データベースシステムにおいて、インデックスは検索性能を劇的に向上させる重要な仕組みです。応用情報技術者試験でも頻出のトピックであり、データベース設計と運用において欠かせない知識となっています。インデックスを適切に設計・運用することで、大量のデータを扱うシステムでも高速な検索処理を実現できます。
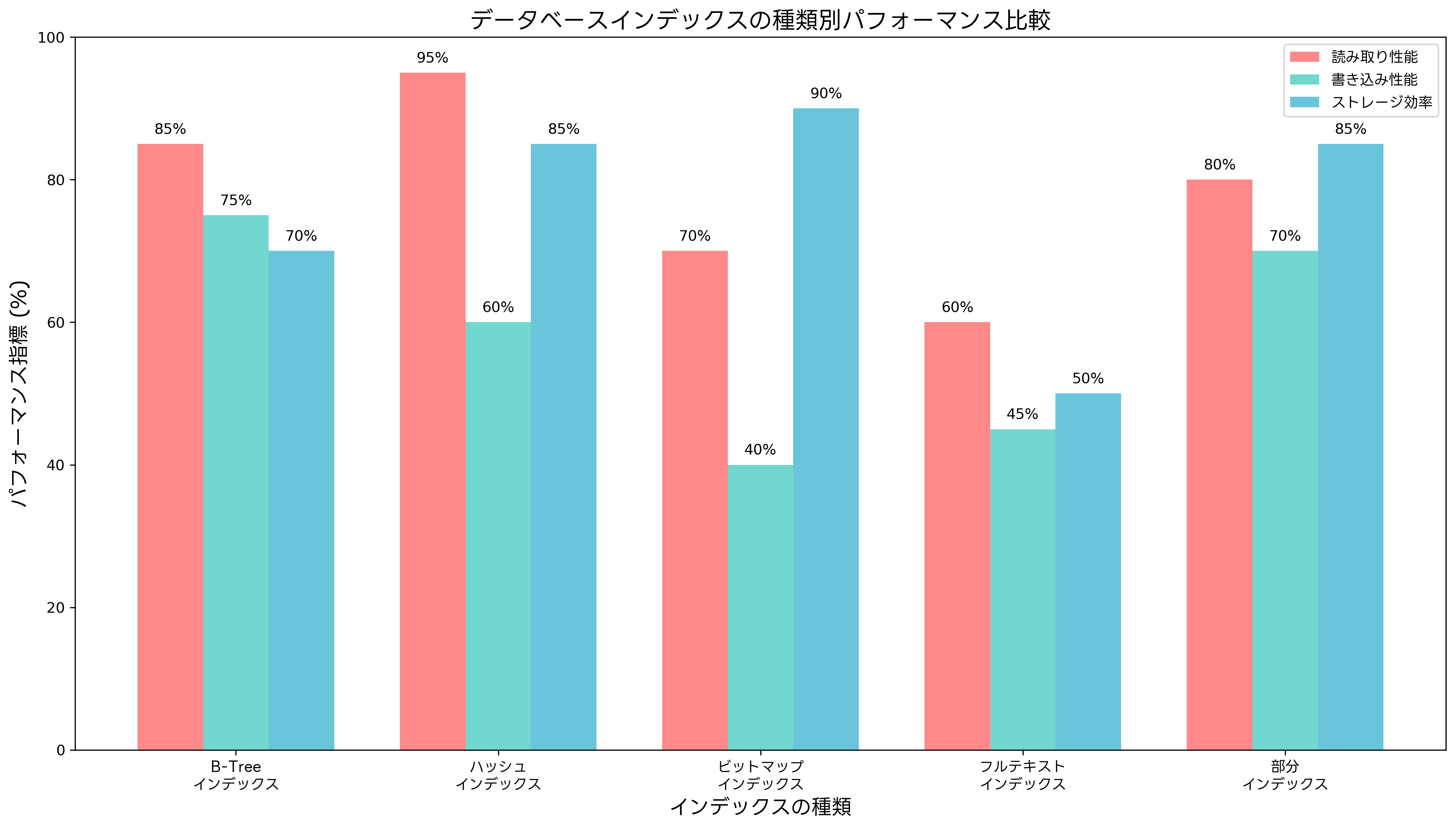
インデックスとは、データベーステーブル内のデータを効率的に検索するための仕組みです。書籍の索引のように、データの物理的な格納場所とは別に、検索用の構造を構築することで、全件検索(フルスキャン)を避けて目的のデータに素早くアクセスできます。現代のビジネスシステムでは、数百万件から数億件のデータを扱うことが珍しくなく、インデックスの適切な設計がシステム全体の性能を左右します。
インデックスの基本原理と動作メカニズム
インデックスの動作原理を理解するために、まず基本的な仕組みを説明します。インデックスは、検索対象となるカラムの値とそのデータが格納されている物理的な位置(ポインタ)のペアを効率的に管理する構造です。この構造により、データベース管理システムは検索条件に合致するデータを素早く特定できます。
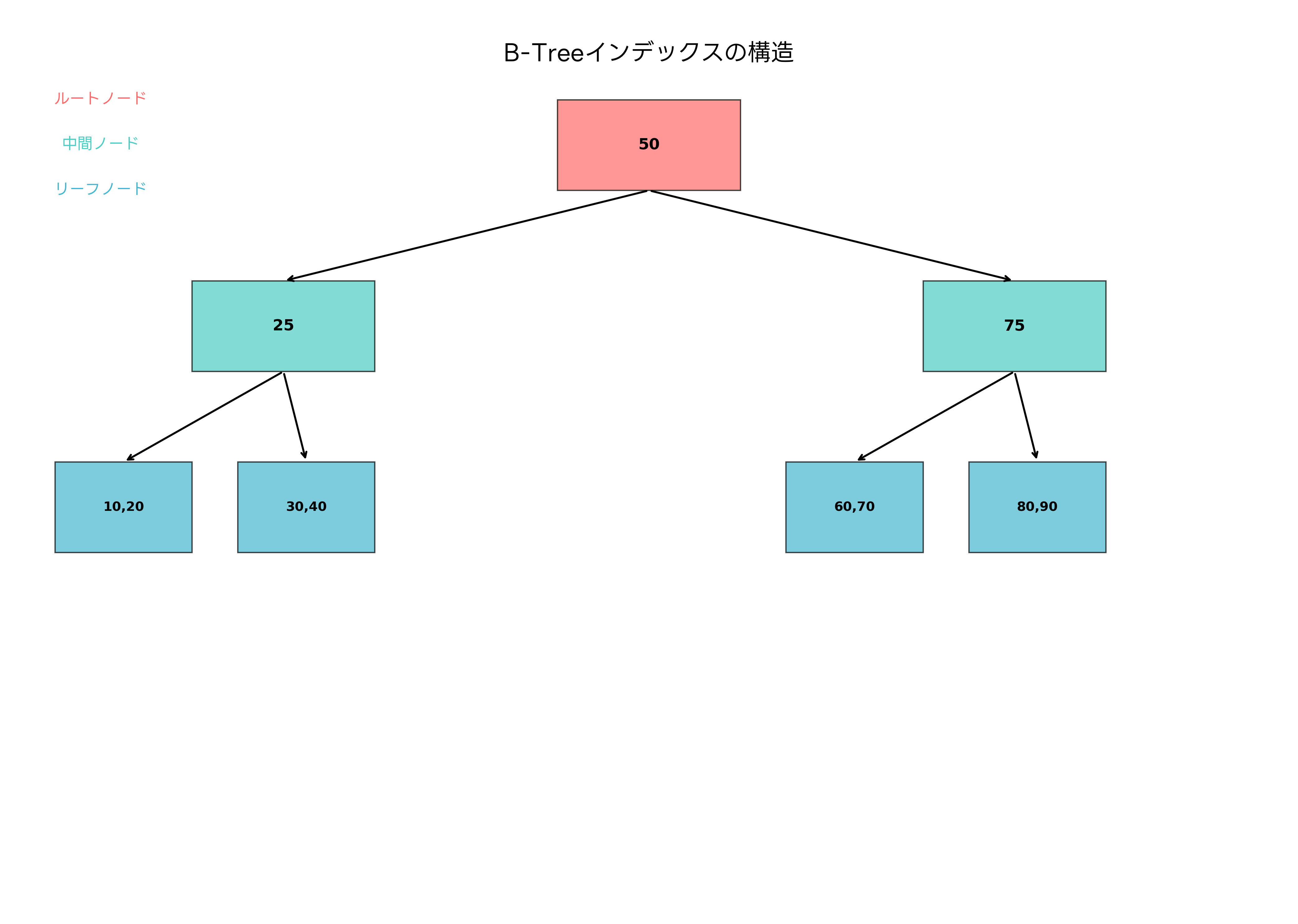
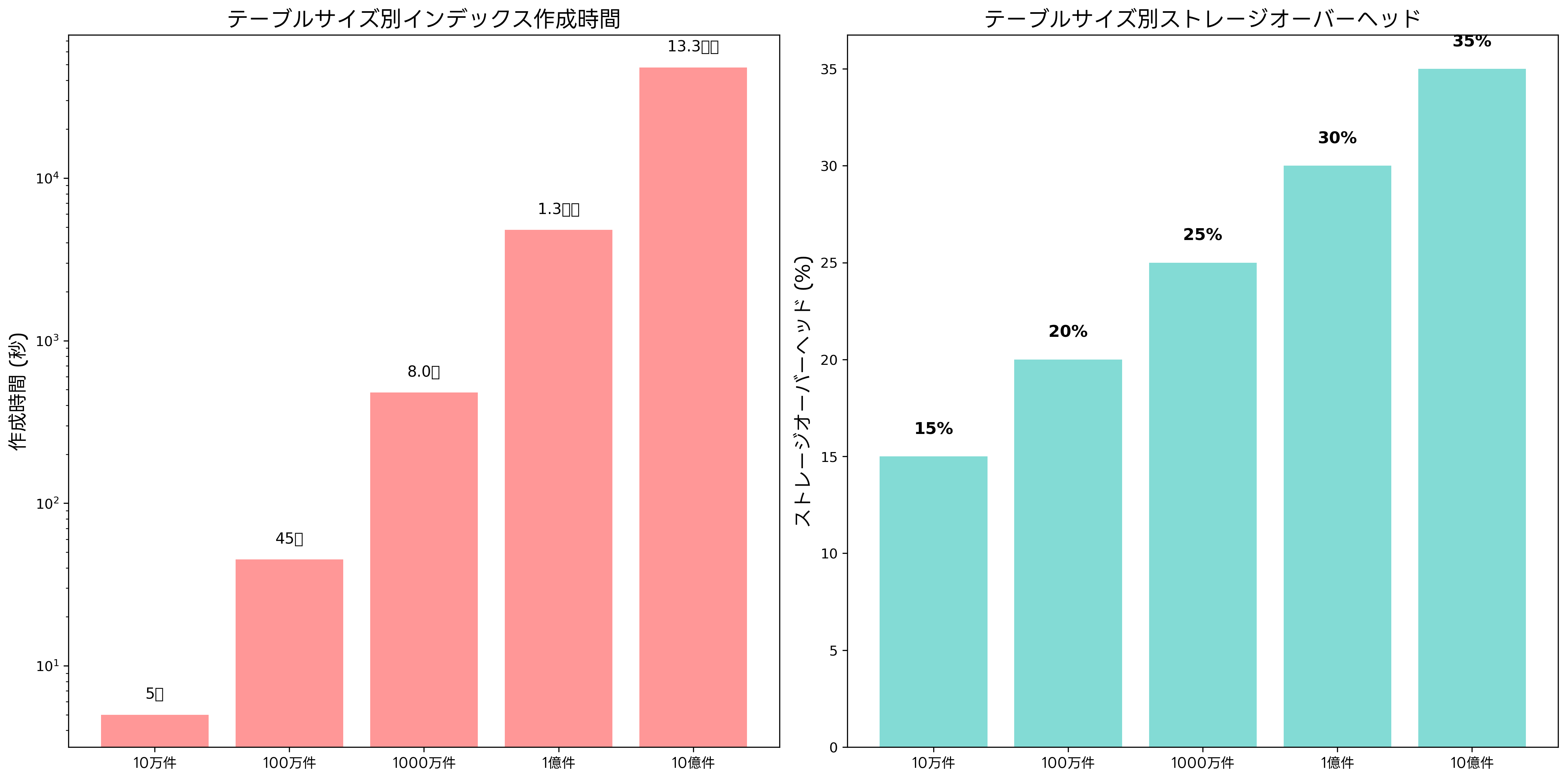
最も一般的なB-Treeインデックスでは、データが階層構造で整理されます。ルートノードから始まり、中間ノードを経てリーフノードに至る経路を辿ることで、目的のデータにアクセスします。この階層構造により、データ量が増加しても検索時間の増加を対数的に抑えることができます。例えば、1億件のデータであっても、わずか数十回の比較でデータを特定できます。
データベースシステムを効率的に運用するためには、高性能データベースサーバーの選択が重要です。また、インデックス設計を支援するデータベース設計ツールを活用することで、より効率的なシステム構築が可能になります。
インデックスの物理的な格納では、データページとは別にインデックスページが作成されます。これらのページは、高速SSDストレージに配置することで、さらなる性能向上を図ることができます。特に、頻繁にアクセスされるインデックスは、エンタープライズSSDに配置することで、レスポンス時間の短縮が期待できます。
インデックスの種類と特性
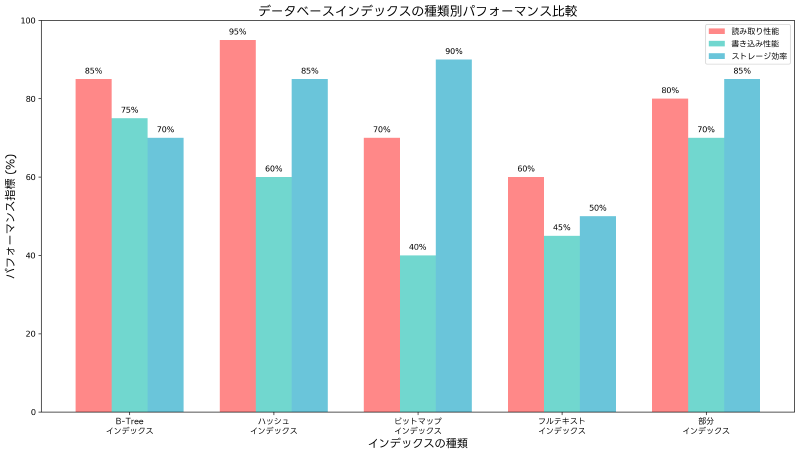
データベースシステムでは、用途に応じて様々な種類のインデックスが提供されています。それぞれに特徴があり、適切な場面で使い分けることが重要です。
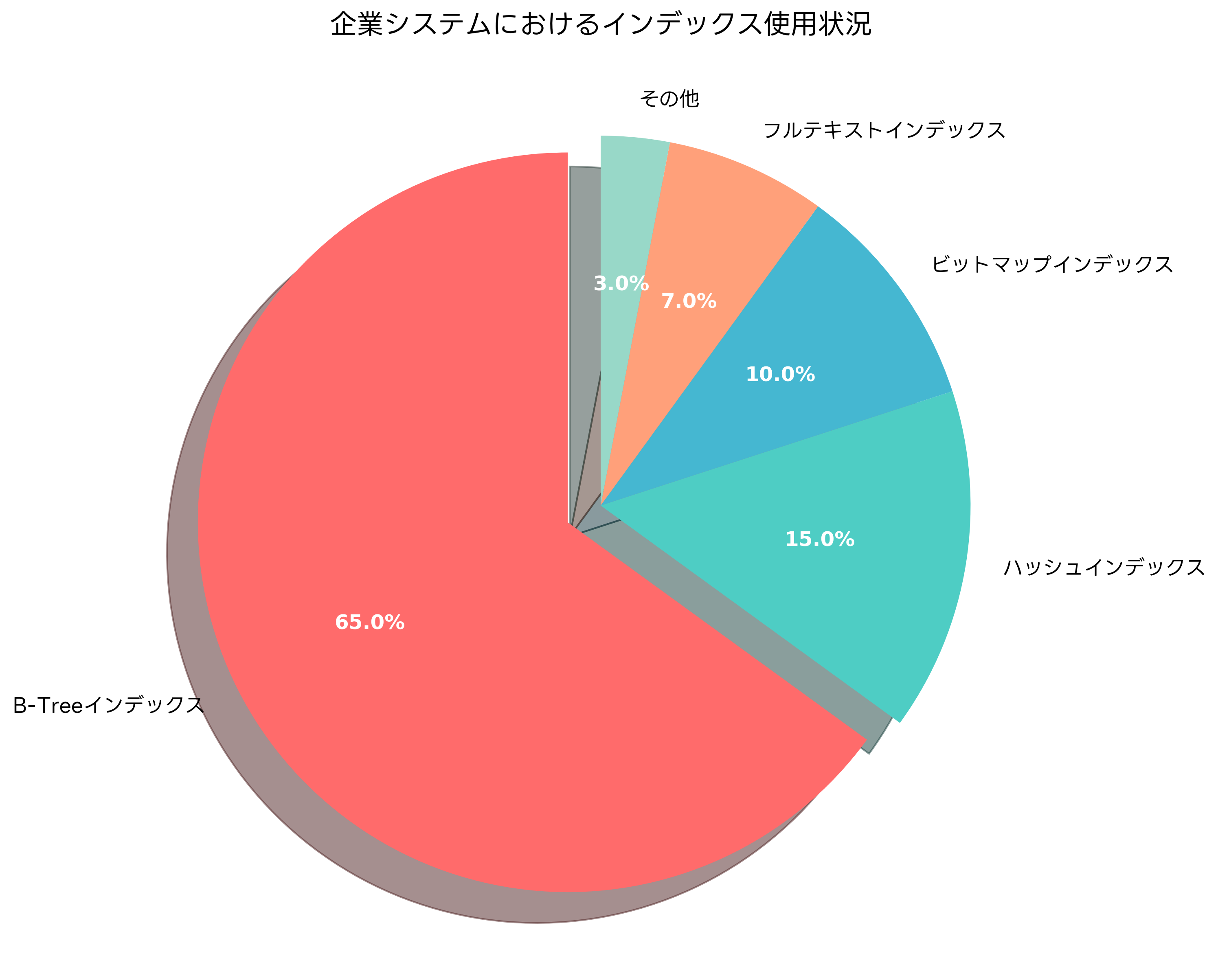
B-Treeインデックスは最も一般的なインデックス形式で、等価検索、範囲検索、ソート処理に優れた性能を発揮します。バランス木構造により、挿入・削除・検索のすべての操作で安定した性能を提供します。関係データベース管理システムのほとんどがB-Treeインデックスをデフォルトとして採用しており、データベース管理システムの選択時にもB-Treeの実装品質が重要な評価ポイントとなります。
ハッシュインデックスは、等価検索に特化した高速なインデックス形式です。ハッシュ関数を使用してキー値を直接インデックスエントリにマッピングするため、理論的にはO(1)の検索性能を実現できます。ただし、範囲検索やソート処理には適用できないという制約があります。メモリ内データベースや高速キャッシュシステムでよく使用されます。
ビットマップインデックスは、低カーディナリティ(取りうる値の種類が少ない)のカラムに適したインデックス形式です。各値に対してビットマップを作成し、複数条件の組み合わせ検索で高い性能を発揮します。データウェアハウスや分析系システムで重要な役割を果たし、ビジネスインテリジェンスツールとの連携により強力な分析機能を提供します。
フルテキストインデックスは、文書検索やテキスト検索に特化したインデックス形式です。自然言語処理技術を活用して、文書内の単語や句を効率的に検索できます。Webサイトの検索機能や文書管理システムで必須の機能であり、文書管理システムの導入時には重要な検討要素となります。
部分インデックスは、条件を満たすレコードのみを対象としたインデックスです。全体のデータ量に対して検索対象が限定的な場合に、ストレージ使用量と保守コストを削減しながら高い検索性能を維持できます。
インデックス設計の考慮事項とベストプラクティス
インデックス設計では、性能向上とリソース使用量のバランスを考慮する必要があります。インデックスは検索性能を向上させる一方で、ストレージ容量の消費と更新処理のオーバーヘッドが発生します。
カラムの選択では、検索条件として頻繁に使用されるカラムを優先してインデックス化します。WHERE句、JOIN句、ORDER BY句で使用されるカラムが主な対象となります。カーディナリティ(値の一意性)も重要な要素で、一般的に高カーディナリティのカラムの方がインデックスの効果が高くなります。データベースパフォーマンス監視ツールを使用して、実際のクエリパターンを分析し、最適なカラム選択を行うことが重要です。
複合インデックスでは、カラムの順序が性能に大きく影響します。選択性の高いカラムを先頭に配置し、検索パターンに応じて最適な順序を決定します。例えば、「地域」と「年齢」の複合インデックスでは、検索条件によって最適な順序が変わります。クエリ最適化ツールを活用することで、複雑な複合インデックスの設計を効率的に行えます。
インデックスのメンテナンスも重要な考慮事項です。データの挿入・更新・削除が頻繁に発生する環境では、インデックスの断片化が進み、性能が劣化する可能性があります。定期的な再構築やメンテナンス作業により、最適な状態を維持する必要があります。データベースメンテナンスツールを使用することで、自動化されたメンテナンス体制を構築できます。
ストレージ容量の管理も重要です。インデックスは元のテーブルサイズの20-50%程度の追加容量を必要とします。大規模なデータベースでは、この容量が無視できない規模になるため、高容量ストレージシステムの導入や容量計画が必要です。
実際の運用における課題と対策
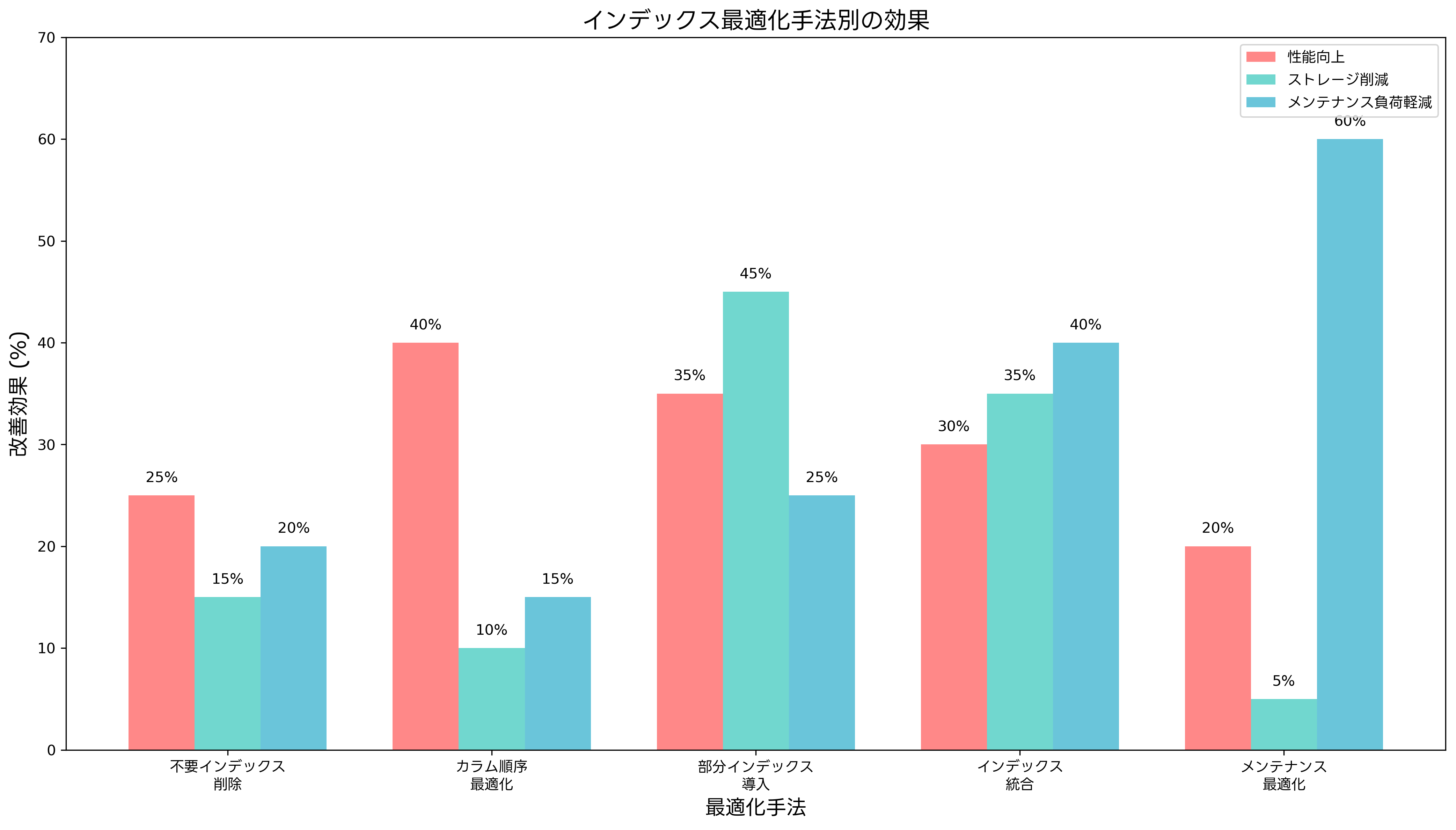
企業システムでインデックスを運用する際には、様々な課題が発生します。最も一般的な問題は、不適切なインデックス設計による性能劣化です。過剰なインデックス作成は、更新処理の性能を著しく低下させる可能性があります。
インデックスの利用状況を定期的に監視し、使用されていないインデックスを特定して削除することが重要です。多くのデータベース管理システムでは、インデックスの使用統計を提供しており、データベース監視ソフトウェアを活用することで詳細な分析が可能です。
クエリプランの分析も重要な作業です。実行計画を確認することで、インデックスが適切に使用されているかを判断できます。予期しないフルスキャンが発生している場合は、インデックス設計の見直しが必要です。SQL分析ツールを使用することで、効率的なクエリ分析が可能になります。
統計情報の更新も見落としがちな重要な作業です。データベースの統計情報が古くなると、オプティマイザが不適切な実行計画を選択し、インデックスが効果的に使用されない場合があります。自動統計更新機能を有効にするか、定期的な手動更新スケジュールを設定することが推奨されます。
並行処理環境では、インデックスのロック競合が性能に影響する場合があります。特に、更新処理が集中するシステムでは、インデックス設計時にロック粒度を考慮する必要があります。並行処理最適化ツールを活用することで、ロック競合の分析と対策が可能です。
インデックス最適化のテクニックと戦略
インデックスの性能を最大化するためには、様々な最適化テクニックを適用する必要があります。これらのテクニックを組み合わせることで、システム全体の性能を大幅に向上させることができます。
インデックスヒントの使用は、特定のクエリでオプティマイザの判断を補助する手法です。複雑なクエリでは、オプティマイザが最適でないインデックスを選択する場合があります。このような場合に、明示的にインデックスを指定することで性能を改善できます。ただし、ヒントの多用はメンテナンス性を低下させるため、慎重に使用する必要があります。
カバリングインデックスは、クエリで必要なすべての列をインデックスに含める手法です。これにより、インデックスだけでクエリを完結でき、テーブルへのアクセスを回避できます。特に、読み取り専用の分析クエリで大きな効果を発揮します。分析専用データベースでは、この手法が特に有効です。
パーティション化されたテーブルでは、ローカルインデックスとグローバルインデックスの選択が重要です。検索パターンとパーティション戦略を考慮して、最適なインデックス配置を決定します。データベースパーティショニングツールを使用することで、複雑なパーティション環境でのインデックス管理が容易になります。
インデックス圧縮技術の活用も重要です。特に、履歴データや参照頻度の低いデータでは、圧縮インデックスを使用することでストレージコストを削減できます。圧縮率とアクセス性能のトレードオフを考慮して適用する必要があります。
インメモリインデックスの活用により、さらなる性能向上が可能です。頻繁にアクセスされるインデックスをメモリに常駐させることで、ディスクI/Oを削減できます。高速メモリシステムの導入により、この手法の効果を最大化できます。
新技術とインデックスの進化
近年の技術革新により、インデックス技術も大きく進歩しています。人工知能と機械学習の活用により、自動インデックス推奨機能が実用化されています。これらの機能は、実際のワークロードを分析し、最適なインデックス設計を提案します。
AI搭載データベース最適化ツールを活用することで、経験豊富なデータベース管理者でなくても効率的なインデックス設計が可能になります。これらのツールは、継続的な学習により提案精度を向上させ、動的な環境変化にも対応できます。
コラムナーストレージとの組み合わせにより、分析系ワークロードでのインデックス性能が大幅に向上しています。従来の行指向ストレージでは実現困難だった高度な圧縮と並列処理が可能になり、コラムナーデータベースの導入により新たな可能性が開かれています。
クラウド環境では、自動スケーリング機能により、負荷に応じてインデックス処理能力を動的に調整できます。クラウドデータベースサービスを活用することで、運用負荷を大幅に削減しながら高い性能を維持できます。
応用情報技術者試験での出題傾向と対策
応用情報技術者試験では、インデックスに関する問題が午前・午後問題ともに出題されています。特に、データベース設計とSQL最適化の分野で重要な位置を占めています。
午前問題では、インデックスの基本概念、種類、特性に関する知識が問われます。B-Treeインデックスの構造、ハッシュインデックスの特徴、複合インデックスの設計原則などが出題されます。また、インデックスによる性能向上の仕組みや、更新処理への影響についても理解が必要です。
午後問題では、実際のシステム設計場面でのインデックス適用が問われます。与えられたテーブル構造とクエリパターンに対して、最適なインデックス設計を提案する問題や、性能問題の原因分析と対策を考える問題が出題されます。
試験対策としては、応用情報技術者試験データベース分野の参考書で理論的な知識を深めることが重要です。また、SQLパフォーマンステューニングの技術書を活用して実践的な知識を身につけることも効果的です。
実際のデータベースシステムでの経験があれば、自社システムのインデックス設計を分析し、改善提案を考える練習も有効です。データベース実習環境を構築して、様々なインデックス設計を実際に試すことで、理解を深めることができます。
パフォーマンスチューニングの実践
インデックスを活用したパフォーマンスチューニングには、体系的なアプローチが必要です。まず、現状の性能問題を正確に把握し、ボトルネックを特定することから始めます。
性能監視では、クエリの実行時間、I/O待機時間、CPU使用率、メモリ使用量などの指標を総合的に分析します。データベースパフォーマンス分析ツールを使用することで、詳細な性能データを収集し、問題の根本原因を特定できます。
実行計画の分析は、インデックスの効果を評価する重要な手法です。期待した実行計画と実際の実行計画を比較し、オプティマイザの判断が適切かを確認します。不適切な実行計画が選択されている場合は、統計情報の更新やインデックスヒントの使用を検討します。
負荷テストによる検証も重要です。本番環境に近い条件でテストを実施し、インデックス変更の効果を定量的に評価します。データベース負荷テストツールを活用することで、様々なシナリオでの性能評価が可能です。
まとめ
インデックスは、データベースシステムの性能を決定する重要な要素です。適切な設計と運用により、大幅な性能向上を実現できる一方で、不適切な使用は逆に性能を劣化させる可能性があります。応用情報技術者として、インデックスの原理と実践的な活用方法を理解することは必須です。
現代のビジネス環境では、データ量の急激な増加と処理速度への要求の高まりにより、インデックス技術の重要性がますます高まっています。人工知能や機械学習技術の進歩により、インデックス設計の自動化も進んでいますが、基本原理の理解と実践経験に基づく判断力は依然として重要です。
継続的な学習と実践により、変化する技術環境に対応できる能力を身につけることで、高性能なデータベースシステムの構築と運用に貢献できます。インデックス技術は今後も進化を続けるため、最新の動向を把握し、実際のプロジェクトで活用していくことが重要です。