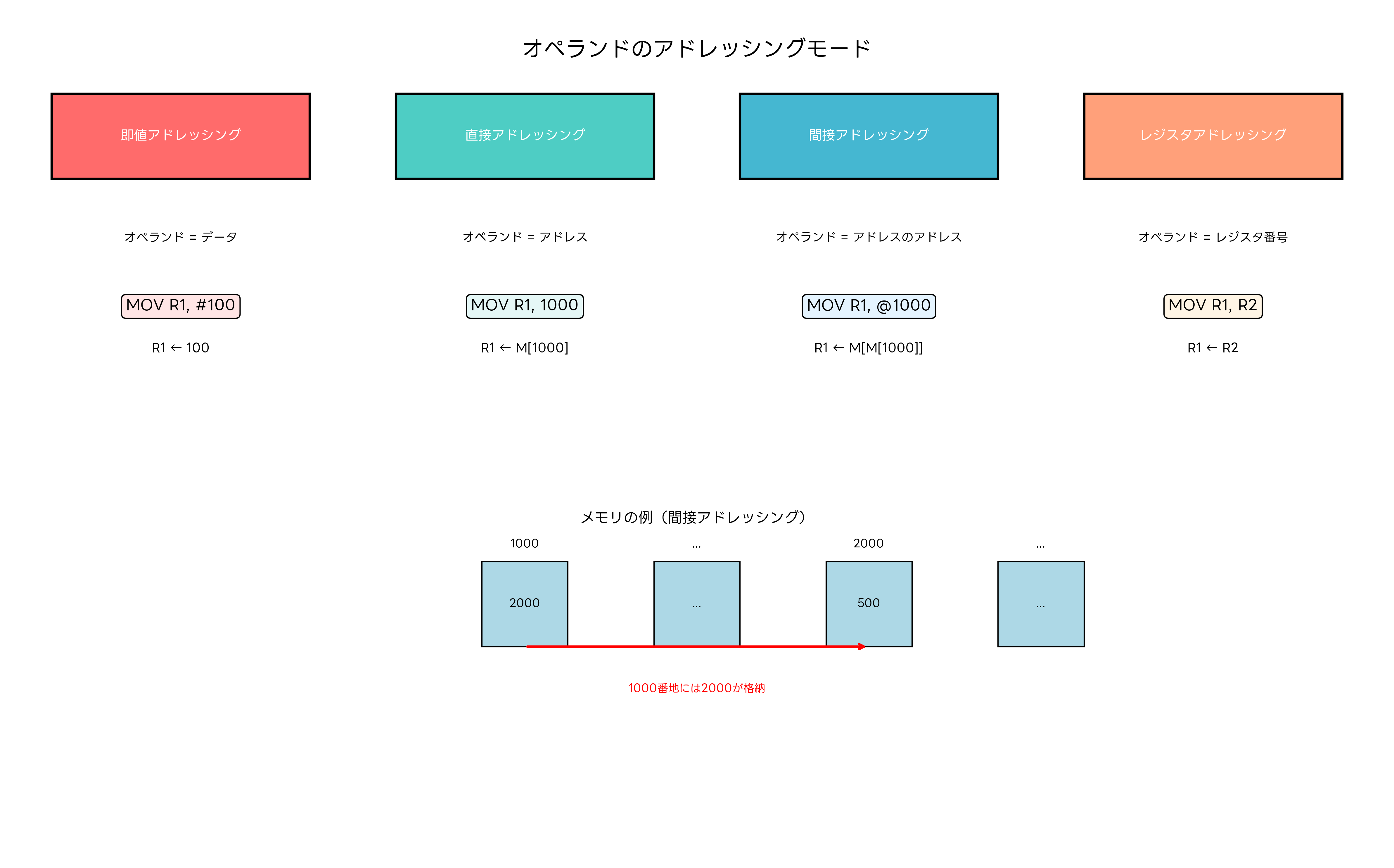
直接アドレッシング(Direct Addressing)では、オペランドフィールドに記述されたアドレスを直接メモリアクセスに使用します。例えば、「LOAD R1, 1000」という命令は、メモリアドレス1000番地のデータをレジスタR1に読み込みます。この方式はシンプルで理解しやすく、多くの基本的な操作で使用されます。
間接アドレッシング(Indirect Addressing)は、オペランドフィールドで指定されたアドレスに格納されている値を、さらにアドレスとして使用する方式です。「LOAD R1, @1000」という命令では、まず1000番地の内容を読み取り、その値をアドレスとして使用してデータを取得します。この方式は、ポインタや動的データ構造の実装に重要な役割を果たします。
相対アドレッシング(Relative Addressing)は、現在のプログラムカウンタ(PC)の値を基準とした相対的な位置を指定する方式です。分岐命令やジャンプ命令で頻繁に使用され、プログラムの位置に依存しないコードの生成を可能にします。プログラミング学習書では、このような低レベルの概念を詳しく解説しています。
インデックスアドレッシング(Indexed Addressing)は、ベースアドレスにインデックスレジスタの値を加算してアドレスを計算する方式です。配列やテーブルのアクセスに適しており、「LOAD R1, 1000(R2)」のような形式で記述されます。この方式により、ループ処理での配列要素への順次アクセスが効率的に実現できます。
データ型とオペランドサイズ
オペランドが扱うデータには様々な型があり、それぞれ異なるサイズとフォーマットを持ちます。プロセッサは、オペランドのデータ型に応じて適切な処理を実行する必要があります。
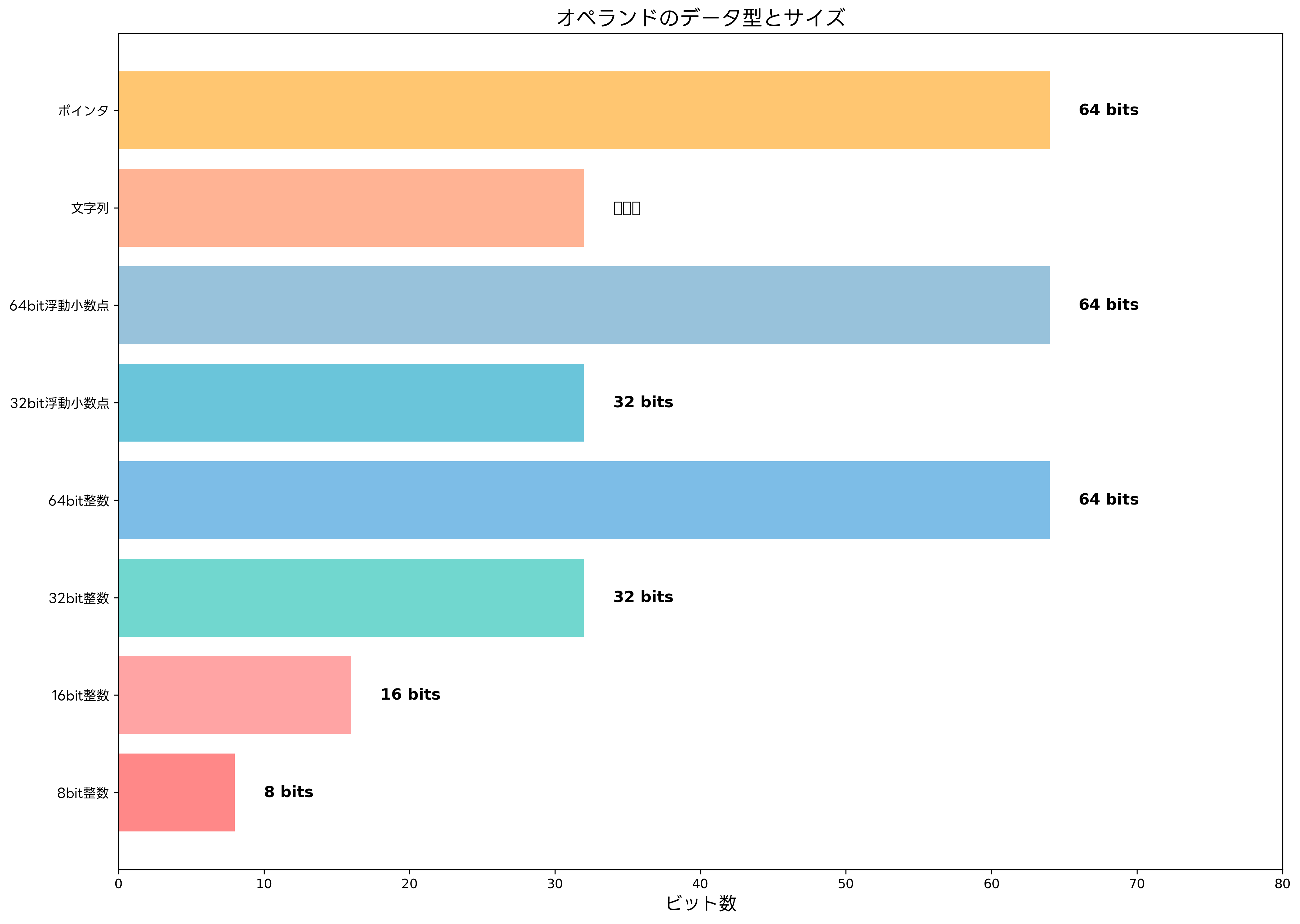
整数型オペランドは、符号付きと符号なしの両方の形式があり、8ビット、16ビット、32ビット、64ビットなどの異なるサイズで定義されます。現代のプロセッサでは、64ビット整数の処理が標準的になっており、大きな数値や高精度な計算が可能になっています。高性能ワークステーションでは、これらの大きなデータ型を効率的に処理できる強力なプロセッサが搭載されています。
浮動小数点数型オペランドは、IEEE 754標準に従って定義され、32ビット単精度と64ビット倍精度が一般的です。科学計算や工学シミュレーションでは、高精度な浮動小数点演算が重要であり、専用の数値計算ソフトウェアと組み合わせて使用されます。
文字列型オペランドは、可変長のデータを扱うため、特別な処理が必要です。文字列の開始アドレスと長さ情報を組み合わせて処理されることが多く、テキスト処理や文字列操作において重要な役割を果たします。テキスト処理ツールは、このような文字列オペランドの効率的な処理を実現しています。
ポインタ型オペランドは、他のデータのアドレスを格納するデータ型です。プロセッサのアドレス空間に応じて32ビットまたは64ビットのサイズを持ち、動的メモリ管理やデータ構造の実装において重要です。システムプログラミング書籍では、ポインタの概念と使用方法について詳しく解説されています。
スタック型オペランドとその動作
一部のプロセッサアーキテクチャでは、スタック(Stack)を基本とするオペランド処理が採用されています。スタック型オペランドは、後入れ先出し(LIFO: Last In, First Out)の原理に基づいて動作し、多くの計算を効率的に実行できます。
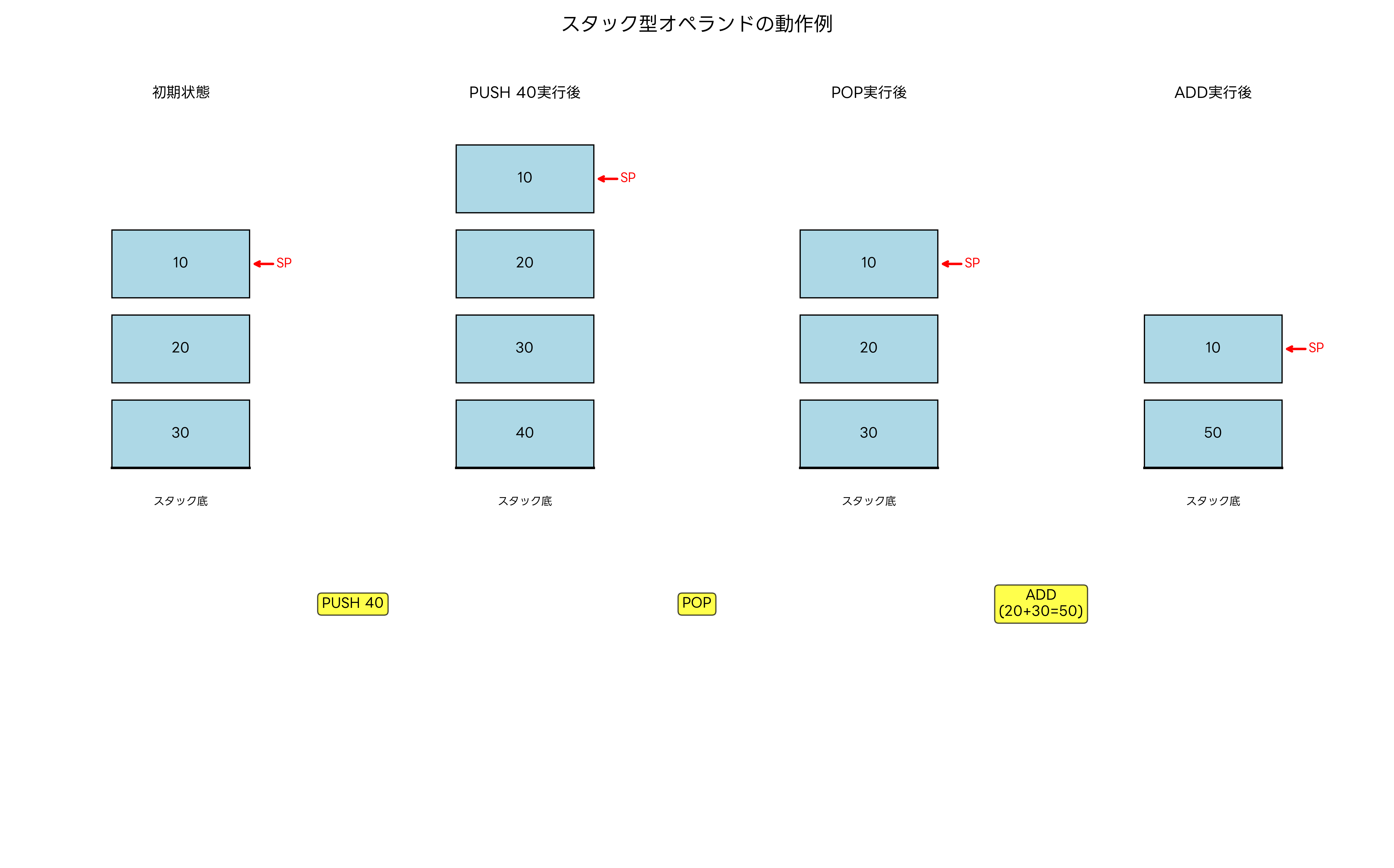
スタック型アーキテクチャでは、演算のオペランドはスタックの上位要素から自動的に取得され、結果もスタックにプッシュされます。例えば、加算命令「ADD」は、スタックから2つの値をポップし、それらを加算してから結果をプッシュします。この方式により、明示的なオペランド指定が不要になり、命令コードの簡素化が実現できます。
Java仮想マシン(JVM)は、スタック型オペランドの代表的な実装例です。Javaバイトコードは、すべての演算をスタック操作として実行し、プラットフォーム独立性を実現しています。Java開発環境では、このスタック型処理モデルを理解することが重要です。
スタック型処理の利点は、オペランドの管理が簡単で、コンパイラの実装が容易になることです。また、式の評価において自然な順序で処理が進むため、複雑な数式の計算に適しています。一方で、レジスタベースのアーキテクチャと比較すると、メモリアクセスが多くなるため、実行速度が低下する場合があります。
逆ポーランド記法(RPN: Reverse Polish Notation)は、スタック型オペランドと密接に関連する概念です。この記法では、演算子をオペランドの後に記述し、スタックを使用して自然に評価できます。計算機科学教科書では、この記法とスタック処理の関係について詳しく説明されています。
命令セットアーキテクチャとオペランド設計
プロセッサの命令セットアーキテクチャ(ISA: Instruction Set Architecture)は、オペランドの設計と密接に関連しています。異なるアーキテクチャでは、オペランドの扱い方や複雑さが大きく異なります。
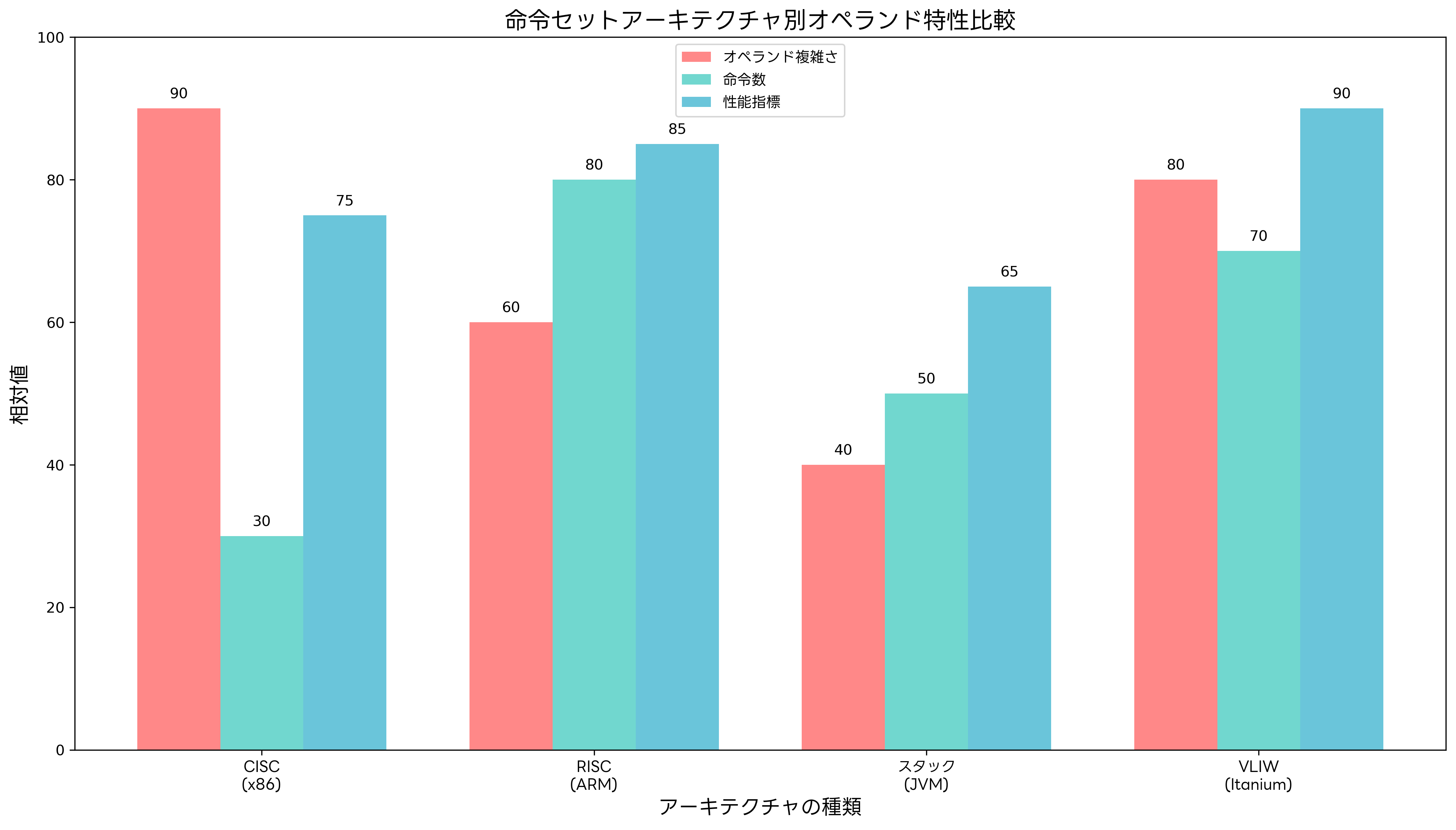
CISC(Complex Instruction Set Computer)アーキテクチャは、複雑で多機能な命令を特徴とし、オペランドも多様な形式をサポートします。x86アーキテクチャは代表的なCISCプロセッサであり、メモリ・メモリ型操作、複雑なアドレッシングモード、可変長命令などを提供します。x86プロセッサ搭載PCでは、このような豊富なオペランド形式を活用した高度なプログラミングが可能です。
RISC(Reduced Instruction Set Computer)アーキテクチャは、シンプルで高速な命令の実行を重視し、オペランドの形式も簡素化されています。ARMやMIPSなどのRISCプロセッサでは、レジスタ・レジスタ型操作が基本となり、メモリアクセスは専用のロード・ストア命令で行います。ARM搭載モバイルデバイスでは、この効率的なオペランド処理により低消費電力動作を実現しています。
VLIW(Very Long Instruction Word)アーキテクチャは、複数の操作を並列実行するために、一つの命令に多数のオペランドを含みます。Intelのイタニウムプロセッサは代表的なVLIW実装であり、コンパイラによる静的スケジューリングにより高い並列性を実現します。高性能サーバーでは、このような並列処理能力を活用した高速計算が可能です。
スーパースカラアーキテクチャでは、複数の実行ユニットがそれぞれ異なるオペランドを並列処理し、命令レベル並列性(ILP: Instruction Level Parallelism)を実現します。現代のプロセッサでは、アウトオブオーダー実行やレジスタリネーミングなどの技術により、オペランド間の依存関係を動的に解決し、高い性能を実現しています。
メモリ階層とオペランドアクセス最適化
オペランドのアクセス性能は、メモリ階層の構造と密接に関連しています。プロセッサから見たメモリ階層は、アクセス速度と容量のトレードオフによって構成され、オペランドの配置場所によって実行性能が大きく左右されます。
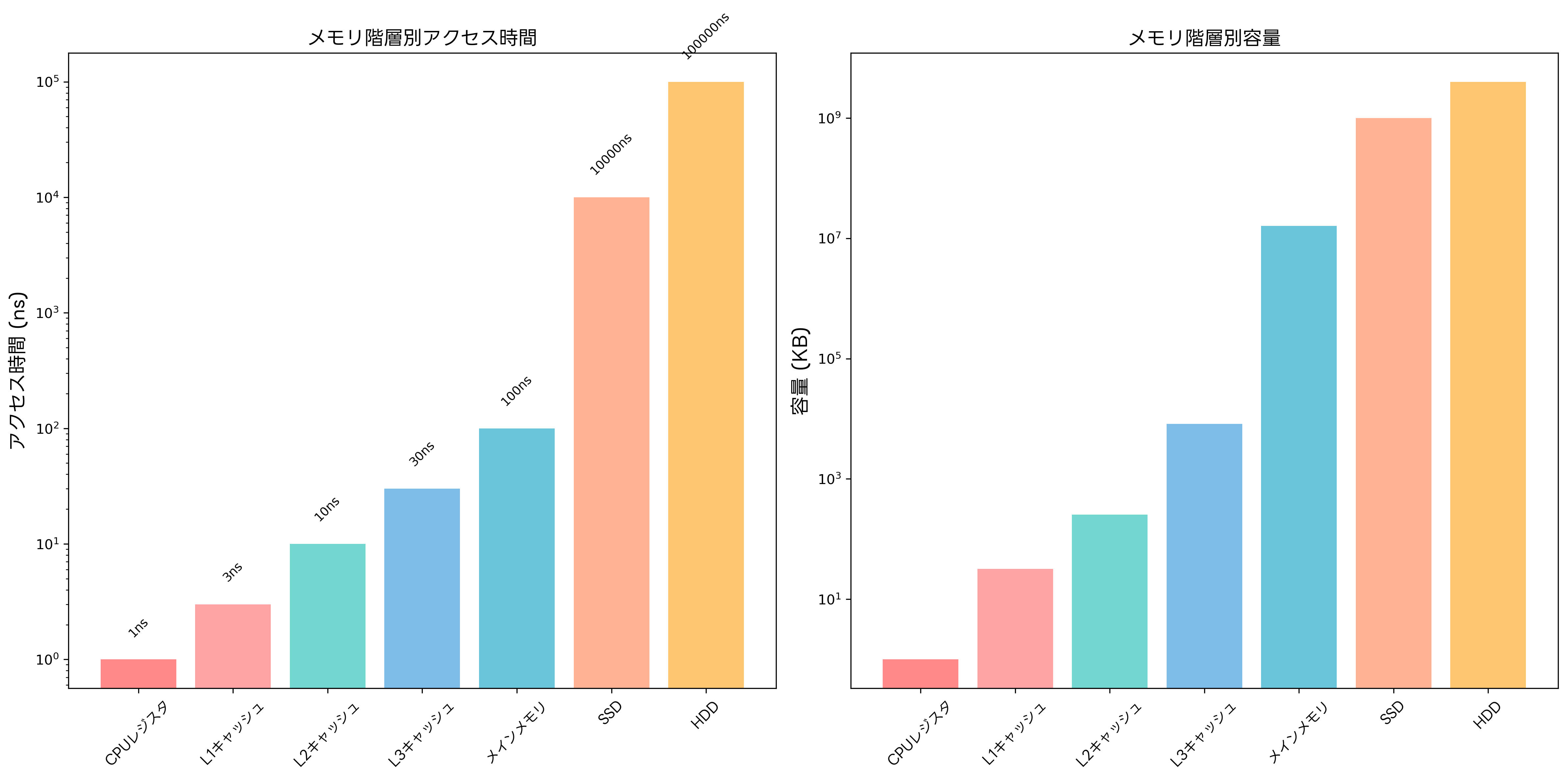
レジスタファイルは最も高速なオペランド格納場所であり、1クロックサイクル以下でアクセス可能です。現代のプロセッサでは、多数の汎用レジスタと専用レジスタを搭載し、頻繁に使用されるオペランドをレジスタに保持することで高速処理を実現しています。高クロック周波数プロセッサでは、このレジスタアクセスの高速性が全体性能に大きく影響します。
キャッシュメモリは、主記憶装置よりも高速でレジスタよりも大容量のストレージとして、オペランドの中間的な格納場所として機能します。L1、L2、L3キャッシュの階層構造により、アクセス頻度の高いオペランドを高速メモリに保持し、全体的なアクセス時間を短縮します。大容量キャッシュ搭載プロセッサでは、複雑なアプリケーションでも高い性能を維持できます。
主記憶装置(RAM)は大容量のオペランド格納場所として機能しますが、アクセス時間はキャッシュと比較して長くなります。DDR4やDDR5などの高速メモリ技術により、主記憶装置のアクセス性能は継続的に向上しています。高速メモリモジュールの採用により、大規模なデータセットを扱うアプリケーションでも効率的な処理が可能になります。
ストレージデバイス(SSD/HDD)は最も大容量でありながら最も低速なオペランド格納場所です。仮想メモリシステムにより、物理メモリ不足時にはストレージが拡張メモリとして使用されますが、アクセス時間は大幅に増加します。高速SSDの採用により、このような場合でも性能低下を最小限に抑えることができます。
並列処理とオペランドの依存関係
現代のプロセッサでは、複数の命令を並列実行することで性能向上を図っています。しかし、オペランド間の依存関係により、並列実行が制限される場合があります。これらの依存関係を理解し、適切に処理することが高性能システムの設計において重要です。
データ依存関係(Data Dependency)は、ある命令の結果が後続の命令のオペランドとして使用される場合に発生します。真の依存関係(True Dependency)、反依存関係(Anti-dependency)、出力依存関係(Output Dependency)の3種類があり、それぞれ異なる対処法が必要です。並列処理システムでは、これらの依存関係を効率的に解決する仕組みが実装されています。
制御依存関係(Control Dependency)は、分岐命令の結果によって実行される命令が決まる場合に発生します。分岐予測技術により、予測的に命令を実行し、予測が外れた場合には結果を破棄することで、制御依存関係による性能低下を軽減します。分岐予測機能付きプロセッサでは、高い予測精度により優れた性能を実現しています。
レジスタリネーミング(Register Renaming)は、偽の依存関係を解決するための技術です。プログラムで指定されたアーキテクチャレジスタを、より多数の物理レジスタにマッピングすることで、反依存関係と出力依存関係を排除し、並列実行の機会を増やします。アウトオブオーダー実行プロセッサでは、この技術により高い命令レベル並列性を実現しています。
応用情報技術者試験での出題傾向
応用情報技術者試験において、オペランドに関する問題は主にコンピュータシステムの分野で出題されます。アーキテクチャの基本概念、アドレッシングモード、データ型、性能評価などの観点から幅広く問われます。
午前問題では、オペランドの定義、アドレッシングモードの種類と特徴、命令フォーマット、レジスタとメモリの使い分けなどが出題されます。例えば、「間接アドレッシングモードの動作を説明せよ」や「CISC とRISCのオペランド処理の違いは何か」といった問題が頻出します。応用情報技術者試験対策書では、これらの基本概念を体系的に学習できます。
午後問題では、より実践的な文脈でオペランドの知識が問われます。プログラムの最適化、システム性能の評価、アーキテクチャ設計の比較などの問題において、オペランドに関する深い理解が求められます。特に、メモリアクセスパターンの最適化や並列処理における依存関係の解析などは、重要な出題テーマです。
試験対策としては、理論的な知識に加えて、実際のプロセッサアーキテクチャの事例を学習することが効果的です。コンピュータアーキテクチャ専門書やプロセッサ設計解説書を参考にして、具体的な実装例とともに概念を理解することが重要です。
最新技術動向とオペランドの進化
コンピュータ技術の進歩とともに、オペランドの概念と実装も継続的に進化しています。新しいアーキテクチャや技術により、より効率的で柔軟なオペランド処理が実現されています。
ベクトル処理とSIMD(Single Instruction, Multiple Data)技術では、一つの命令で複数のデータ要素を同時に処理するオペランドが使用されます。現代のプロセッサに搭載されるAVX、SSE、NEONなどの拡張命令セットでは、128ビットから512ビットの幅広いベクトルオペランドをサポートし、並列データ処理を実現しています。SIMD対応プロセッサでは、画像処理や科学計算において大幅な性能向上が可能です。
GPU(Graphics Processing Unit)アーキテクチャでは、大量の並列処理ユニットが独立したオペランドセットを処理し、高度な並列計算を実現しています。CUDA やOpenCLなどのプログラミングモデルでは、スレッドレベルでのオペランド管理が重要な概念となっています。高性能GPUを活用することで、従来のCPUでは困難だった大規模並列処理が可能になります。
人工知能(AI)専用プロセッサでは、ニューラルネットワークの演算に特化したオペランド処理が実装されています。テンソル演算、行列乗算、畳み込み演算などに最適化されたオペランド形式により、機械学習アルゴリズムの高速実行を実現しています。AI専用チップでは、従来のプロセッサでは実現できない効率的なAI処理が可能です。
量子コンピュータでは、従来のビット単位オペランドとは根本的に異なる量子ビット(qubit)オペランドが使用されます。重ね合わせ状態やもつれ状態などの量子力学的性質を活用した演算により、特定の問題において指数的な高速化が期待されています。量子コンピュータ技術書では、この革新的なオペランド概念について詳しく説明されています。
プログラミング言語とオペランドの抽象化
高級プログラミング言語では、機械語レベルのオペランドは抽象化され、より理解しやすい形で表現されます。しかし、効率的なプログラムを作成するためには、背後にあるオペランド処理の仕組みを理解することが重要です。
C言語では、ポインタやアドレス演算により、オペランドの低レベル制御が可能です。メモリアドレッシングや配列アクセスにおいて、機械語レベルのオペランド処理との対応が明確であり、システムプログラミングにおいて重要な概念です。Cプログラミング専門書では、このような低レベル操作について詳しく解説されています。
Java や C#などの管理された言語では、メモリ管理やアドレス操作が抽象化され、プログラマはより高レベルの概念に集中できます。しかし、ガベージコレクションやJIT(Just-In-Time)コンパイルにより、実行時にオペランドの最適化が行われています。Java仮想マシン解説書では、このような動的最適化の仕組みが説明されています。
関数型プログラミング言語では、不変オペランドと純粋関数により、副作用のない計算モデルを実現しています。Haskell や Scala などの言語では、遅延評価や型システムにより、オペランドの評価タイミングと型安全性を制御します。関数型プログラミング入門書では、これらの概念について体系的に学習できます。
システム最適化とオペランド配置戦略
高性能なシステムを設計するためには、オペランドの配置と使用パターンを最適化することが重要です。メモリ階層、キャッシュ効率、並列処理などを考慮した戦略的なオペランド管理により、システム全体の性能を向上させることができます。
データローカリティ(Data Locality)の原理に基づいて、関連するオペランドを近接したメモリ位置に配置することで、キャッシュヒット率を向上させることができます。時間的局所性(Temporal Locality)と空間的局所性(Spatial Locality)を活用したデータ構造設計により、メモリアクセスの効率化を図ります。システム最適化ガイドでは、このような最適化技法について詳しく説明されています。
プリフェッチング(Prefetching)技術により、将来使用されるオペランドを事前にキャッシュに読み込むことで、メモリアクセスレイテンシを隠蔽できます。ハードウェアプリフェッチャーとソフトウェアプリフェッチ命令を組み合わせることで、複雑なアクセスパターンにも対応できます。高性能コンピューティング書籍では、これらの高度な最適化技術が解説されています。
まとめ
オペランドは、コンピュータシステムの基本的な構成要素として、プロセッサの動作原理を理解する上で極めて重要な概念です。機械語命令におけるオペランドの役割から、現代の高度な並列処理システムでの複雑なオペランド管理まで、その理解の深さが システム設計や プログラミングの効率性に直結します。
応用情報技術者試験においては、オペランドに関する基本概念から応用まで幅広い知識が求められます。アドレッシングモード、データ型、メモリ階層、並列処理における依存関係など、多角的な理解が必要です。これらの知識は、単なる試験対策にとどまらず、実際のシステム開発や性能最適化において実践的な価値を持ちます。
技術の進歩とともに、オペランドの概念も継続的に進化しています。ベクトル処理、GPU コンピューティング、AI専用プロセッサ、量子コンピュータなど、新しいアーキテクチャでは革新的なオペランド処理方式が導入されています。これらの最新技術を理解し、将来の発展を見据えた知識の習得が、情報技術者として の成長につながります。
効率的なシステム設計と最適化のためには、オペランドレベルでの深い理解と、それを活用した戦略的なアプローチが不可欠です。理論的な知識と実践的な経験を組み合わせることで、高性能で信頼性の高いコンピュータシステムの構築が可能になります。