現代のデジタル社会において、個人情報の活用と保護のバランスを取ることは極めて重要な課題となっています。匿名化技術は、この課題を解決するための中核的な技術として、医療、金融、研究、マーケティングなど様々な分野で活用されています。応用情報技術者試験においても、プライバシー保護技術の理解は必須の知識であり、特に匿名化に関する問題は頻出の重要トピックです。
匿名化とは、個人を特定できる情報(個人識別情報:PII)を削除または変更することで、データから個人の身元を特定できないようにする技術です。しかし、単純に名前や住所を削除するだけでは十分ではなく、年齢、性別、職業などの準識別子の組み合わせによって個人が特定される可能性があります。そのため、現代の匿名化技術では、統計学的および数学的アプローチを用いた高度な手法が開発されています。
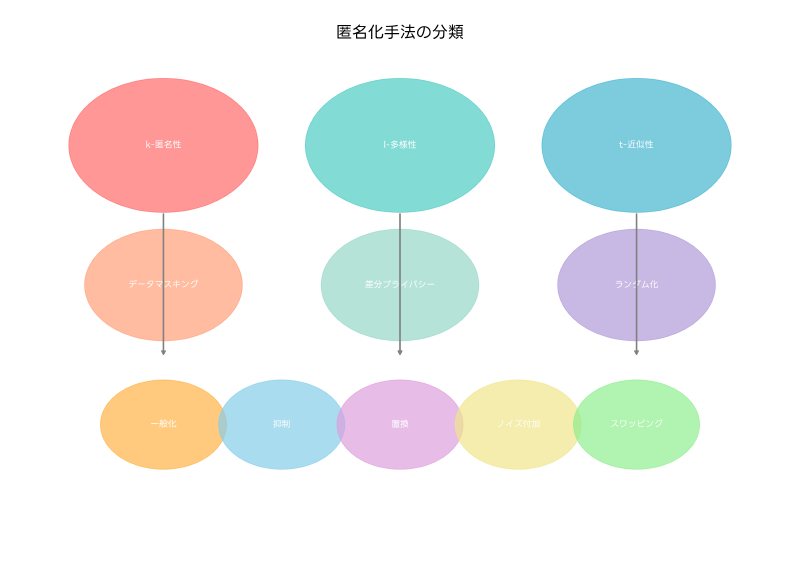
k-匿名性:匿名化技術の基礎概念
k-匿名性は、匿名化技術の最も基本的な概念の一つです。この概念は、データセット内において、同じ準識別子の組み合わせを持つレコードがk個以上存在することを保証します。例えば、k=3の場合、「30代、男性、東京都在住」という属性を持つ個人が、データセット内に最低3人以上存在することになります。これにより、特定の個人を一意に識別することが困難になります。
k-匿名性を実現するための主要な技術には、一般化と抑制があります。一般化は、具体的な値をより一般的な値に置き換える手法です。例えば、「35歳」を「30-39歳」に変更したり、「渋谷区」を「東京都」に変更したりします。抑制は、特定の値を削除または非表示にする手法で、異常値や希少な値を持つレコードに適用されます。
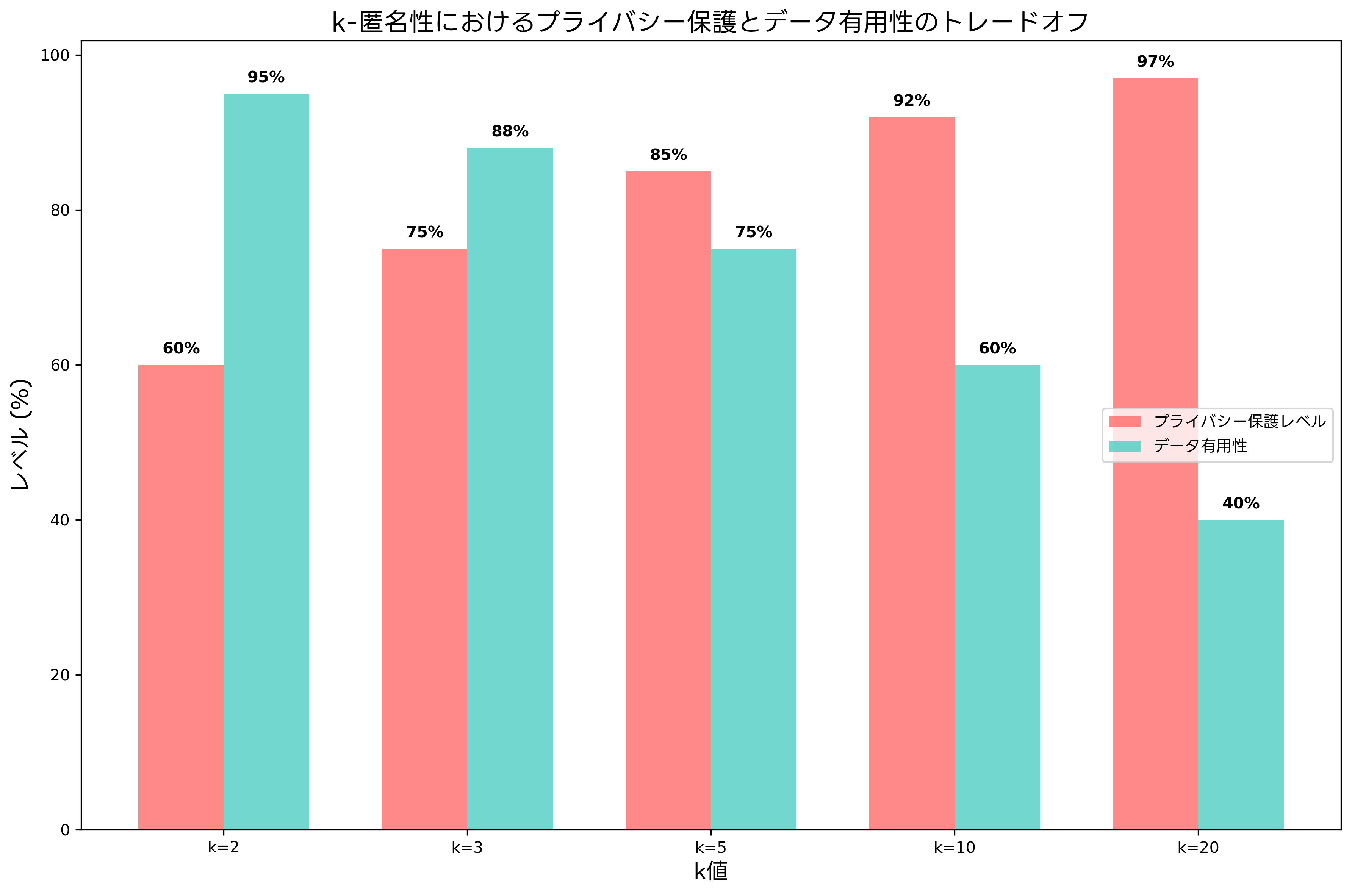
k値の設定は、プライバシー保護とデータ有用性のトレードオフを考慮して決定する必要があります。k値が大きいほどプライバシー保護レベルは向上しますが、同時にデータの詳細性が失われ、分析の精度が低下する可能性があります。実際の運用では、データの用途、規制要件、リスク評価などを総合的に考慮してk値を決定します。
k-匿名性の実装には、専用の匿名化ソフトウェアが利用されます。これらのツールは、効率的なアルゴリズムを使用して、データ有用性を最大限保持しながらk-匿名性を実現します。また、データプライバシー保護ツールを活用することで、複雑なデータセットに対しても適切な匿名化処理を実行できます。
l-多様性:センシティブ属性の保護
k-匿名性だけでは、センシティブな属性(病名、収入、政治的傾向など)の保護が不十分な場合があります。同じ準識別子グループ内のすべてのレコードが同じセンシティブ値を持つ場合、個人は特定できなくても、その人のセンシティブな情報は推測可能になってしまいます。この問題を解決するのがl-多様性です。
l-多様性は、各準識別子グループ内において、センシティブ属性の値がl個以上の異なる値を持つことを要求します。例えば、l=3の場合、「30代、男性、東京都在住」のグループ内で、病名が「高血圧」「糖尿病」「健康」の3種類以上存在する必要があります。これにより、準識別子が判明しても、センシティブな情報を特定することが困難になります。
l-多様性を実現するための技術には、値の置換、ランダム化、ノイズ付加などがあります。値の置換では、センシティブ値を他の値と交換することで多様性を確保します。ランダム化では、確率的な手法を用いてセンシティブ値を変更します。ノイズ付加では、元の値に統計的なノイズを加えることで、真の値を隠蔽しながら統計的特性を保持します。
医療データの匿名化では、医療情報匿名化システムが広く活用されています。これらのシステムは、HIPAAやGDPRなどの規制要件に準拠しながら、研究や統計分析に必要なデータ品質を維持します。また、センシティブデータ保護ソリューションを導入することで、様々な業界の要件に対応した匿名化処理が可能になります。
t-近似性:属性値分布の保護
l-多様性でも解決できない問題として、背景知識攻撃があります。攻撃者が外部知識を利用して、センシティブ属性の分布に関する情報を推測する攻撃です。例えば、ある地域の住民の90%が特定の病気にかかりやすいという知識を持つ攻撃者は、l-多様性が満たされていても、高い確率でその人の病気を推測できます。
t-近似性は、この問題を解決するために開発された概念です。各準識別子グループ内におけるセンシティブ属性の分布と、データセット全体における分布の差がt以下になることを要求します。これにより、特定のグループに偏った分布を持つことを防ぎ、背景知識を利用した攻撃を困難にします。
t-近似性を実現するアルゴリズムは複雑で、計算コストが高いという課題があります。しかし、高性能なデータ処理システムを活用することで、大規模なデータセットに対してもt-近似性を効率的に適用できます。また、並列処理対応の匿名化ツールを使用することで、処理時間を大幅に短縮できます。
差分プライバシー:数学的に厳密なプライバシー保護
近年、注目を集めているのが差分プライバシーです。この概念は、数学的に厳密なプライバシー保護の定義を提供し、どのような攻撃に対しても一定レベルの保護を保証します。差分プライバシーでは、ある個人のデータが含まれている場合と含まれていない場合で、クエリ結果の確率分布がほぼ同じになることを要求します。
差分プライバシーを実現する主要な手法は、ノイズ付加です。ラプラシアンノイズやガウシアンノイズを統計的クエリの結果に加えることで、個人の寄与を隠蔽します。ノイズの量は、プライバシー予算(ε)によって制御され、小さなεほど強いプライバシー保護を提供しますが、データの精度は低下します。
差分プライバシーの実装には、差分プライバシーライブラリやプライバシー保護機械学習ツールが活用されます。これらのツールは、研究者や開発者が差分プライバシーを容易に実装できるよう、使いやすいAPIと豊富な機能を提供します。
匿名化に対する攻撃と対策
匿名化技術の発展と同時に、匿名化データを標的とした攻撃手法も高度化しています。主要な攻撃手法には、準識別子攻撃、背景知識攻撃、相関攻撃、組み合わせ攻撃などがあります。これらの攻撃を理解し、適切な対策を講じることが、効果的な匿名化システムの構築に不可欠です。
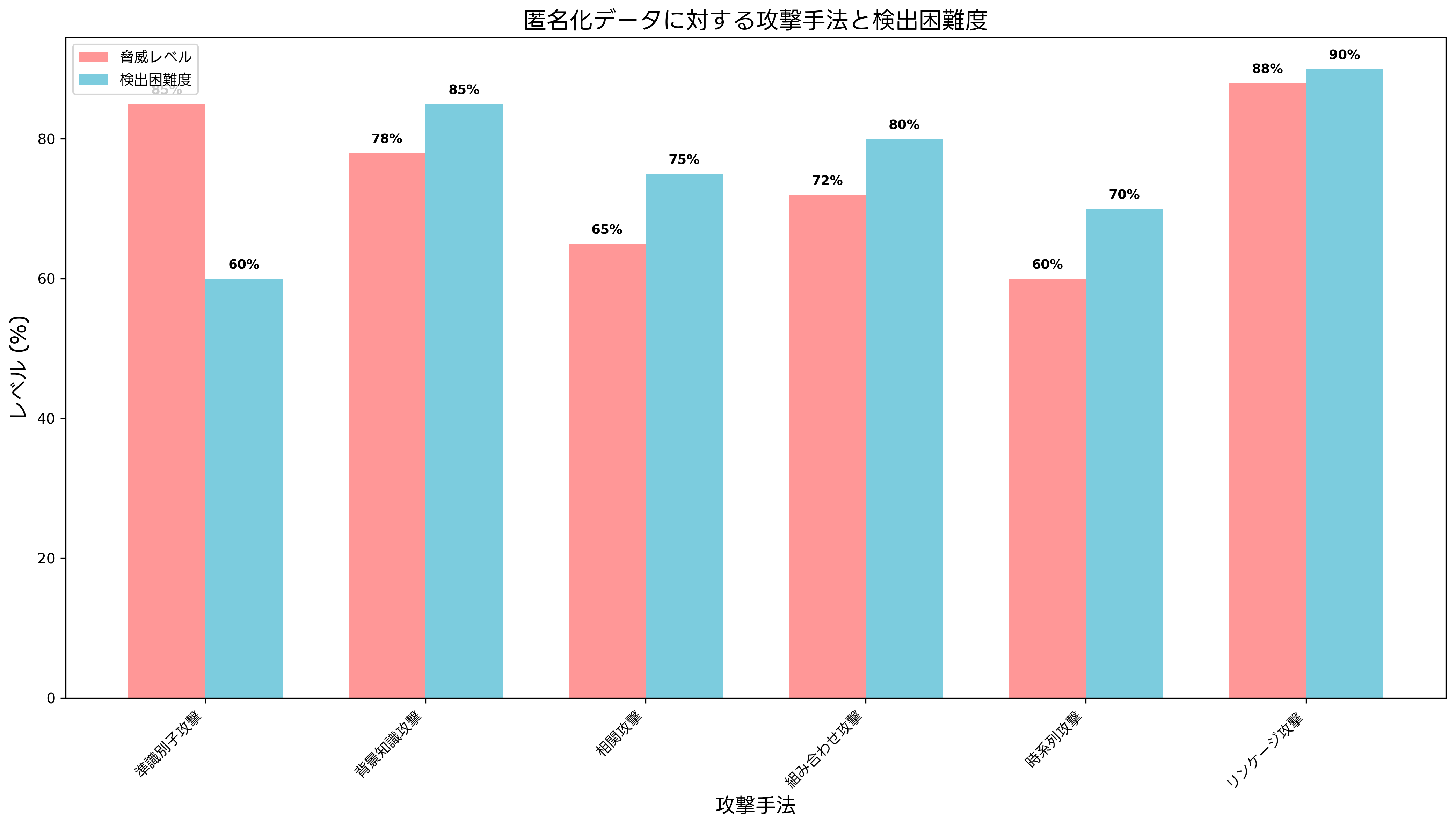
準識別子攻撃は、年齢、性別、住所などの準識別子を組み合わせて個人を特定する攻撃です。現代では、ソーシャルメディアや公開データベースから容易に準識別子情報を収集できるため、この攻撃の脅威は増大しています。対策として、準識別子の特定と適切な一般化、そして定期的なリスク評価が必要です。
背景知識攻撃では、攻撃者が外部の知識を利用してプライバシーを侵害します。例えば、特定の病院で治療を受けていることが分かっている人について、その病院の患者データから個人を特定したり、センシティブな情報を推測したりします。この攻撃に対抗するため、攻撃検出システムやプライバシーリスク評価ツールの導入が重要です。
相関攻撃は、複数のデータセット間の相関関係を利用した攻撃です。単独では匿名化されたデータでも、他のデータセットと結合することで個人が特定される可能性があります。この問題に対処するため、データリンケージの制御と、データガバナンスプラットフォームによる包括的なデータ管理が必要です。
データ種別ごとの匿名化アプローチ
異なる種類のデータには、それぞれ固有の匿名化要件と課題があります。医療データ、金融データ、位置情報、Web行動データなど、各データ種別に適した匿名化手法を選択することが重要です。
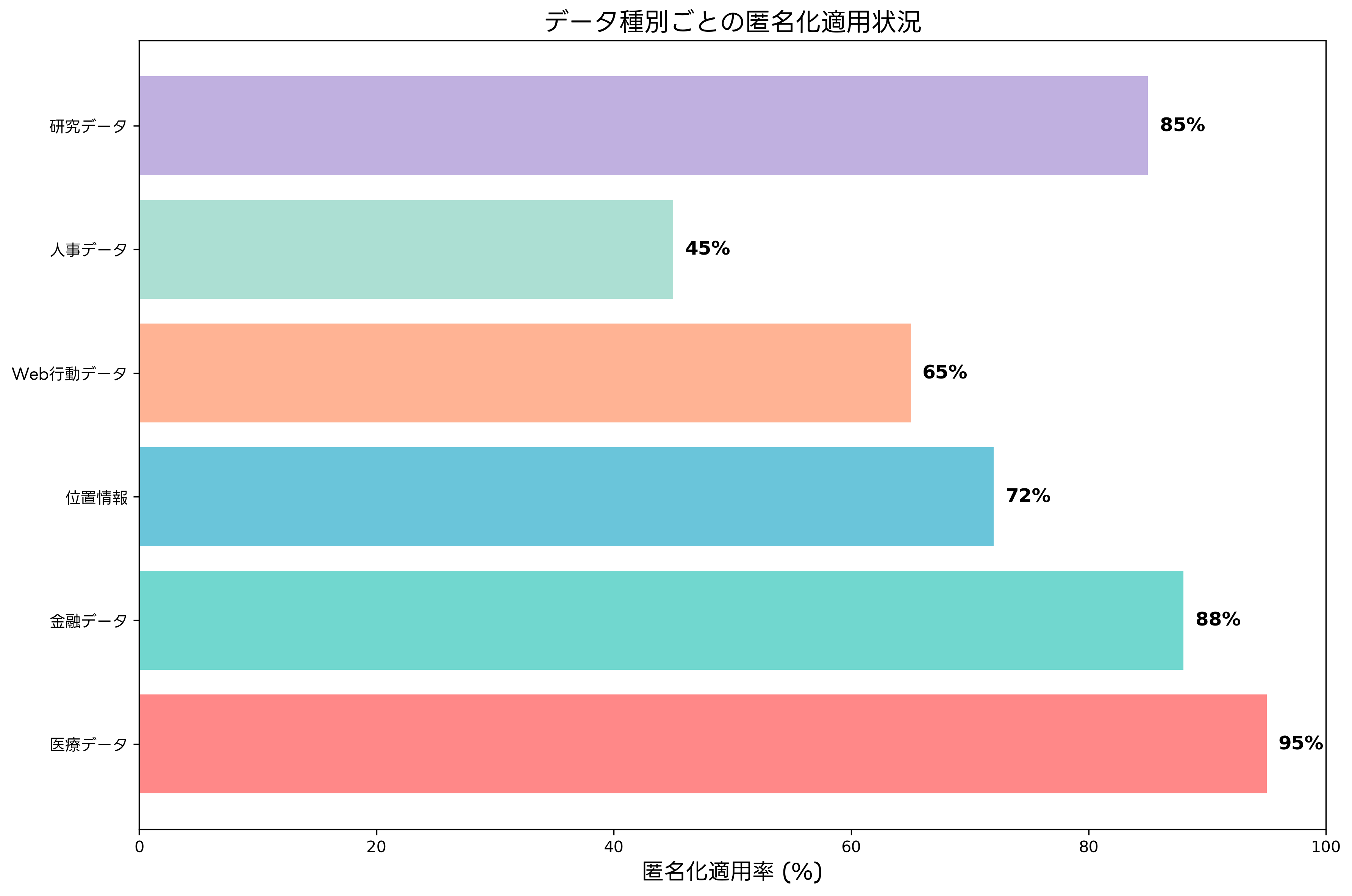
医療データの匿名化では、患者のプライバシー保護と医学研究の推進のバランスが重要です。HIPAAのSafe Harbor規則では、18種類の識別子の除去を要求していますが、現代の研究では、より高度な統計的匿名化手法が必要とされています。医療データ匿名化プラットフォームを活用することで、規制遵守と研究価値の両立が可能になります。
金融データの匿名化では、取引の詳細性を保持しながら顧客のプライバシーを保護する必要があります。時系列データの特性を考慮した匿名化手法や、取引パターンの保護が重要な要素となります。金融データセキュリティソリューションは、こうした要件に対応した専用機能を提供します。
位置情報の匿名化は、特に困難な課題の一つです。位置データは本質的に識別性が高く、移動パターンから個人を特定することが可能です。地理的一般化、軌跡の摂動、スケジュールのずらしなどの手法が用いられます。位置情報プライバシー保護ツールを使用することで、位置ベースサービスの価値を保持しながらプライバシーを保護できます。
Web行動データの匿名化では、Cookie、セッション情報、閲覧履歴などの多様なデータ要素を扱う必要があります。行動パターンの保護と分析価値の維持のバランスが重要です。Web解析プライバシーツールにより、ユーザーのプライバシーを尊重しながら有意義な分析を実行できます。
匿名化ツールとソリューション
効果的な匿名化を実現するためには、適切なツールの選択が重要です。オープンソースから商用まで、様々な匿名化ツールが利用可能です。各ツールは異なる機能、性能、サポートレベルを提供するため、用途に応じた選択が必要です。
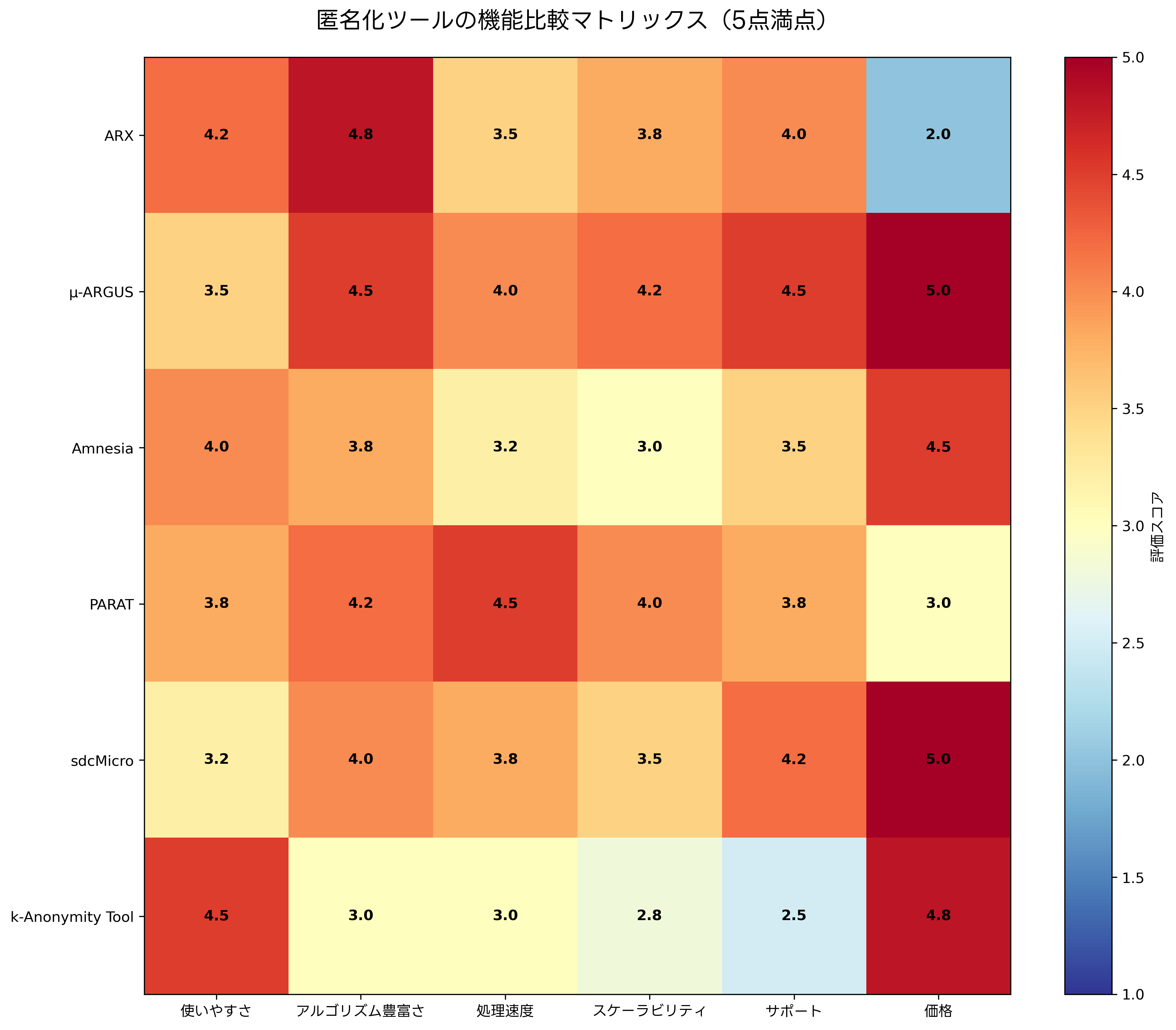
ARXは、最も人気のあるオープンソース匿名化ツールの一つです。k-匿名性、l-多様性、t-近似性などの主要な匿名化手法をサポートし、直感的なGUIを提供します。研究機関や教育機関での利用に適しており、ARX関連の技術書を参考にすることで、効果的な活用が可能です。
μ-ARGUSは、統計機関向けに開発された匿名化ツールで、表形式データとマイクロデータの両方に対応しています。高度な統計的開示制御機能を提供し、国家統計機関での利用実績があります。統計的開示制御の専門書で理論的背景を学ぶことで、より効果的な活用が可能になります。
商用ソリューションでは、IBM InfoSphere Optim、Informatica Persistent Data Masking、Delphix Dynamic Data Platformなどが代表的です。これらは、エンタープライズ環境での大規模データ処理、高度なセキュリティ機能、包括的なサポートを提供します。エンタープライズデータマスキングソリューションの導入により、企業レベルでの匿名化要件に対応できます。
クラウドベースの匿名化サービスも増加しています。AWS、Microsoft Azure、Google Cloudなどの主要クラウドプロバイダーは、匿名化機能を含むデータ保護サービスを提供しています。クラウドデータ保護サービスを活用することで、スケーラブルで費用効果の高い匿名化ソリューションを実現できます。
法規制と標準への対応
匿名化技術の実装においては、関連する法規制と業界標準への準拠が不可欠です。GDPR、HIPAA、個人情報保護法などの規制は、匿名化に関する具体的な要件を定めており、これらを満たすための技術的・組織的対策が必要です。
GDPRでは、匿名化を「自然人がもはや特定されない、または特定不可能になるような方法で個人データを処理すること」と定義しています。真の匿名化が達成された場合、そのデータはGDPRの適用範囲外となるため、匿名化技術への関心が高まっています。GDPR対応プライバシーソリューションを導入することで、規制要件への適切な対応が可能になります。
HIPAAのSafe Harbor規則は、医療情報の匿名化に関する具体的なガイドラインを提供しています。18種類の識別子の除去と、残りの情報では個人を特定できないことの確認が要求されます。HIPAA準拠医療システムは、これらの要件を満たすための機能を提供します。
日本の個人情報保護法では、匿名加工情報という概念が導入されています。適切な加工により個人を識別できないようにした情報は、本人の同意なしに第三者提供や目的外利用が可能になります。個人情報保護法対応システムにより、法的要件を満たした匿名化処理を実現できます。
ISO/IEC 20889は、プライバシーエンジニアリングに関する国際標準で、匿名化技術の選択と実装に関するガイダンスを提供しています。ISO27001対応セキュリティシステムと組み合わせることで、包括的なプライバシー保護体制を構築できます。
応用情報技術者試験での出題傾向
応用情報技術者試験において、匿名化技術は情報セキュリティ分野の重要トピックとして頻繁に出題されています。試験では、匿名化の基本概念、主要な手法、実装上の課題、法規制との関係などが問われます。
午前問題では、k-匿名性、l-多様性、t-近似性の定義と特徴、差分プライバシーの概念、匿名化手法の分類などが出題されます。また、匿名化に対する攻撃手法や、データ種別ごとの匿名化要件に関する問題も見られます。基礎理論の理解に加えて、実際の適用場面での判断力が求められます。
午後問題では、より実践的な場面での匿名化技術の応用が問われます。企業のデータ活用戦略立案、プライバシー影響評価の実施、匿名化システムの設計などの文脈で、技術的知識の応用能力が評価されます。
試験対策としては、応用情報技術者試験のセキュリティ分野対策書を活用して、匿名化技術の理論的基礎を固めることが重要です。また、プライバシー保護技術の専門書により、最新の技術動向と実装事例を学習することで、より深い理解を得ることができます。
実際の業務経験がある場合は、自社のデータ活用状況を匿名化技術の観点から分析し、改善提案を考える練習が効果的です。データプライバシー監査ツールを使用して、実際のシステムのプライバシーリスクを評価することで、理論と実践の橋渡しができます。
機械学習と匿名化技術の融合
近年、機械学習技術の発展により、匿名化技術にも新たな可能性が生まれています。プライバシー保護機械学習(Privacy-Preserving Machine Learning)は、データの有用性を最大限保持しながらプライバシーを保護する技術として注目されています。
フェデレーテッドラーニング(連合学習)は、データを集中化することなく機械学習モデルを訓練する手法です。各参加者は自身のデータを手元に保持したまま、モデルの更新情報のみを共有します。これにより、プライバシーを保護しながら高品質なモデルを構築できます。フェデレーテッドラーニングプラットフォームの導入により、この技術の実用化が進んでいます。
同型暗号は、暗号化されたデータに対して直接計算を実行できる技術です。データを復号化することなく機械学習の訓練や推論を行うことができ、究極のプライバシー保護技術として期待されています。同型暗号ライブラリの発展により、実用的な性能での利用が可能になりつつあります。
秘密計算(Secure Multi-party Computation)は、複数の参加者が秘密情報を開示することなく共同計算を実行する技術です。医療研究や金融分析など、機密性の高いデータを扱う分野での応用が期待されています。秘密計算プラットフォームにより、この技術の実装が容易になっています。
匿名化技術の将来展望
匿名化技術は、技術革新と社会的要請の両面から継続的な発展を遂げています。量子コンピューティングの発展は、現在の暗号化技術に脅威をもたらす一方で、量子暗号化による新たなプライバシー保護技術の可能性も開いています。
ブロックチェーン技術と匿名化技術の融合も注目される分野です。分散台帳の透明性と匿名化技術のプライバシー保護を組み合わせることで、新たなデータ共有モデルが創出される可能性があります。ブロックチェーンプライバシーソリューションは、この分野での技術開発を支援しています。
人工知能の発展により、匿名化攻撃も高度化することが予想されます。機械学習を用いた再識別攻撃に対抗するため、より堅牢な匿名化技術の開発が求められています。AI対応プライバシー保護システムは、こうした新たな脅威に対応するための機能を提供します。
まとめ
匿名化技術は、デジタル社会における個人情報保護とデータ活用の両立を実現する重要な技術です。k-匿名性、l-多様性、t-近似性、差分プライバシーなどの基本概念から、最新の機械学習との融合技術まで、幅広い知識と理解が求められます。
応用情報技術者試験においても、匿名化技術は重要な出題分野であり、理論的理解と実践的応用能力の両方が評価されます。技術の急速な発展と法規制の変化に対応するため、継続的な学習と最新情報の収集が不可欠です。
企業や組織においては、適切な匿名化技術の選択と実装により、コンプライアンス要件を満たしながらデータの価値を最大化することが可能になります。プライバシー・バイ・デザインの考え方に基づき、システム設計の初期段階から匿名化技術を組み込むことで、持続可能なデータ活用基盤を構築できます。
匿名化技術の理解と適切な実装により、個人のプライバシーを尊重しながら、データ駆動型社会の恩恵を享受することができます。技術者として、社会的責任を果たしながら技術革新に貢献することが求められています。