現代のIT運用において、サービスレベルの管理と保証は企業の成功を左右する重要な要素となっています。特に、SLA(Service Level Agreement)とSLO(Service Level Objective)は、サービス提供者と利用者の間で品質保証を明確化し、継続的な改善を実現するための核心的な概念です。応用情報技術者試験においても、これらの概念は運用管理やサービスマネジメント分野で頻繁に出題される重要なトピックです。
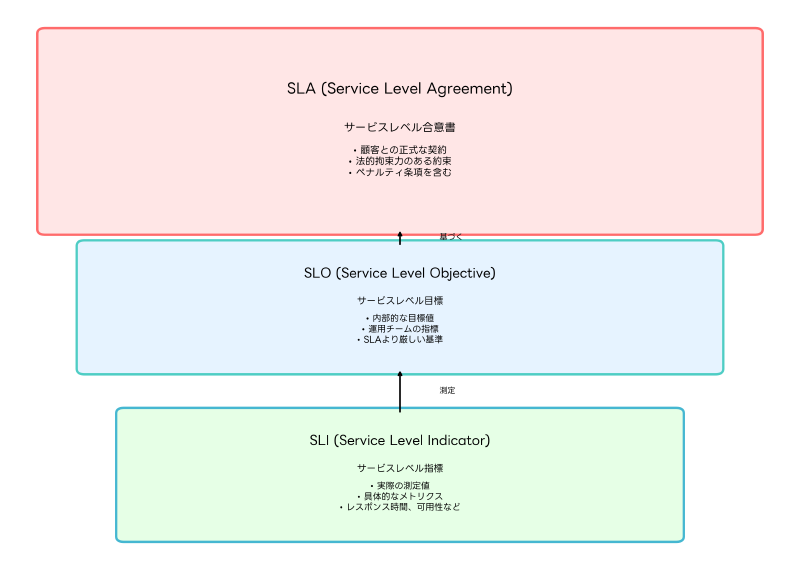
SLAとSLOは密接に関連しながらも、それぞれ異なる役割を持っています。SLAは顧客との正式な契約書として法的拘束力を持ち、SLOは内部的な目標値として運用チームの指針となります。また、これらの基盤となるSLI(Service Level Indicator)は、実際のサービス性能を数値化したメトリクスであり、客観的な評価を可能にします。
SLA(Service Level Agreement):顧客との約束を明文化
SLAは、サービス提供者と顧客の間で締結される正式な合意書であり、提供されるサービスの品質レベルを明確に定義します。この合意書には、可用性、性能、対応時間、復旧時間などの具体的な数値目標が含まれ、これらの目標を下回った場合のペナルティや補償についても規定されています。
SLAの策定においては、顧客のビジネス要件と技術的な実現可能性のバランスを取ることが重要です。過度に厳しい目標を設定すると、実現のためのコストが膨大になり、逆に緩すぎる目標では顧客満足を得られません。効果的なSLA策定のためには、プロフェッショナル向けのサービスレベル管理ツールを活用し、過去のパフォーマンスデータを分析することが推奨されます。
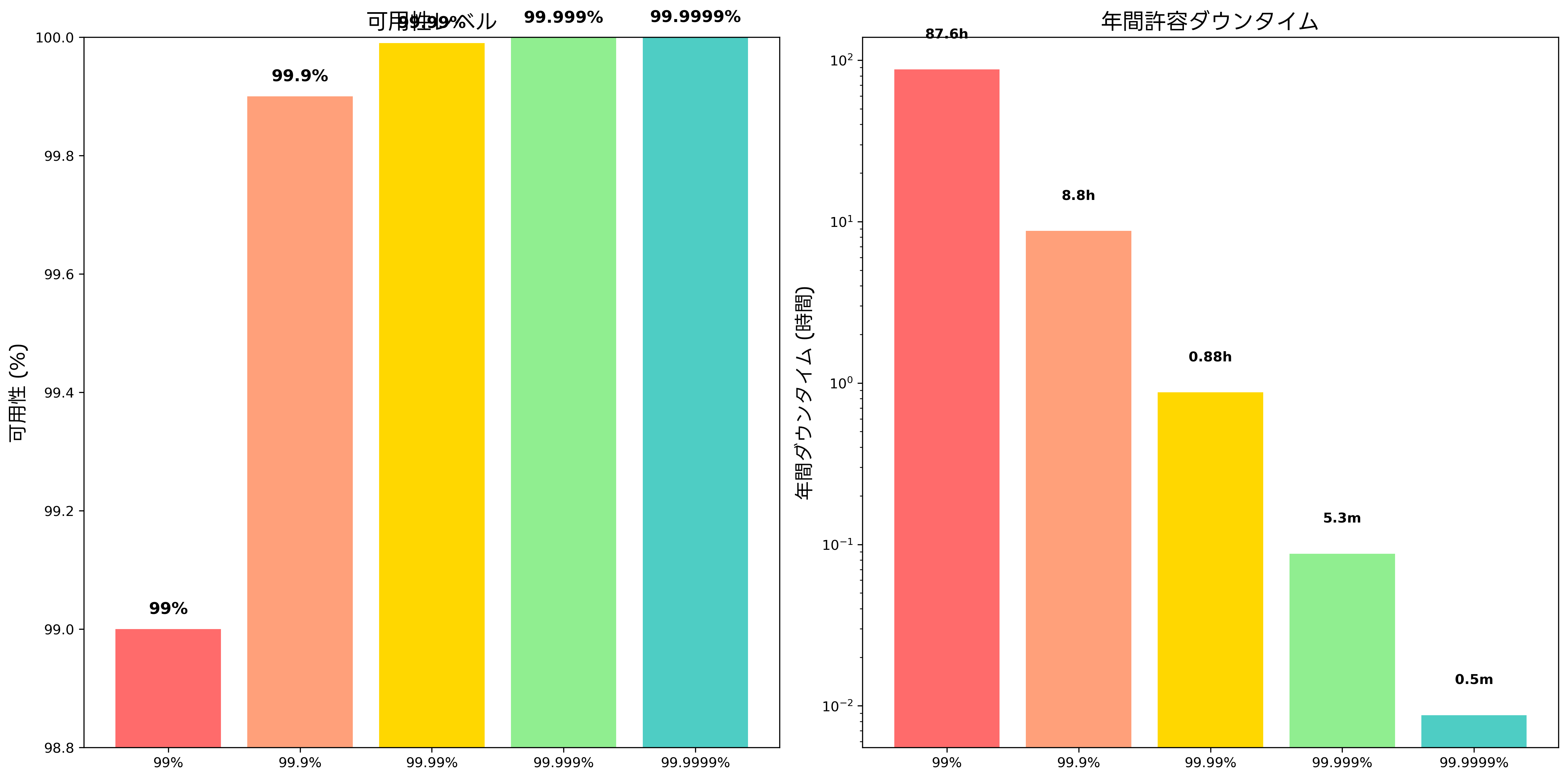
可用性の指標は、SLAにおいて最も重要な要素の一つです。99.9%の可用性は年間8.76時間のダウンタイムを意味し、99.99%では52.56分、99.999%では5.26分となります。金融機関のような重要なシステムでは99.99%以上の可用性が求められることが多く、そのためには高可用性システム構築のための専門機器への投資が必要になります。
SLAの違反が発生した場合の対応手順も重要な要素です。インシデントの検知から顧客への報告、復旧作業、事後分析まで、一連のプロセスを明確に定義する必要があります。また、違反の重要度に応じたエスカレーション手順も設定し、適切な人員とリソースを迅速に投入できる体制を整えることが重要です。
契約条項としてのSLAには、測定方法、除外条件、報告頻度なども詳細に規定されます。例えば、計画停止時間は可用性の計算から除外する、月次での報告を行う、第三者による監査を受け入れるなどの条項が含まれます。これらの条項を適切に管理するため、契約管理システムの導入により、SLAの履行状況を継続的に追跡することが推奨されます。
SLO(Service Level Objective):内部目標の設定と管理
SLOは組織内部で設定されるサービス品質の目標値であり、SLAよりも厳しい基準を設定することが一般的です。これにより、SLA違反を予防し、継続的なサービス改善を実現します。SLOは運用チームにとって日常的な指針となり、システムの健全性を維持するための重要な指標として機能します。
SLOの設定においては、ビジネス要件、技術的制約、コスト効率を総合的に考慮する必要があります。あまりに高い目標を設定すると、過度なエンジニアリング投資が必要になり、低すぎる目標では品質向上のインセンティブが働きません。適切なSLO設定のためには、性能監視ツールを活用して現在のパフォーマンスを正確に把握することが重要です。
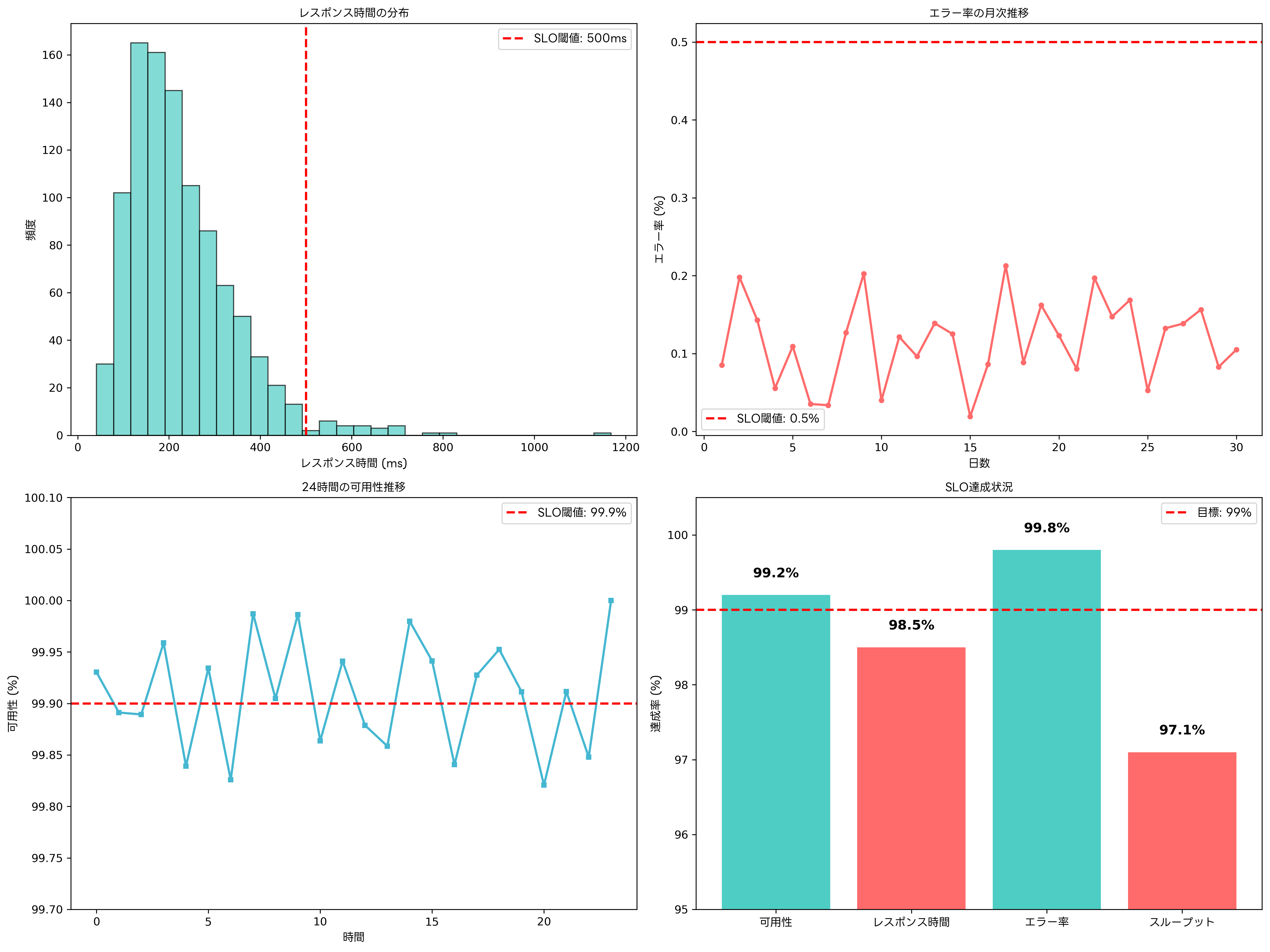
SLOの測定には、レスポンス時間、エラー率、可用性、スループットなどの複数のメトリクスが用いられます。レスポンス時間については、平均値だけでなく95パーセンタイルや99パーセンタイルも監視し、ユーザー体験の一貫性を確保します。エラー率は、システムの安定性を示す重要な指標であり、5xx系エラーだけでなく、4xx系エラーも含めた総合的な評価が必要です。
SLOの継続的な改善には、定期的なレビューと調整が不可欠です。ビジネス要件の変化、技術革新、ユーザー行動の変化などに応じて、SLOを適切に更新する必要があります。また、季節変動や特定のイベントによる負荷変動も考慮し、動的なSLO設定も検討されます。このような複雑な分析には、高度な分析プラットフォームの活用が効果的です。
組織内でのSLO共有と理解促進も重要です。開発チーム、運用チーム、ビジネスチームが共通の理解を持ち、SLO達成に向けて協力する文化を作ることが成功の鍵となります。定期的なSLOレビューミーティングの開催、ダッシュボードによる可視化、教育プログラムの実施などを通じて、組織全体でのSLO意識を高めることが重要です。
SLI(Service Level Indicator):客観的な測定指標
SLIは、サービスの性能を具体的に測定するための指標であり、SLOとSLAの基盤となります。適切なSLIの選択と正確な測定は、信頼できるサービス品質管理の前提条件です。SLIは、ユーザーの体験と直接関連する指標を選ぶことが重要であり、技術的な指標だけでなく、ビジネス的な価値も反映する必要があります。
代表的なSLIには、可用性(アップタイム/総時間)、レスポンス時間(リクエスト処理時間)、エラー率(失敗リクエスト/総リクエスト)、スループット(単位時間あたりの処理数)などがあります。これらの指標を正確に測定するためには、高精度な測定機器とリアルタイム監視システムの導入が不可欠です。
測定の精度と信頼性を確保するためには、複数の測定ポイントからのデータを統合し、異常値の除去やデータの正規化を行う必要があります。また、測定システム自体の可用性も重要であり、冗長化された監視インフラストラクチャの構築が推奨されます。クラウドベースの監視サービスを利用する場合は、マルチクラウド監視ソリューションにより、ベンダーロックインを避けながら高い可用性を実現できます。
SLIの履歴データは、長期的なトレンド分析と将来予測に活用されます。機械学習を活用した予測分析により、将来のボトルネックや性能劣化を事前に検知し、プロアクティブな対策を講じることが可能になります。このような高度な分析には、機械学習プラットフォームの活用が効果的です。
エラーバジェット:革新と安定性のバランス
エラーバジェットは、Site Reliability Engineering(SRE)の重要な概念であり、サービスの信頼性と革新のバランスを取るための仕組みです。SLOで設定された目標値と100%の完璧さの間の差分をエラーバジェットとして定義し、この範囲内であれば新機能のリリースや実験的な取り組みを許可します。
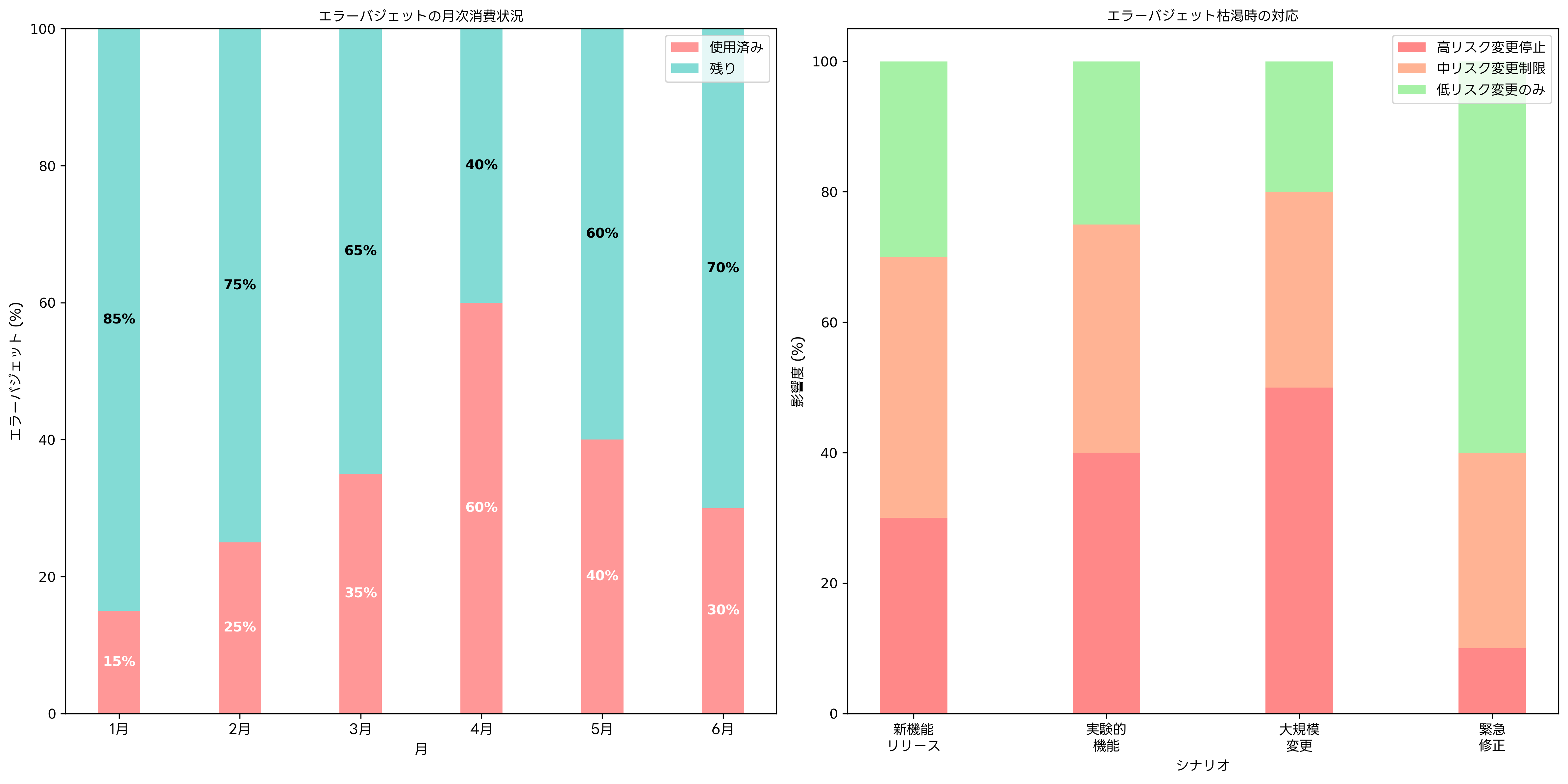
エラーバジェットの管理は、開発速度とサービス安定性の最適なバランスを実現します。バジェットに余裕がある場合は、積極的な新機能開発やアーキテクチャの改善に取り組むことができます。一方、バジェットが枯渇した場合は、安定性の向上に注力し、新しい変更を制限します。このような動的な運用方針により、ビジネス価値の最大化と品質保証の両立が可能になります。
エラーバジェットの効果的な活用には、組織全体での理解と合意が必要です。開発チーム、運用チーム、プロダクトマネジメントチームが共通の目標を持ち、バジェットの状況に応じて優先順位を調整する文化を構築することが重要です。また、バジェット消費の原因分析と改善策の実施により、継続的な品質向上を実現します。
エラーバジェットの計算と追跡には、自動化されたシステムの構築が推奨されます。自動化運用ツールを活用することで、リアルタイムでのバジェット状況の把握と、しきい値に達した際の自動アラートが可能になります。また、バジェットの履歴データを分析することで、最適なバジェット配分や期間設定を継続的に改善できます。
SLA違反の影響とコスト
SLA違反は、単なる技術的な問題を超えて、ビジネスに深刻な影響をもたらします。直接的な影響として、契約で定められたペナルティの支払い、顧客への補償、サービスクレジットの提供などがあります。間接的な影響として、顧客信頼の失墜、ブランドイメージの悪化、競合他社への顧客流出、新規顧客獲得の困難などが挙げられます。
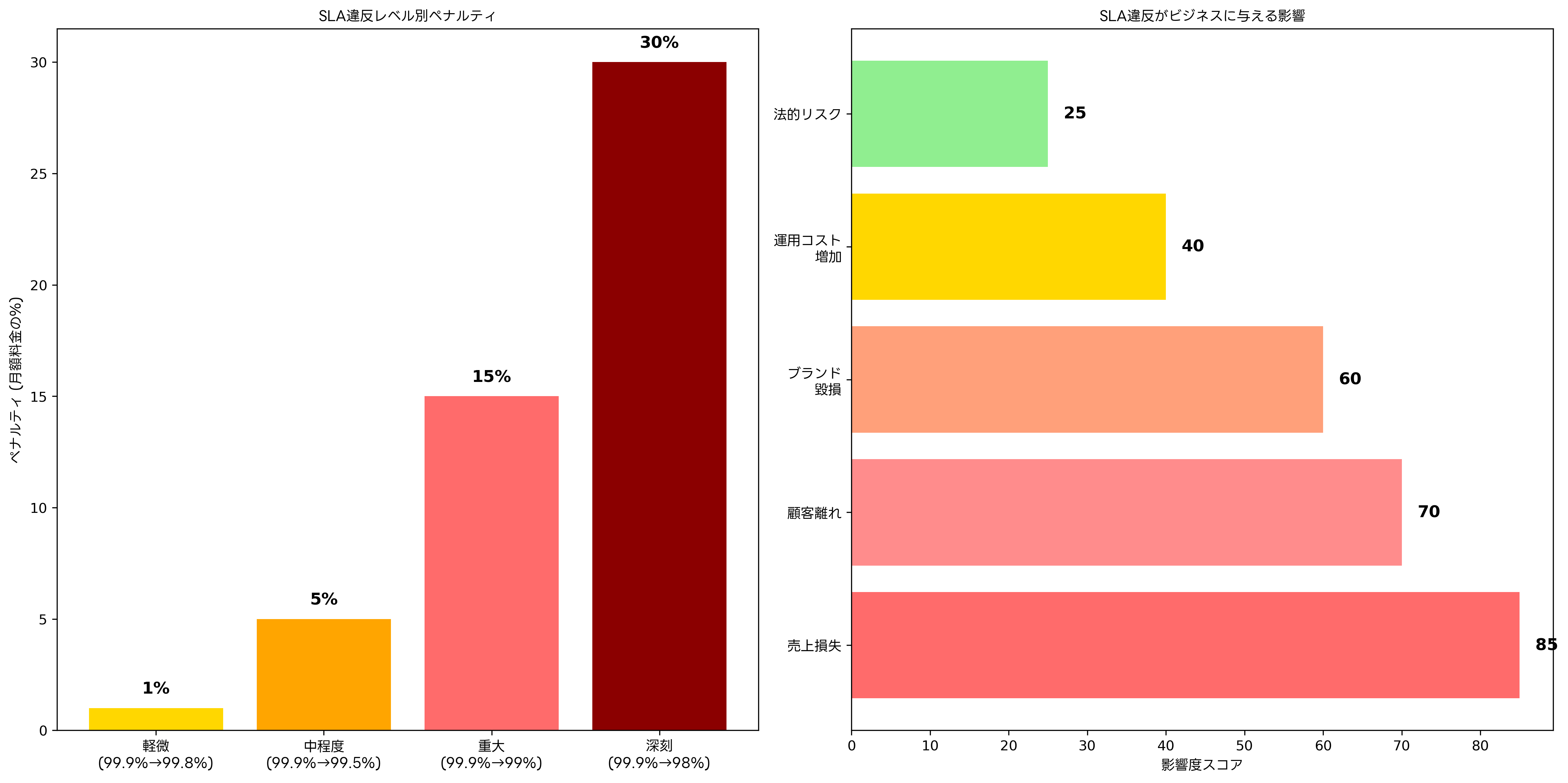
SLA違反のコストは、違反の程度と期間に比例して増加します。軽微な違反であっても、継続的に発生すると累積的な影響が大きくなります。また、重要な顧客や大規模な取引における違反は、その影響が組織全体に波及する可能性があります。そのため、SLA違反のリスクを最小化するための投資は、長期的な観点から見て極めて重要です。
SLA違反の予防には、プロアクティブな監視と早期警告システムの構築が不可欠です。予測分析ツールを活用することで、システムの異常を事前に検知し、違反が発生する前に対策を講じることが可能になります。また、定期的な災害復旧訓練や負荷テストにより、システムの耐障害性を継続的に検証することも重要です。
SLA違反が発生した場合の対応体制も重要です。インシデント管理プロセスの確立、エスカレーション手順の明確化、コミュニケーション計画の策定などにより、迅速かつ適切な対応を実現します。また、事後分析による根本原因の特定と再発防止策の実施により、同様の問題の発生を防ぐことができます。
SLO監視ダッシュボードの構築
効果的なSLO管理には、包括的な監視ダッシュボードの構築が不可欠です。ダッシュボードは、SLIの現在値、SLO達成状況、エラーバジェット残量、アラート状況などを一元的に表示し、運用チームが迅速な意思決定を行えるようにします。
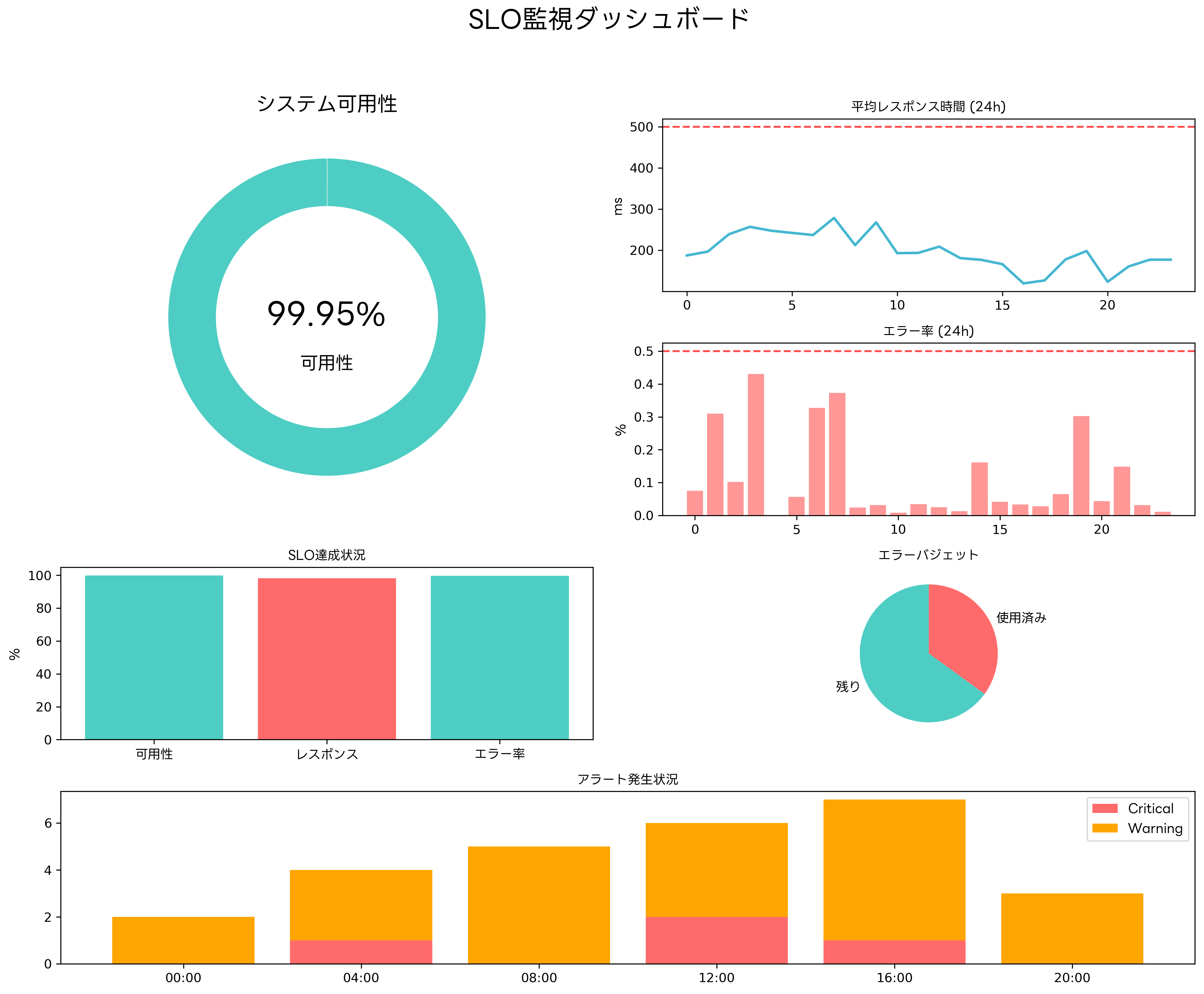
ダッシュボードの設計においては、情報の階層化と視覚化が重要です。高レベルの要約情報から詳細なメトリクスまで、段階的にドリルダウンできる構造により、効率的な問題特定と対応が可能になります。また、異なる役割の利用者に応じて、カスタマイズされたビューを提供することで、より効果的な情報活用が実現できます。
現代的なダッシュボードには、リアルタイムデータの表示、インタラクティブな操作、モバイル対応などの機能が求められます。最新のダッシュボードソリューションを活用することで、これらの要件を満たす高度な監視環境を構築できます。また、APIによる外部システム連携により、既存の運用ツールとの統合も可能になります。
ダッシュボードの運用においては、定期的なレビューと改善が重要です。利用者からのフィードバックを収集し、使いやすさの向上や新しい機能の追加を継続的に行います。また、組織の成長やシステムの変化に応じて、ダッシュボードの構成やメトリクスも適切に更新する必要があります。
応用情報技術者試験での出題傾向
応用情報技術者試験において、SLA/SLOに関する問題は主にサービスマネジメント分野で出題されます。午前問題では、SLA/SLO/SLIの定義、可用性の計算、ペナルティの算出、監視手法などの基礎知識が問われます。午後問題では、実際のシステム運用における課題解決や改善提案などの応用力が評価されます。
試験対策としては、ITILやISO/IEC 20000などのサービスマネジメントフレームワークとの関連性を理解することが重要です。ITIL関連の専門書やサービスマネジメントの教科書を活用して、理論的な基盤を固めることが推奨されます。
また、実際の業務経験がある場合は、自社のSLA/SLO運用を試験の観点から分析することで、理論と実践の橋渡しができます。ケーススタディ集を活用して、様々な業界や規模でのSLA/SLO運用事例を学ぶことも効果的です。
計算問題については、可用性とダウンタイムの換算、SLA達成率の計算、ペナルティ金額の算出などが頻出です。これらの計算を迅速かつ正確に行えるよう、繰り返し練習することが重要です。過去問題集を活用して、出題パターンを把握し、解答技術を向上させることが推奨されます。
クラウド時代のSLA/SLO
クラウドコンピューティングの普及により、SLA/SLOの概念と実装も大きく変化しています。クラウドサービスプロバイダーは、インフラストラクチャ、プラットフォーム、ソフトウェアの各レイヤーでSLAを提供し、利用者は自身のアプリケーションSLAとの整合性を確保する必要があります。
マルチクラウド環境では、複数のプロバイダーのSLAを組み合わせて、総合的なサービス品質を実現する必要があります。各プロバイダーのSLA条件、測定方法、補償内容を詳細に比較検討し、最適な組み合わせを選択することが重要です。クラウドサービス比較ツールを活用することで、効率的な比較分析が可能になります。
コンテナ化とマイクロサービスアーキテクチャの採用により、SLO設定の粒度も細かくなっています。各マイクロサービスに対して個別のSLOを設定し、サービス間の依存関係を考慮した全体最適化を行う必要があります。コンテナ監視ツールやマイクロサービス管理プラットフォームの活用により、複雑な環境でのSLO管理が実現できます。
サーバーレスコンピューティングでは、従来の可用性概念が適用しにくく、新しいSLI/SLO設計が必要になります。関数の実行時間、コールドスタート頻度、エラー率などの指標を組み合わせて、ユーザー体験を適切に反映するSLOを構築する必要があります。
DevOpsとSLA/SLO
DevOpsの文化と実践において、SLA/SLOは開発と運用の共通目標として重要な役割を果たします。従来の開発重視(機能追加優先)と運用重視(安定性優先)の対立を解消し、ビジネス価値の最大化に向けた協力関係を構築します。
継続的インテグレーション/継続的デプロイメント(CI/CD)パイプラインにSLO監視を組み込むことで、デプロイメントの品質と安全性を向上させることができます。新しいバージョンのデプロイ後にSLOが悪化した場合、自動的にロールバックを実行する仕組みにより、サービス品質の維持と迅速な機能提供の両立が可能になります。DevOps自動化ツールの活用により、このような高度な自動化が実現できます。
カナリアリリースやブルーグリーンデプロイメントなどの高度なデプロイ戦略も、SLO監視と組み合わせることで効果を発揮します。新バージョンのSLO状況を監視しながら段階的に展開することで、リスクを最小化しながら新機能を提供できます。
チーム間のコラボレーション向上のためには、SLOの共有と可視化が重要です。開発チームは自分たちのコードがSLOに与える影響を理解し、運用チームは開発チームのニーズを考慮したSLO設定を行います。定期的な合同レビューミーティングや、コラボレーションプラットフォームの活用により、効果的なチーム間連携が実現できます。
AIと機械学習によるSLO最適化
人工知能と機械学習技術の活用により、SLO管理の精度と効率性が大幅に向上しています。過去のパフォーマンスデータを分析して将来の傾向を予測し、プロアクティブな対策を講じることが可能になります。また、異常検知アルゴリズムにより、従来の固定しきい値では検出できない微細な変化も捉えることができます。
動的SLO調整は、AI技術の重要な応用分野です。負荷パターン、季節変動、特殊イベントなどの要因を考慮して、SLOを自動的に調整することで、より現実的で達成可能な目標設定が実現できます。AI搭載監視システムを導入することで、このような高度な機能を活用することができます。
根本原因分析においても、機械学習は威力を発揮します。大量のログデータ、メトリクス、イベント情報を統合的に分析し、SLO悪化の真の原因を迅速に特定できます。これにより、修復時間の短縮と再発防止の精度向上が実現できます。
予測的メンテナンスとの連携により、SLO違反を事前に防ぐことも可能になります。システムコンポーネントの劣化兆候を検知し、パフォーマンスが低下する前に適切なメンテナンスを実施することで、計画的なサービス品質管理が実現できます。予測メンテナンスソリューションの導入により、このような先進的な運用が可能になります。
グローバル展開におけるSLA/SLO
グローバルに展開するサービスでは、地域ごとの特性を考慮したSLA/SLO設計が必要になります。ネットワーク遅延、法的要件、文化的差異、インフラストラクチャの成熟度などの要因により、同一のSLOを全地域に適用することは困難です。
地域別SLO設定においては、各地域のベースラインパフォーマンスを正確に把握することが重要です。ネットワーク品質、データセンターの可用性、第三者サービスの依存関係などを総合的に評価し、現実的な目標値を設定します。グローバル監視ソリューションを活用することで、世界規模でのパフォーマンス測定と管理が可能になります。
タイムゾーンの違いは、SLO管理とインシデント対応に重要な影響を与えます。24時間365日のサービス提供を実現するためには、複数拠点でのFollow-the-Sun体制の構築や、自動化による夜間対応能力の向上が必要です。また、地域ごとの祝日やメンテナンス窓口も考慮した運用計画の策定が重要です。
規制要件の違いも、SLA/SLO設計に影響を与えます。データ保護規制、金融規制、医療規制などにより、各地域で異なる品質要件が課せられる場合があります。コンプライアンス管理ツールの活用により、複雑な規制環境でのSLA/SLO管理が実現できます。
まとめ
SLA/SLOは、現代のITサービス運用において不可欠な概念です。適切な設定と管理により、顧客満足の向上、運用効率の改善、ビジネス価値の最大化を実現することができます。応用情報技術者試験においても重要なトピックであり、理論的理解と実践的応用能力の両方が求められます。
技術の進歩とビジネス環境の変化に伴い、SLA/SLOの実装方法も継続的に進化しています。クラウドコンピューティング、DevOps、AI/ML、グローバル展開などの新しい要素を考慮しながら、組織の特性に最適化されたアプローチを採用することが重要です。
継続的な学習と改善により、変化する要件に対応できる能力を身につけることで、競争優位を維持し、顧客価値を継続的に提供することができます。SLA/SLOは単なる技術的指標ではなく、ビジネス成功のための戦略的ツールとして活用することが重要です。