現代のITシステムにおいて、耐障害性(Fault Tolerance)は極めて重要な概念です。ビジネスが24時間365日稼働することが当たり前となった今日、システムの停止は企業の存続に関わる重大な問題となります。応用情報技術者試験においても、耐障害性に関する理解は必須の知識として位置づけられており、システム設計から運用まで幅広い分野で活用される基本概念です。
耐障害性とは、システムの一部に障害が発生しても、全体のサービスを継続できる能力のことです。完全に障害を防ぐことは不可能ですが、適切な設計により障害の影響を最小限に抑え、迅速な復旧を実現することが可能です。この概念は、システムの可用性、信頼性、保守性を向上させる基盤となります。
耐障害性の基本概念と重要性
耐障害性の実現には、障害を前提としたシステム設計が必要です。従来の「障害を起こさない」という発想から、「障害が起きても止まらない」という発想への転換が重要です。この考え方は、クラウドコンピューティングの普及とともに、より一層重要性を増しています。
システムの障害は様々な要因で発生します。ハードウェアの故障、ソフトウェアのバグ、ネットワークの切断、電源の問題、人的ミス、自然災害など、多岐にわたる脅威が存在します。これらの脅威に対処するため、高性能なサーバー監視システムやネットワーク冗長化機器の導入が欠かせません。
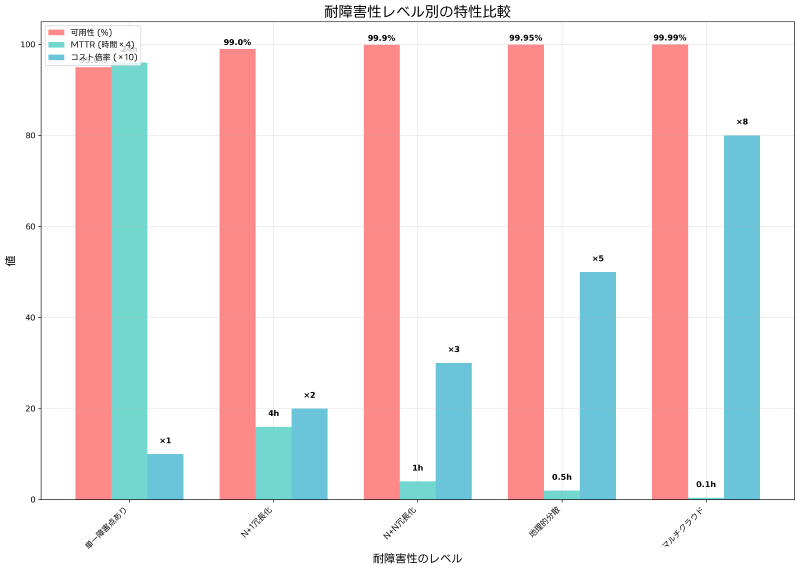
耐障害性の評価指標には、可用性(Availability)、信頼性(Reliability)、保守性(Maintainability)があります。可用性は「システムが正常に動作している時間の割合」を示し、一般的にパーセンテージで表現されます。99.9%の可用性は年間8.77時間のダウンタイムを意味し、99.99%では年間52.6分のダウンタイムとなります。
信頼性は「システムが故障せずに動作し続ける能力」を表し、MTBF(Mean Time Between Failures:平均故障間隔)で測定されます。保守性は「故障したシステムを修復する容易さ」を示し、MTTR(Mean Time To Repair:平均修復時間)で評価されます。これらの指標を向上させるため、専用の診断ツールや保守管理ソフトウェアの活用が効果的です。
システム構成による耐障害性の実現
耐障害性を実現するための基本的なアプローチは、システムの冗長化です。単一障害点(Single Point of Failure:SPOF)を排除し、コンポーネントの一つが故障しても他のコンポーネントがその機能を代替できるよう設計します。
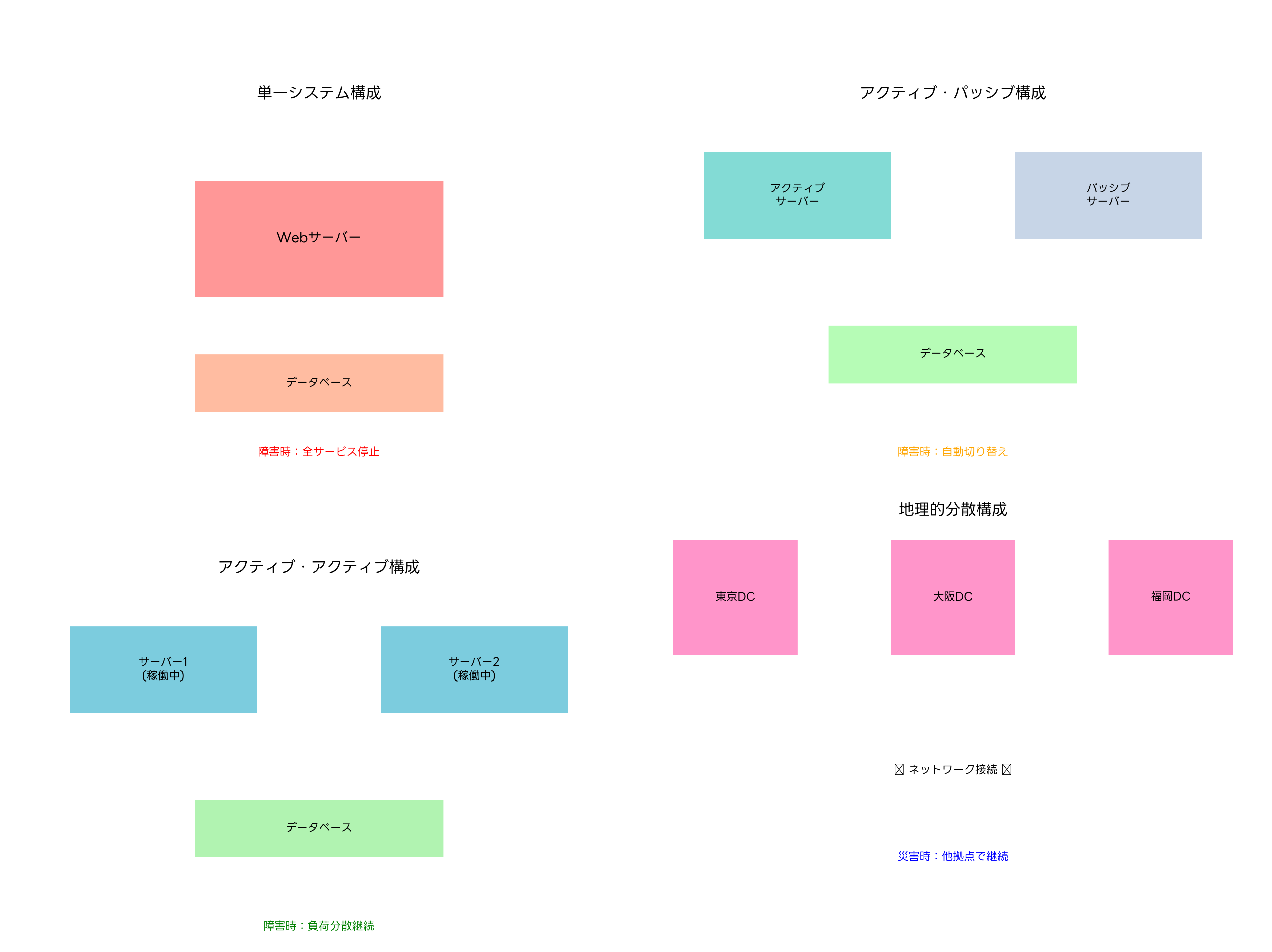
最も基本的な冗長化手法は、アクティブ・パッシブ構成です。この構成では、通常時は一つのシステム(アクティブ)が稼働し、もう一つのシステム(パッシブ)は待機状態で保持されます。アクティブシステムに障害が発生すると、パッシブシステムが自動的に処理を引き継ぎます。この構成を実現するため、高可用性クラスターソフトウェアや自動フェイルオーバーシステムの導入が必要です。
より高度な冗長化手法として、アクティブ・アクティブ構成があります。この構成では、複数のシステムが同時に稼働し、負荷を分散して処理します。一つのシステムに障害が発生しても、残りのシステムが処理を継続するため、性能の低下は発生しますが、サービスの停止は避けられます。
地理的分散は、自然災害や大規模な電源障害に対する最も効果的な対策です。複数の地域にデータセンターを設置し、データとシステムを分散配置することで、一つの地域が被災しても他の地域でサービスを継続できます。このような構成を支援する地理的分散ストレージシステムや災害復旧ソリューションの活用が重要です。
障害の種類と対策手法
システムに発生する障害は、その原因や影響によって様々に分類されます。ハードウェア障害は最も頻繁に発生する障害の一つで、CPUの故障、メモリの異常、ストレージの破損、電源ユニットの故障などが含まれます。これらの障害に対処するため、冗長化されたハードウェア構成やホットスワップ対応機器の導入が効果的です。
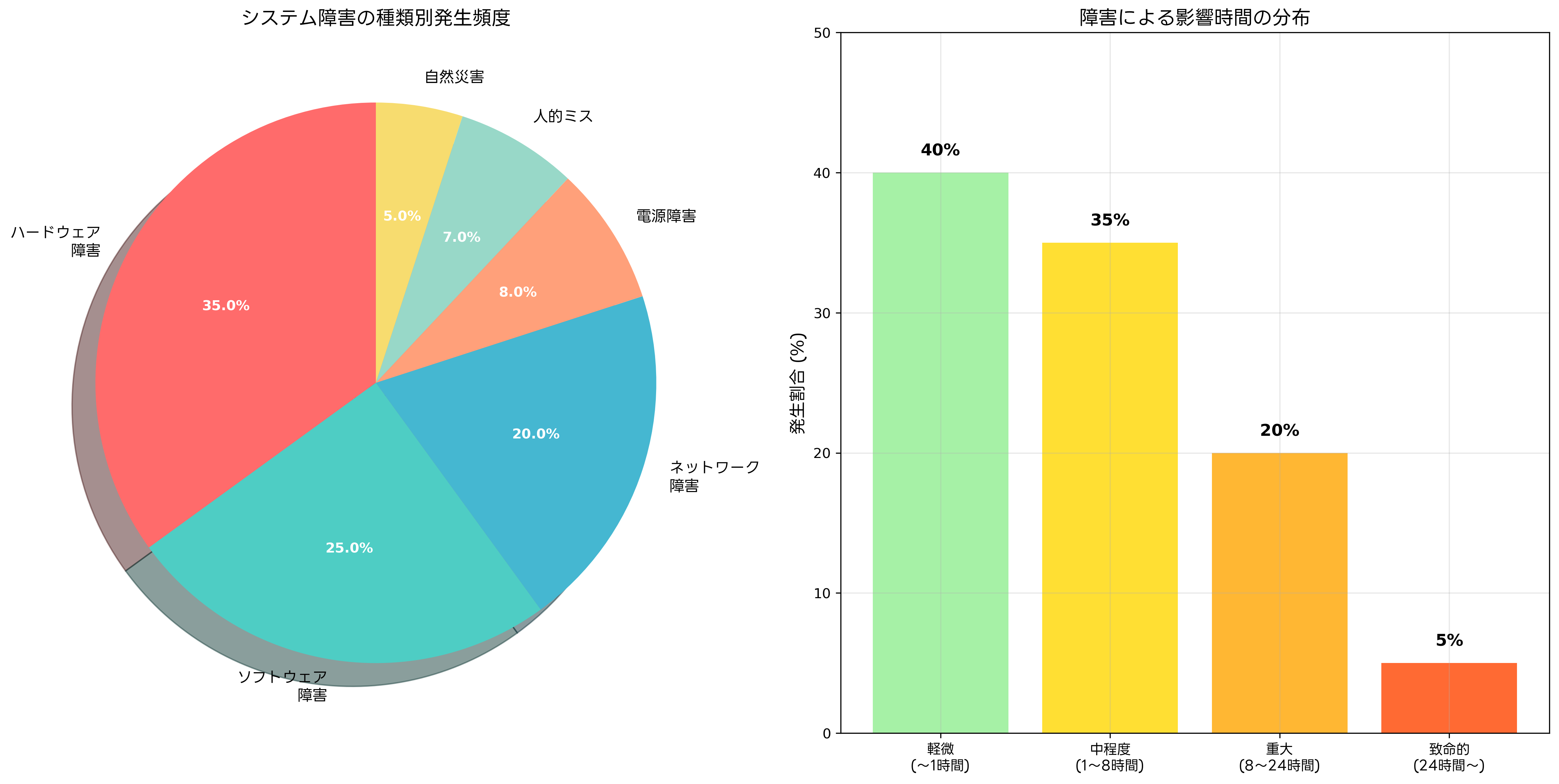
ソフトウェア障害は、アプリケーションのバグ、OSの不具合、設定ミス、メモリリークなどが原因で発生します。これらの障害を防ぐため、厳格なテスト手順の実装、自動テストツールの活用、コード品質管理システムの導入が重要です。また、障害発生時の迅速な対応のため、インシデント管理システムの整備も欠かせません。
ネットワーク障害は、通信回線の切断、ルーターやスイッチの故障、設定ミス、帯域不足などが原因で発生します。ネットワークの冗長化により、複数の通信経路を確保し、一つの経路に障害が発生しても他の経路で通信を継続できます。ネットワーク冗長化装置やSD-WANソリューションの導入により、柔軟で信頼性の高いネットワーク構成を実現できます。
電源障害は、停電、電圧変動、電源ユニットの故障などが原因で発生します。無停電電源装置(UPS)の設置により、短時間の停電に対応できますが、長時間の停電には非常用発電機の併用が必要です。また、データセンターレベルでは、冗長化された電源システムの導入により、電源の単一障害点を排除できます。
耐障害性設計の具体的手法
効果的な耐障害性設計には、複数の技術的手法を組み合わせたアプローチが必要です。冗長化は最も基本的で重要な手法で、システムの各層において実装する必要があります。サーバーレベルでは、複数のサーバーによるクラスター構成、ストレージレベルでは、RAIDによるディスクの冗長化、ネットワークレベルでは、複数の通信経路の確保が重要です。
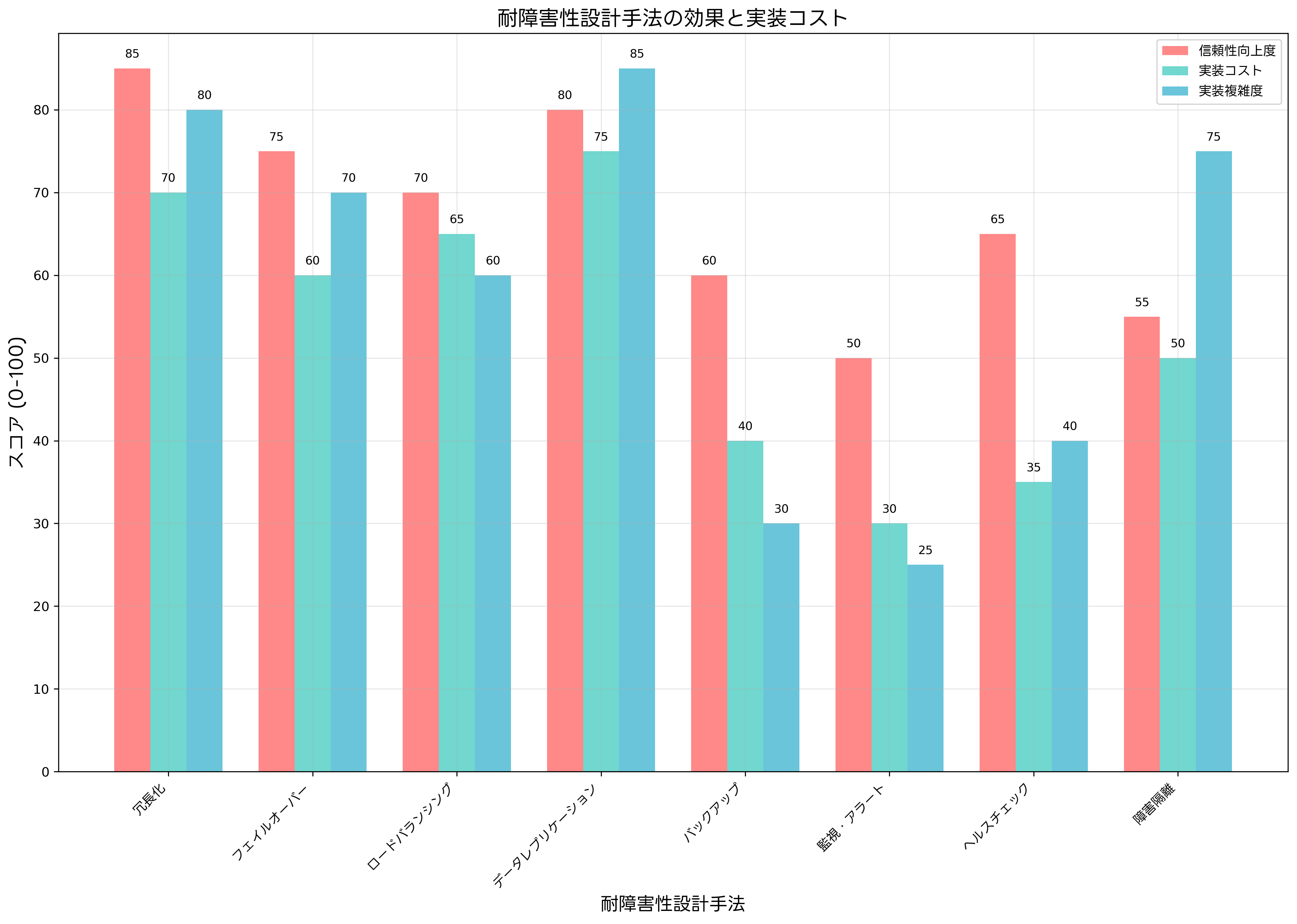
フェイルオーバー機能は、障害発生時の自動切り替えを実現する重要な機能です。アクティブなシステムの監視を常時行い、異常を検出すると即座にパッシブシステムに処理を移行します。この機能を効率的に実装するため、フェイルオーバークラスターソフトや高可用性監視ツールの活用が推奨されます。
ロードバランシングは、複数のサーバーに負荷を分散することで、特定のサーバーへの過負荷を防ぎ、一つのサーバーに障害が発生しても他のサーバーで処理を継続できます。負荷分散の手法には、ラウンドロビン、重み付きラウンドロビン、最小接続数、応答時間ベースなどがあり、システムの特性に応じて最適な手法を選択します。
データレプリケーションは、データの複製を複数の場所に保持することで、データの可用性と整合性を保証します。同期レプリケーションでは、すべての複製に同時に書き込みを行うため整合性は保たれますが、性能への影響があります。非同期レプリケーションでは、性能への影響は少ないものの、一時的な不整合が生じる可能性があります。企業向けデータレプリケーションソフトを活用することで、効率的なレプリケーション環境を構築できます。
ヘルスチェック機能は、システムの正常性を継続的に監視し、異常を早期に検出するための仕組みです。定期的にシステムの各コンポーネントの状態を確認し、応答時間、エラー率、リソース使用率などの指標を監視します。異常が検出されると、アラートの発信や自動復旧処理を実行します。統合監視ソリューションにより、包括的なヘルスチェック環境を実現できます。
可用性レベルとコストの関係
耐障害性の向上には、それに見合ったコストが必要です。可用性のレベルを高めるほど、実装コストと運用コストが指数関数的に増加する傾向があります。そのため、ビジネス要件とコストのバランスを考慮した設計が重要です。
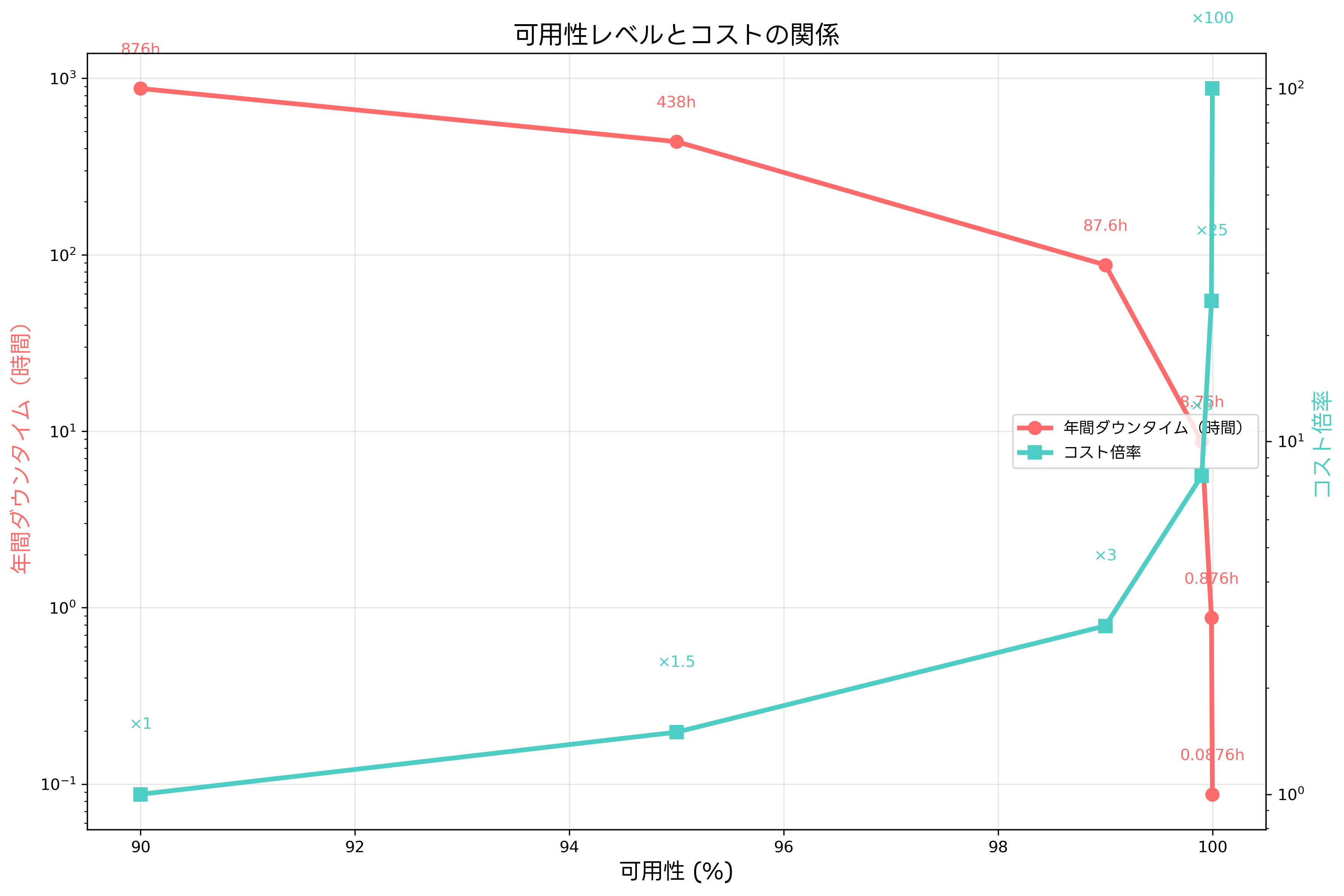
99%の可用性を実現するシステムは、年間87.6時間のダウンタイムが許容されます。このレベルは比較的低コストで実現でき、基本的な冗長化と監視システムの導入で達成可能です。一方、99.99%の可用性を実現するには、年間52.6分以下のダウンタイムに抑える必要があり、高度な冗長化、自動フェイルオーバー、地理的分散などの対策が必要となり、コストは大幅に増加します。
システムの重要度に応じて、適切な可用性レベルを設定することが重要です。ミッションクリティカルなシステムでは99.99%以上の可用性が求められる場合がありますが、そうでないシステムでは99.9%程度の可用性で十分な場合もあります。可用性計算ツールやコスト分析ソフトウェアを活用して、最適な設計を決定することが推奨されます。
TCO(Total Cost of Ownership)の観点から、初期投資だけでなく、運用コスト、保守コスト、人件費なども考慮する必要があります。高い可用性を実現するシステムは、複雑性が増すため、運用や保守により多くのリソースが必要となります。また、専門知識を持った人材の確保も重要な要素です。
クラウド環境での耐障害性
クラウドコンピューティングの普及により、耐障害性の実現方法も大きく変化しています。クラウドプロバイダーが提供する高可用性サービスを活用することで、従来よりも容易に耐障害性を実現できるようになりました。
Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Platform(GCP)などの主要クラウドプロバイダーは、様々な耐障害性機能を提供しています。可用性ゾーンによる地理的分散、オートスケーリングによる負荷対応、マネージドサービスによる運用負荷軽減など、従来のオンプレミス環境では実現が困難だった機能を利用できます。
マルチクラウド戦略は、特定のクラウドプロバイダーに依存するリスクを軽減し、より高い耐障害性を実現する手法です。複数のクラウドプロバイダーにシステムを分散配置することで、一つのプロバイダーにサービス障害が発生しても、他のプロバイダーでサービスを継続できます。マルチクラウド管理プラットフォームを活用することで、複雑なマルチクラウド環境を効率的に管理できます。
コンテナ技術とオーケストレーションツールの活用により、アプリケーションレベルでの耐障害性も向上しています。Kubernetesなどのオーケストレーションプラットフォームは、コンテナの自動復旧、負荷分散、スケーリングなどの機能を提供し、アプリケーションの可用性を向上させます。
災害復旧と事業継続計画
耐障害性の設計において、災害復旧(Disaster Recovery:DR)と事業継続計画(Business Continuity Plan:BCP)は重要な要素です。大規模な災害や障害が発生した場合に、いかに迅速にサービスを復旧し、事業を継続するかを事前に計画しておく必要があります。
災害復旧計画では、RPO(Recovery Point Objective:目標復旧時点)とRTO(Recovery Time Objective:目標復旧時間)を明確に定義します。RPOは「どの時点までのデータを復旧するか」を示し、RTOは「どの程度の時間でサービスを復旧するか」を示します。これらの目標を達成するため、企業向けバックアップソリューションや災害復旧サービスの活用が効果的です。
バックアップ戦略では、3-2-1ルールが推奨されます。これは「3つの複製を作成し、2つの異なる媒体に保存し、1つをオフサイトに保管する」という原則です。このルールに従うことで、様々な障害や災害からデータを保護できます。現代では、クラウドバックアップサービスの活用により、地理的に分散したバックアップを容易に実現できます。
定期的な災害復旧テストの実施は、計画の有効性を確認し、問題点を発見するために不可欠です。年に数回、実際の障害を想定したテストを実施し、復旧手順の確認、所要時間の測定、問題点の洗い出しを行います。このようなテストを効率的に実行するため、災害復旧テストツールの活用が推奨されます。
新技術と耐障害性の進歩
近年の技術革新により、耐障害性の実現方法も大きく進歩しています。人工知能(AI)と機械学習の活用により、障害の予兆検知や自動復旧が可能になっています。システムの動作パターンを学習し、異常な挙動を検出することで、障害が発生する前に予防的な対策を講じることができます。
エッジコンピューティングの普及により、処理を分散させることで障害の影響を局所化できるようになりました。中央のデータセンターに障害が発生しても、エッジでの処理を継続することで、サービスの可用性を維持できます。エッジコンピューティングソリューションの導入により、分散処理環境での耐障害性を実現できます。
ブロックチェーン技術は、分散台帳による高い耐障害性を実現します。複数のノードにデータを分散保存することで、一部のノードに障害が発生してもデータの整合性と可用性を保つことができます。特に、重要なデータの管理や取引記録の保管において、従来の中央集権的なシステムよりも高い耐障害性を実現できます。
サーバーレスアーキテクチャは、インフラストラクチャの管理をクラウドプロバイダーに委任することで、アプリケーションレベルでの耐障害性を向上させます。関数単位での実行により、一つの関数に問題が発生しても他の機能への影響を最小限に抑えることができます。
応用情報技術者試験での出題傾向
応用情報技術者試験において、耐障害性に関する問題は午前問題、午後問題ともに頻繁に出題されています。システム設計、データベース、ネットワーク、セキュリティなど、幅広い分野で耐障害性の知識が問われます。
午前問題では、可用性の計算、MTBF・MTTRの理解、冗長化手法の選択、障害対策の適用などが出題されます。例えば、「99.9%の可用性を実現するシステムの年間ダウンタイムは何時間か」といった計算問題や、「単一障害点を排除するために最も適切な対策はどれか」といった選択問題が見られます。
午後問題では、より実践的な場面での耐障害性設計が問われます。企業のシステム統合、災害復旧計画の策定、可用性向上施策の検討などの文脈で、具体的な設計判断や対策選択が評価されます。
試験対策としては、応用情報技術者試験の専門参考書での理論学習に加え、システム運用管理の実践書で実際の事例を学ぶことが効果的です。また、過去問題集を活用して、出題パターンを理解し、計算問題の解法を習得することが重要です。
組織的な取り組みと人材育成
技術的な対策だけでなく、組織的な取り組みも耐障害性の向上には欠かせません。インシデント管理プロセスの確立、運用手順の標準化、定期的な訓練の実施などが重要です。また、耐障害性に関する専門知識を持った人材の育成も重要な課題です。
インシデント管理では、障害発生時の対応手順を明確に定義し、役割分担、エスカレーション手順、復旧作業の進め方などを標準化します。インシデント管理システムの導入により、インシデントの記録、追跡、分析を効率的に行うことができます。
継続的な改善活動として、発生した障害の根本原因分析を実施し、再発防止策を検討することが重要です。障害の傾向分析、予防策の効果測定、改善提案の実施などを通じて、システムの耐障害性を継続的に向上させることができます。
まとめ
耐障害性は、現代のITシステムにおいて不可欠な要素です。ビジネスの継続性を確保し、顧客の信頼を維持するためには、適切な耐障害性設計が必要です。技術的な対策、組織的な取り組み、継続的な改善活動を通じて、高い可用性と信頼性を実現することができます。
応用情報技術者試験においても重要なトピックであり、理論的な理解と実践的な応用能力の両方が求められます。変化する技術環境に対応しながら、最適な耐障害性ソリューションを選択し、実装する能力を身につけることが重要です。
今後も、新しい技術の登場とともに耐障害性の実現方法は進歩し続けるでしょう。継続的な学習と実践により、時代の要請に応える高品質なシステムを構築することが可能となります。