現代のコンピューティング環境において、文字の表現と処理は極めて重要な要素です。ウニコード(Unicode)は、世界中の文字を統一的に扱うための国際標準であり、情報技術の基盤として欠かせない存在となっています。応用情報技術者試験においても、文字コードやエンコーディングに関する問題が頻出しており、ウニコードの理解は必須の知識です。
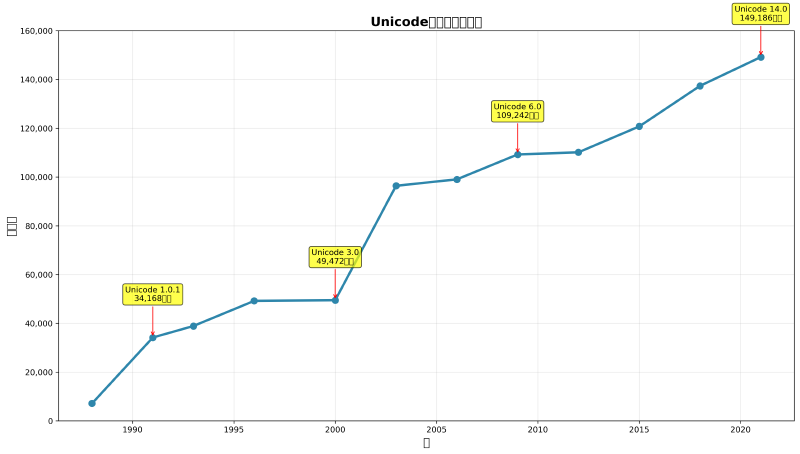
ウニコードは、1991年に最初のバージョンが公開されて以来、継続的に発展を続けており、現在では約15万文字をサポートする巨大な文字体系となっています。この包括的な文字セットにより、日本語、中国語、アラビア語、キリル文字など、世界中の言語を統一的に処理することが可能になりました。
ウニコードの基本概念と歴史
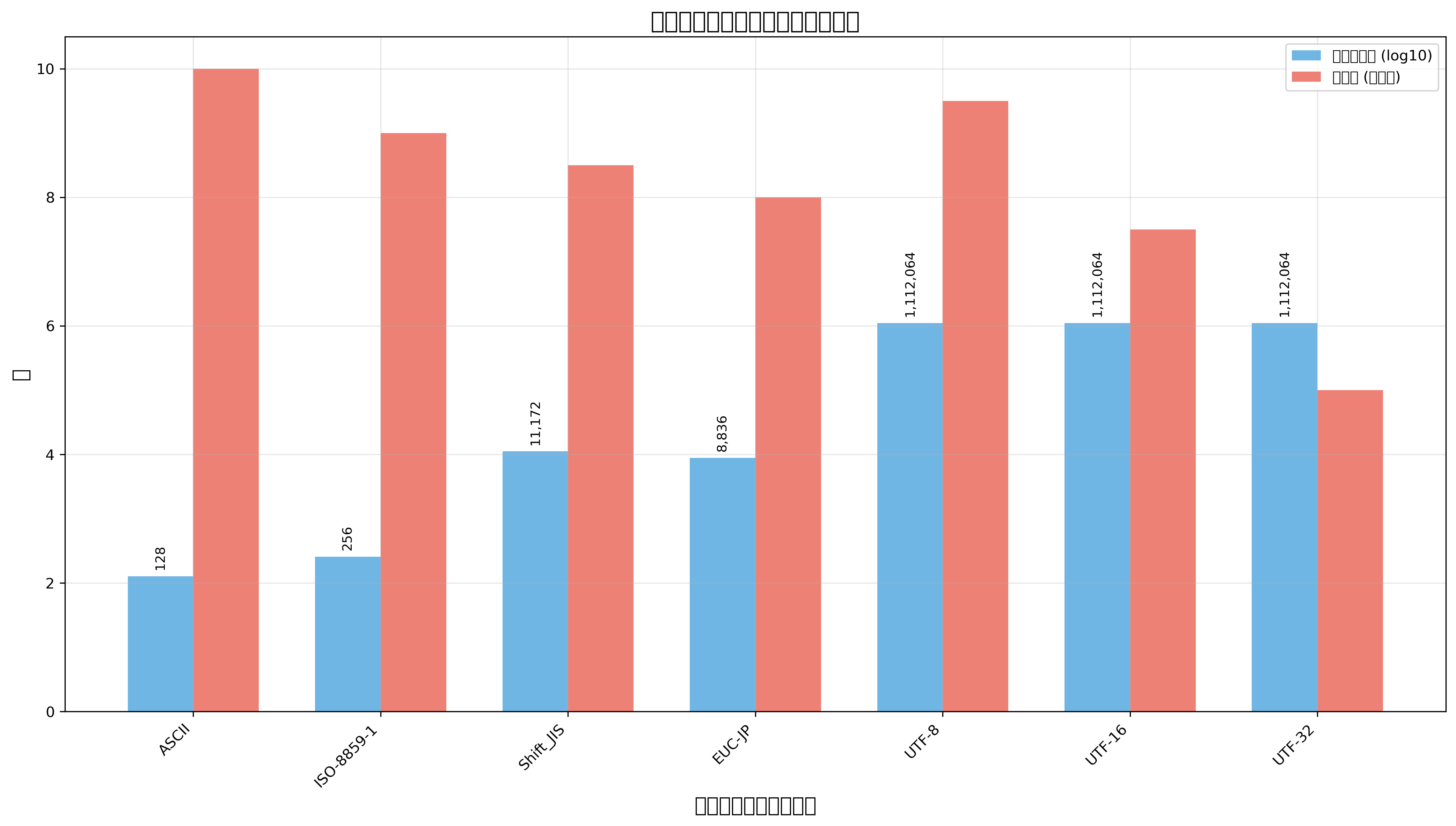
ウニコードの開発は、従来の文字コード体系が抱えていた深刻な問題を解決するために始まりました。1980年代までのコンピューター業界では、ASCII、EBCDIC、Shift_JIS、EUC-JPなど、様々な文字コードが乱立しており、異なるシステム間でのデータ交換や多言語対応が困難でした。特に日本語環境では、文字化けという問題が日常的に発生し、文字コード変換ソフトが必要不可欠なツールとなっていました。
ウニコードコンソーシアムは、この課題を解決するため、すべての文字を単一の体系で表現する革新的なアプローチを採用しました。初期のウニコード1.0では約7,000文字をサポートしていましたが、現在のウニコード14.0では約15万文字をカバーしています。この拡張により、古代文字、絵文字、数学記号、技術記号など、あらゆる文字表現が可能になりました。
ウニコードの特徴的な設計思想として、文字の抽象的な概念(文字)と具体的な表現(グリフ)を分離していることが挙げられます。この設計により、同じ文字でも異なるフォントや表示環境に応じて、適切な視覚的表現を選択できるようになっています。現代の多言語対応フォントは、この設計思想に基づいて開発されています。
文字の識別には、U+0000からU+10FFFFまでの範囲で定義されるコードポイントが使用されます。例えば、ラテン文字の「A」はU+0041、ひらがなの「あ」はU+3042、漢字の「愛」はU+611Bという具合に、各文字に固有の番号が割り当てられています。この体系的なアプローチにより、プログラマーはウニコード対応の開発ツールを使用して、国際的なアプリケーションを効率的に開発できます。
ウニコードの文字体系と構造
ウニコードの文字空間は、効率的な管理と処理のために、複数のブロックとプレーンに分割されています。基本多言語面(BMP:Basic Multilingual Plane)と呼ばれるプレーン0には、最も頻繁に使用される文字が配置されており、日常的なテキスト処理の大部分をカバーしています。
基本ラテン文字ブロック(U+0000-U+007F)には、ASCII文字がそのまま含まれており、既存のシステムとの後方互換性を保っています。日本語関連では、ひらがな(U+3040-U+309F)、カタカナ(U+30A0-U+30FF)、CJK統合漢字(U+4E00-U+9FFF)など、各文字体系が独立したブロックに配置されています。
CJK統合漢字は、中国語、日本語、韓国語で共通して使用される漢字を統合したブロックで、約2万文字を含んでいます。この統合により、東アジアの言語処理が大幅に簡素化されました。ただし、同じ漢字でも地域によって微妙な字体の違いがあるため、地域別フォントパックを使用して、適切な表示を実現することが重要です。
絵文字ブロックは、現代のコミュニケーションにおいて重要な役割を果たしています。絵文字はU+1F600以降の補助プレーンに配置されており、継続的に新しい絵文字が追加されています。この拡張性により、文化的な多様性や新しい表現手段に対応することが可能になっています。絵文字対応キーボードや絵文字入力ソフトの普及により、絵文字の利用がより身近になっています。
サロゲートペアという仕組みにより、BMPを超えた文字(補助文字)も効率的に表現できます。この技術により、古代エジプト象形文字、楔形文字、数学記号など、専門的な用途で使用される文字も正確に処理できるようになっています。
UTF-8エンコーディングの仕組み
ウニコードの文字は、実際のコンピューターシステムで処理するために、バイト列に変換される必要があります。この変換過程をエンコーディングと呼び、UTF-8、UTF-16、UTF-32などの方式が定められています。中でもUTF-8は、現在最も広く使用されているエンコーディング方式です。
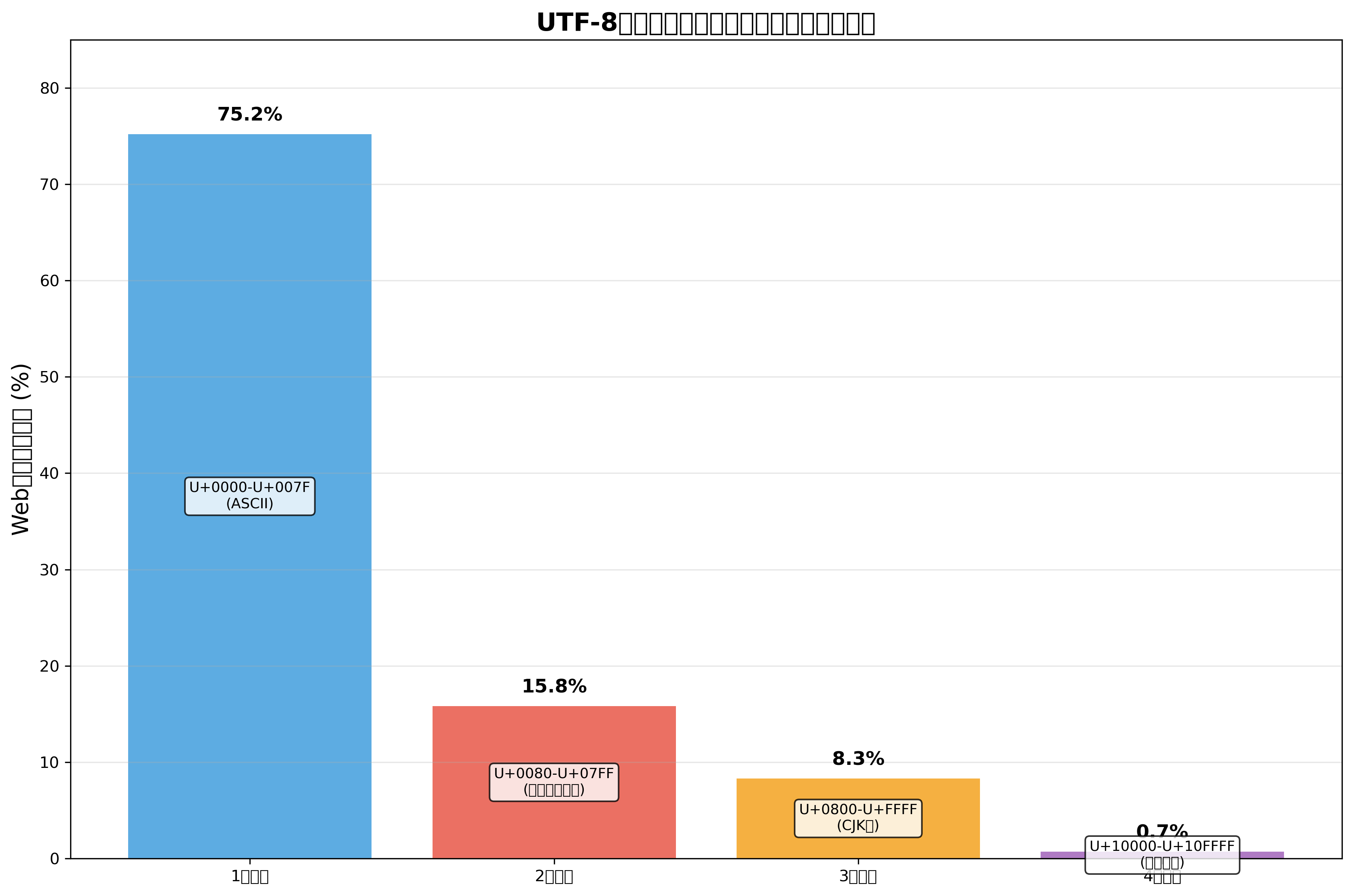
UTF-8の大きな特徴は、可変長エンコーディングであることです。ASCII文字(U+0000-U+007F)は1バイトで表現され、既存のASCIIテキストとの完全な互換性を保っています。日本語のひらがなやカタカナ、漢字は通常3バイトで表現され、絵文字などの補助文字は4バイトで表現されます。
この設計により、英語中心のテキストでは従来のASCIIと同じ効率性を保ちながら、必要に応じて多言語文字を混在させることができます。Web開発において、UTF-8対応のテキストエディタや多言語対応IDEを使用することで、国際的なWebサイトを効率的に開発できます。
UTF-8のバイト構造は、先頭バイトのビットパターンによって文字の長さを判定できるよう設計されています。1バイト文字は0で始まり、2バイト文字は110で始まり、3バイト文字は1110で始まり、4バイト文字は11110で始まります。この自己同期性により、文字境界の検出やエラー回復が容易になっています。
UTF-8の別の重要な特性として、バイト順序の問題がないことが挙げられます。UTF-16やUTF-32では、マルチバイト値のバイト順序(エンディアン)を考慮する必要がありますが、UTF-8では各バイトが独立しているため、この問題が発生しません。この特性により、クロスプラットフォーム対応ツールでの文字処理が簡素化されています。
文字エンコーディングの比較と選択
ウニコード以前の文字エンコーディング方式と比較すると、ウニコードの優位性が明確に見えてきます。従来のShift_JISやEUC-JPは日本語に特化していたため、他言語との混在処理や国際的なデータ交換に制限がありました。また、文字セットの拡張性も限定的で、新しい文字や記号の追加が困難でした。
ISO-8859シリーズは、ヨーロッパ言語向けの拡張ASCIIとして開発されましたが、地域ごとに異なる文字セットを使用するため、多言語環境での運用には適していませんでした。ウニコードの登場により、これらの地域固有の制限が解消され、真の意味でのグローバルな文字処理が実現されました。
UTF-16は、Windowsシステムの内部処理で広く使用されているエンコーディング方式です。BMPの文字を2バイトで効率的に表現できますが、補助文字にはサロゲートペアという4バイトの表現が必要になります。この特性により、文字数のカウントや文字列操作において注意が必要です。Windows対応開発ツールを使用する際は、UTF-16の特性を理解することが重要です。
UTF-32は、すべての文字を4バイトの固定長で表現するため、文字操作が最も簡単ですが、メモリ使用量とストレージ要件が大きくなります。メモリに制約のある環境や、大量のテキストを扱うシステムでは、効率性の観点からUTF-8やUTF-16が選択されることが多いです。
現在のWeb環境では、UTF-8が標準的な選択となっています。HTML5仕様でもUTF-8の使用が推奨されており、モダンWebブラウザはすべてUTF-8を完全にサポートしています。また、データベースシステムにおいても、UTF-8対応データベースが主流となっており、多言語データの格納と検索が効率的に行えます。
世界の言語とウニコード対応
ウニコードの最大の功績の一つは、世界中の言語に対する包括的なサポートを実現したことです。ラテン文字系言語はもちろん、アラビア文字、キリル文字、インド系文字、東アジアの表意文字など、地球上のほぼすべての文字体系がサポートされています。
ラテン文字系言語は、ウニコードにおいて最も成熟したサポートを受けています。基本ラテン文字から拡張ラテン文字まで、ヨーロッパ、アメリカ、アフリカの多くの言語で使用される文字が網羅されています。この充実したサポートにより、多言語Webサイト構築ツールを使用して、効率的に国際的なWebサイトを開発できます。
アラビア文字系言語では、右から左に記述される文字方向や、文脈に応じて文字形が変化する特性がサポートされています。ウニコードの双方向テキストアルゴリズム(BiDi)により、アラビア語とラテン文字が混在するテキストも正確に表示できます。この機能を活用するため、中東地域対応ソフトウェアの開発が活発化しています。
インド系文字は、複雑な文字結合規則と音韻体系を持っており、ウニコードではこれらの特性を正確に表現するための仕組みが提供されています。デーヴァナーガリー文字をはじめとする各種インド系文字のサポートにより、南アジア地域向けアプリケーションの開発が可能になっています。
東アジアの表意文字システムでは、CJK統合漢字によって中国語、日本語、韓国語の漢字が統一的に処理されています。ただし、地域によって好まれる字体に違いがあるため、フォント選択やローカライゼーションにおいて配慮が必要です。東アジア言語対応フォントを適切に選択することで、各地域のユーザーに最適な文字表示を提供できます。
古代文字や専門的な記号についても、ウニコードは積極的にサポートを拡張しています。エジプト象形文字、楔形文字、ルーン文字などの古代文字により、歴史学や言語学の研究においてもウニコードが活用されています。また、数学記号、音楽記号、技術記号の充実により、専門分野向けソフトウェアの開発も促進されています。
ウニコード実装の課題と解決策
ウニコードの実装においては、理論的な完全性と実用的な要求のバランスを取ることが重要な課題となっています。文字化けの問題は大幅に減少しましたが、完全に解消されたわけではありません。異なるシステム間でのデータ交換や、レガシーシステムとの連携において、依然として注意深い設計が必要です。
バイト順序マーク(BOM)の取り扱いは、ウニコード実装における重要な課題の一つです。UTF-8ではBOMは必須ではありませんが、一部のシステムでは誤った処理が行われる場合があります。このため、BOM対応テキスト処理ツールを使用して、適切なBOM処理を実装することが重要です。
正規化の問題も、ウニコード実装において注意が必要な分野です。同じ文字でも、複数のウニコード表現が可能な場合があります。例えば、アクセント付き文字は、合成済み文字として表現することも、基本文字と結合文字の組み合わせとして表現することも可能です。この違いにより、文字列比較や検索において予期しない結果が生じる可能性があります。
フォントサポートの不足は、特に新しい文字や専門的な記号を扱う際に顕在化する問題です。ウニコードで定義されている文字であっても、適切なフォントがインストールされていなければ、正しく表示されません。この問題に対処するため、包括的フォントパッケージの導入や、フォントフォールバック機能の実装が重要になります。
プログラミング言語やライブラリによっても、ウニコードサポートのレベルに差があります。文字列長の計算、部分文字列の抽出、大文字小文字変換などの基本的な操作においても、ウニコードの特性を正しく理解した実装が必要です。ウニコード対応プログラミングライブラリを活用することで、これらの複雑性を適切に処理できます。
国際化(i18n)とローカライゼーション(l10n)の観点からも、ウニコードの実装には多くの考慮事項があります。文字の表示方向、文字結合規則、語彙境界の検出、ソート順序など、言語固有の特性を正確に処理する必要があります。
応用情報技術者試験での出題傾向
応用情報技術者試験においては、ウニコードと文字エンコーディングに関する問題が継続的に出題されています。特に、文字コードの変換、エンコーディング方式の特徴、文字化けの原因と対策などが重要なテーマとなっています。
午前問題では、UTF-8、UTF-16、UTF-32の特徴や違い、ASCIIとの互換性、バイト数の計算などが問われます。例えば、「特定の文字列をUTF-8でエンコードした場合のバイト数を求める」といった計算問題や、「文字化けが発生する原因として最も適切なものを選択する」といった選択問題が出題されます。
午後問題では、より実践的な文脈でのウニコード活用が問われます。Webアプリケーションの国際化対応、データベースでの多言語データ処理、システム間でのデータ交換における文字コード変換などの場面で、適切な技術選択や設計判断を求められます。
試験対策としては、応用情報技術者試験の専門テキストでウニコードの基礎理論を学習し、プログラミング実習書で実際の実装経験を積むことが効果的です。また、過去問題解説集を活用して、出題パターンと解法を習得することも重要です。
実務経験を試験対策に活かすためには、日常的に扱うシステムの文字エンコーディング設定を確認し、文字化けトラブルの解決方法を理解することが有効です。また、文字コード変換ツールを使用して、異なるエンコーディング間での変換処理を実際に体験することで、理論と実践の橋渡しができます。
プログラミングでのウニコード活用
現代のプログラミング環境では、ウニコードサポートが標準的な機能として提供されています。Python、Java、JavaScript、C#などの主要言語では、内部的にウニコード文字列を使用しており、プログラマーは文字エンコーディングを意識することなく多言語アプリケーションを開発できます。
Python 3では、すべての文字列がウニコードオブジェクトとして扱われ、UTF-8がデフォルトのエンコーディングとして使用されます。ファイルの読み書きやネットワーク通信においても、エンコーディングを明示的に指定することで、適切な文字処理が行われます。Python ウニコード プログラミング ガイドを参考にすることで、効率的な多言語対応アプリケーションを開発できます。
Javaでは、char型とString型が内部的にUTF-16エンコーディングを使用しており、ウニコード文字の処理が標準的にサポートされています。ただし、サロゲートペアを使用する補助文字の処理には特別な注意が必要です。Character.codePointAtメソッドやString.codePointCountメソッドなどを使用することで、正確な文字数の計算や文字操作が行えます。
JavaScriptでは、ES6以降でウニコードサポートが大幅に強化されました。Unicode正規化、Unicode文字プロパティ、Unicode対応正規表現などの機能により、高度な文字処理が可能になっています。JavaScript ウニコード 開発ガイドを活用することで、ブラウザベースの多言語アプリケーションを効率的に開発できます。
データベースとの連携においても、ウニコードサポートは重要です。MySQL、PostgreSQL、SQL Serverなどの主要データベースシステムでは、UTF-8やUTF-16での文字格納がサポートされており、多言語データの効率的な管理が可能です。ただし、データベースの文字セット設定やコレーション設定を適切に行うことが重要です。
ウニコードの将来展望
ウニコードは継続的に発展を続けており、新しい文字や記号の追加、既存の仕様の改良、新しい技術への対応などが行われています。年1回のメジャーアップデートにより、文化的多様性の拡大や技術進歩に対応した機能強化が図られています。
人工知能と機械学習の分野では、ウニコードの重要性がさらに高まっています。自然言語処理、多言語翻訳、テキスト分析などの応用において、ウニコードによる統一的な文字表現が基盤となっています。AI・機械学習向け自然言語処理ツールの多くは、ウニコードサポートを前提として設計されています。
IoTとエッジコンピューティングの普及により、リソース制約のある環境でのウニコード処理も重要な課題となっています。効率的なエンコーディング方式の開発、軽量なウニコード処理ライブラリの提供、部分的ウニコードサポートの標準化などが進められています。
Web技術の発展においても、ウニコードは中核的な役割を担っています。HTML5、CSS3、WebAssemblyなどの新しい技術では、ウニコードサポートが前提となっており、国際的なWeb体験の向上に貢献しています。モダンWeb開発フレームワークの多くは、ウニコードを標準でサポートしています。
まとめ
ウニコードは、現代の情報技術における基盤技術として、文字処理の統一化と国際化を実現しました。その包括性、拡張性、標準性により、グローバルな情報社会の発展に大きく貢献しています。応用情報技術者試験においても重要なトピックであり、IT専門職として必須の知識です。
技術者にとって、ウニコードの理解は単なる文字コードの知識を超えて、国際的なシステム設計、多言語対応アプリケーション開発、文化的多様性への配慮など、幅広い技術的・社会的課題への対応能力を意味します。継続的な学習と実践により、グローバルな視点を持った技術者として成長することができます。
今後も技術の進歩とともにウニコードは発展を続けるでしょう。新しい文字体系の追加、エンコーディング技術の改良、新しいアプリケーション領域への適用など、様々な可能性が広がっています。この進歩に対応するため、継続的な学習と技術動向の把握が重要です。